

Part1: 十家公司的营业收入 (点击跳转)
Part2: 十家公司归属于上市公司股东的净利润 (点击跳转)
Part3: 十家公司的基本信息 (点击跳转)
Part4: 专用设备制造业概况 (点击跳转)
Part5: 代码 (点击跳转)
1.股票代码获取 (点击跳转)
2.获取深交所表格 (点击跳转)
3.表格分析以及pdf下载 (点击跳转)
4.年报基本信息提取 (点击跳转)
5.营业收入与净利润提取 (点击跳转)
6.画图 (点击跳转)
Part6: 心得 (点击跳转)
由于十家公司的营业收入相差百倍,绘制在一张图上会导致营业收入较小的公司无法体现出具体趋势,因此十家公司的营业收入将分开绘制,part2的归属于上市公司股东的净利润同理。









营业收入解读:
从这十家公司的营业收入可看出,徐工机械、哈工智能以及石化机械这三家公司的营业收入有涨有跌,但总体上是上涨趋势。山推股份在近十年先是出现了一个大幅度的跌幅,但是在近年来开始回升至十年前的水平。中兵红箭、中联重科、柳工以及恒立实业这四家公司前些年虽有上涨,但近些年来出现下跌趋势。甘化科工表现较差,近十年的营业收入一直处于波动态势,并没有出现上涨的趋势。京山轻机表现最好,营业收入连续十年都呈现上涨趋势。
回到目录
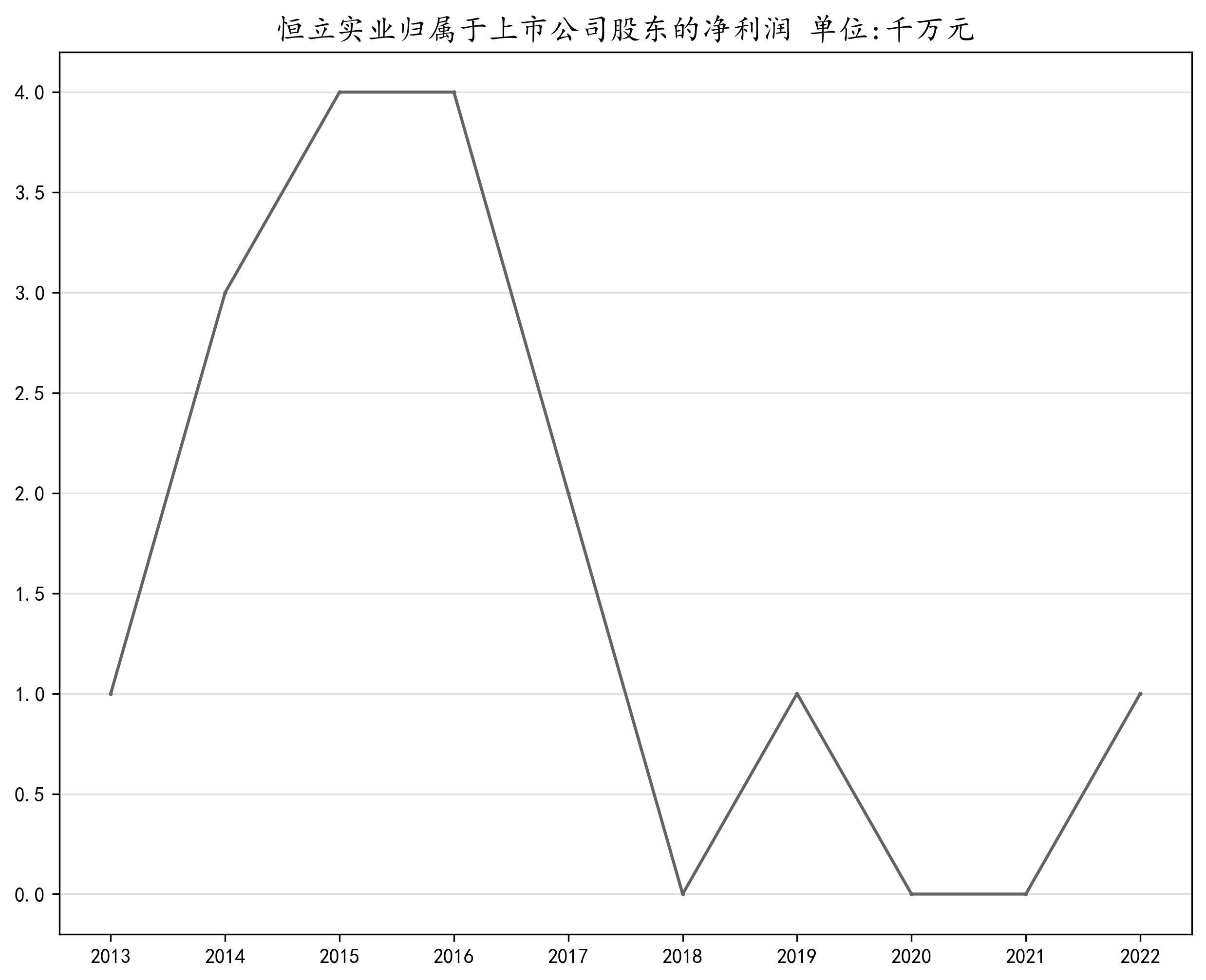



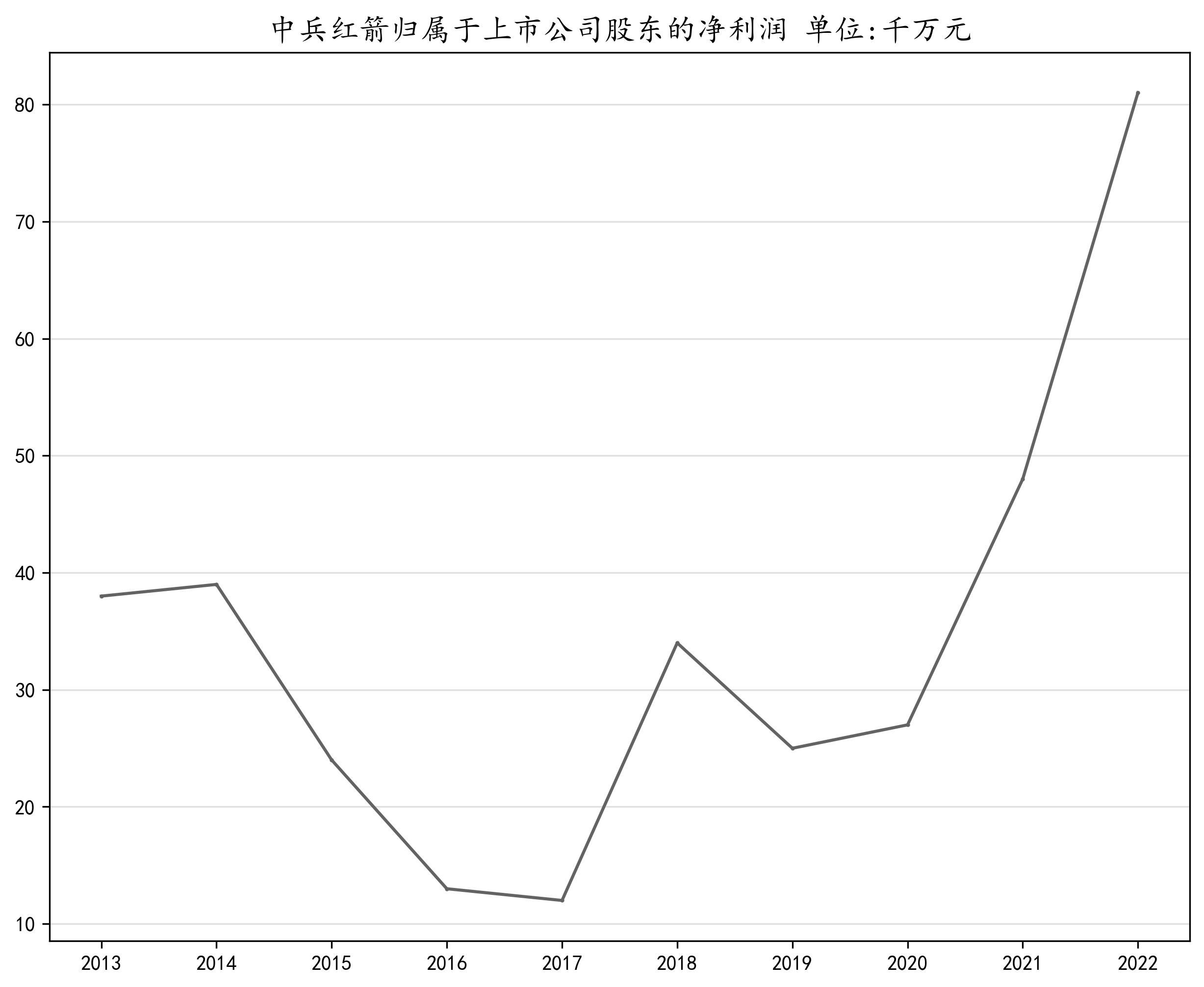





归属于上市公司股东的净利润解读:
归属于上市公司股东的净利润是子公司的净利润。由于母公司拥有控股权,所以子公司的净利润就要归属给母公司,在财务报表上这部分净利润归母公司的股东所有。石化机械和恒立实业在前些年有较大的波动,先是大幅上涨随后开始大幅下降,最后回归到正常的波动水平。而甘化科工和京山轻机则是在前些年处于正常的波动情况,在近几年开始大幅度波动。哈工智能、中兵红箭以及山推股份在近两年出现大幅度上涨的趋势,哈工智能与中兵红箭在前些年都有一些小幅度的波动,而山推股份在2014年至2016年出现了较大幅度的波动。徐工机械、中联重科和柳工都是先出现小幅度下降然后开始大幅度上涨,近两年又开始大幅度的下跌。
回到目录从最新的年报中提取出了公司名称、公司办公地址、公司网址、董事会秘书姓名、董事会秘书电话以及董事会秘书电子信箱。具体内容如下图和下表。

| 公司名称 | 公司办公地址 | 公司网址 | 董事会秘书姓名 | 董事会秘书电话 | 董事会秘书电子信箱 |
|---|---|---|---|---|---|
| 中联重科 | 湖南省长沙市银盆南路361号 | http://www.zoomlion.com/ | 杨笃志 | 0731-85650157 | 157@zoomlion.com |
| 徐工机械 | 江苏省徐州经济技术开发区驮蓝山路26号 | http://xgjx.xcmg.com | 费广胜 | 0516-87565621 | zqb@xcmg.com |
| 中兵红箭 | 河南省南阳市仲景北路1669号中南钻石有限公司院内 | http://zbhj.norincogroup.com.cn | 赵德良 | 0377-83880269 | zhaodeliang228@yeah.net |
| 柳工 | 广西壮族自治区柳州市柳太路1号 | http://www.liugong.com | 黄华琳先生 | (0772)3886510 | stock@liugong.com |
| 甘化科工 | 广东省江门市甘化路62号 | www.gdganhua.com | 陈波 | (0750)3277650、3277651 | cb@gdganhua.com |
| 哈工智能 | 上海市闵行区泰虹路456号11号楼3楼 | www.hgzn.com | 王妍 | 021-51782928 | 000584@hgzn.com |
| 恒立实业 | 湖南省岳阳市经济开发区岳阳大道东279号四化大厦第7楼 | http://www.hlsyfzjt.com | 李滔 | 0730-8245282 | yueyuan421@163.com |
| 山推股份 | 山东省济宁市高新区327国道58号 | http://www.shantui.com | 袁青 | 0537-2909616 | yuanqing@shantui.com |
| 京山轻机 | 湖北省京山市经济开发区轻机工业园 | http://www.jsmachine.com.cn | 周家敏 | 027-83320271 | jiamin.zhou@jsmachine.com.cn |
| 石化机械 | 湖北省武汉市东湖新技术开发区光谷大道77号金融港A2座12层 | http://sofe.sinopec.com | 周秀峰 | 027-63496803 | security.oset@sinopec.com |
专用设备制造业是为特定领域提供定制化的机械设备和工具的制造业,如汽车制造、航空航天、能源、医疗保健、食品加工等。该行业有着巨大的市场需求与发展前景,为特定行业提供了工业生产的发展。
在2022年1-11月,专用设备制造业企业利润总额同比增速为3.2%,较1-10月上升2.9个百分点。受全球大宗商品价格高位回落、三重压力对国内工业经济产生的持续冲击等因素影响,这些因素使得PPI增速放缓,对于制造业来说,大宗原材料的成本压力得到减缓,有利于改善制造业的经营状况。
近段时间,广东、江苏、山东、上海等地出台推动制造业高质量发展的新举措,加速向知识化、数智化、低碳化、服务化方向发展。我国制造业规模已位居世界第一位,但仍然需要进行转型升级,主要从综合成本优势的制造能力、产业生态的产业链掌控能力、科技创新的产业引领能力以及关键要素的价值获取能力这四个方面进行能力的加强,在兼顾传统产业竞争力、促进高科技产业做强做优以及培育壮大战略新兴产业和前瞻布局未来产业。
回到目录本部分内容为从证监会2021年3季度上市公司行业分类中获取我自己要提取的专用设备制造业的前十家公司的名称与代码。在获取结果时我发现十家公司全为在深交所上市的公司,所以本报告中所有代码将以深交所出发对文档进行获取与处理。
#股票代码与名称获取以及初步分析
import fitz
import os
import pandas as pd
import re
os.chdir(r"E:\2023spring\金融数据获取与处理\大作业")
doc = fitz.open('industry.PDF')
whole_text = ''
for page in doc:
whole_text += page.get_text()
s = whole_text.find('专用设备制造业')
e = whole_text.find('汽车制造业')
subtext = whole_text[s+8:e]
lines = subtext.replace('\n',' ') #将换行符改为空格
list1 = lines.split(' ') #以空格为分割条件,将str转换为list
list = list1[0:20]
names = []
codes = []
for i in list:
if list.index(i)%2 == 0:
codes.append(i)
else:
names.append(i)
code_name = pd.DataFrame({'code':codes, 'name':names}).set_index('code')
code_name_sz = []
code_name_sh =[]
for code in codes:
if code[0:2] == '00':
code_name_sz.append(code_name.loc[code])
else:
code_name_sh.append(code_name.loc[code])
code_name_sz = pd.DataFrame(code_name_sz).reset_index()
code_name_sh = pd.DataFrame(code_name_sh).reset_index()
codes_sz = code_name_sz.index.tolist()
name_sz = code_name_sz.name.tolist()
 回到目录
回到目录
本部分为从深交所网址中提取表格并存入html网页中。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import os
os.chdir(r"E:\2023spring\金融数据获取与处理\大作业\深交所")
driver = webdriver.Chrome()
def get_table_szse(name):
driver.get("http://www.szse.cn/disclosure/listed/fixed/index.html")
driver.maximize_window()
driver.implicitly_wait(3)
driver.find_element(By.ID, "input_code").click()
driver.find_element(By.ID, "input_code").send_keys(name)
driver.find_element(By.ID, "input_code").send_keys(Keys.DOWN)
driver.find_element(By.ID, "input_code").send_keys(Keys.ENTER)
driver.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
driver.find_element(By.LINK_TEXT, "年度报告").click()
driver.find_element(By.CSS_SELECTOR, ".input-left").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 .calendar-year span").click()
driver.find_element(By.CSS_SELECTOR, ".active li:nth-child(114)").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 tr:nth-child(1) > .available:nth-child(3) > .tdcontainer").click()
driver.find_element(By.CSS_SELECTOR, " .tdcontainer").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-2 tr:nth-child(2) > .weekend:nth-child(1) > .tdcontainer").click()
driver.find_element(By.ID, "query-btn").click()
html = driver.find_element(By.ID, 'disclosure-table')
time.sleep(3)
innerHTML = html.get_attribute('innerHTML')
df = open(name+'.html','w',encoding='gbk')
df.write(innerHTML)
df.close()
driver.refresh()
for name in name_sz:
get_table_szse(name)
time.sleep(1)
driver.quit()
 回到目录
回到目录
本部分为解析上一部分获得的表格,将解析结果保存到excel中并下载pdf。
import re
import pandas as pd
import requests
import os
os.chdir(r"E:\2023spring\金融数据获取与处理\大作业\深交所")
def Readhtml(filename):
with open(filename+'.html', encoding='gbk') as f:
html = f.read()
return html
class DisclosureTable():
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'公告时间': times,
'href': [prefix_href + aht[1] for aht in ahts]
})
self.df_data = df
return(df)
def Loadpdf(df):
d = []
for index, row in df.iterrows():
a = row[2] #公告标题这一行
n = re.search('摘要|取消|更新前|12', a)
if n != None:
d.append(index)
dfnew = df.drop(d).reset_index(drop = True)
dfnew.to_csv(name + '.csv',encoding = 'gbk')
os.makedirs(name, exist_ok = True)
os.chdir(name)
#
d1 = {}
for index, row in dfnew.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
key = key.strip('公司').strip('(更新后)').strip('(更新后)').strip('全文')
with open (key + ".pdf", "wb") as code:
code.write(f.content)
os.chdir('../')
for index,row in code_name_sz.iterrows():
name = row[1].replace('*','')
html = Readhtml(name)
dt = DisclosureTable(html)
df = dt.get_data()
Loadpdf(df)
driver.quit()


 回到目录
回到目录
本部分从最新的年报中获取公司办公地址、公司网址、董事会秘书姓名、董事会秘书电话以及董事会秘书电子信箱。
import pandas as pd
import fitz
import os
import csv
os.chdir(r"E:\2023spring\金融数据获取与处理\大作业\深交所")
def ana(name):
doc = fitz.open('2022年年度报告.PDF')
text = ''
i = 0
for page in doc:
if i <= 20:
text += page.get_text()
i += 1
#
s = text.find('一、公司信息')
e = text.find('二、联系人')
subtext1 = text[s:e].replace(' ','')
#
s1 = subtext1.find('办公地址')
e1 = subtext1.find('办公地址的')
s2 = subtext1.find('公司网址')
e2 = subtext1.find('电子信箱')
place = subtext1[s1:e1].replace('办公地址' or ' ', '')
website = subtext1[s2:e2].replace('公司网址' or ' ', '')
#
s = text.find('二、联系人')
e = text.find('三、信息披露')
subtext2 = text[s:e].replace(' ','')
s3 = subtext2.find('姓名')
e3 = subtext2.find('联系地址')
s4 = subtext2.find('电话')
e4 = subtext2.find('传真')
s5 = subtext2.find('电子信箱')
board = subtext2[s3:e3]
board = board.split('\n')
board = board[1]
tel = subtext2[s4:e4]
tel = tel.split('\n')
tel = tel[1]
email = subtext2[s5:]
email = email.split('\n')
email = email[1]
#
list = [name, place, website, board, tel, email]
os.chdir(r"E:\2023spring\金融数据获取与处理\大作业\深交所")
with open('公司基本信息.csv', 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(list)
with open('公司基本信息.csv', 'w', encoding='gbk', newline='') as f:
a = csv.writer(f)
a.writerow(['公司名称','公司办公地址', '公司网址', '董事会秘书姓名', '董事会秘书电话', '董事会秘书电子信箱'])
for name in name_sz:
os.chdir(name)
ana(name)
回到目录
本部分为从年报中提取营业收入与归属于上市公司股东的净利润。一开始我试图绕开正则表达式来进行提取,最后发现提取出的信息会有很多错误,把错误代码放出来也算是一个错误示范了。这部分最后还是运用了老师的代码,但是依然会有个别数据出现错误,所以运用手动更改的方式进行处理。
'''
### 此代码运行会出现错误
import pandas as pd
import fitz
import os
import csv
os.chdir(r"E:\2023spring\金融数据获取与处理\大作业\深交所")
def rev(name):
revs = [name]
for time in range(2013,2023):
time = str(time)
doc = fitz.open(time + '年年度报告.pdf')
text = ''
i = 0
for page in doc:
if i <= 20:
text += page.get_text()
i += 1
start = text.find('主要会计数据')
end = text.find('境内外会计')
subtext1 = text[start:end].replace(' ','')
s1 = subtext1.find('营业收入')
e1 = subtext1.find('归属于上市')
subtext1 = subtext1[s1:e1]
subtext1 = subtext1.split('\n')
rev = subtext1[1]
revs.append(rev)
os.chdir(r"E:\2023spring\金融数据获取与处理\大作业\深交所")
with open('营业收入.csv', 'a', encoding='gbk', newline='') as f:
a = csv.writer(f)
a.writerow(revs)
with open('营业收入.csv', 'w', encoding='gbk', newline='') as f:
a = csv.writer(f)
a.writerow(['name','2013','2014','2015','2016','2017','2018','2019','2020','2021','2022'])
for name in name_sz:
os.chdir(name)
rev(name)
name_sz.remove('哈工智能')
'''
#以下代码可以运行
import re
import os
import fitz
import csv
os.chdir(r"E:\2023spring\金融数据获取与处理\大作业\深交所")
def get_subtxt(doc, bounds=('主要会计数据和财务指标','总资产')):
# 默认设置为首位页码
start_pageno = 0
end_pageno = len(doc) - 1
#
lb, ub = bounds # lb: lower bound(下界) up: upper bound(上界)
# 获取左界页码
for n in range(len(doc)):
page = doc[n]; txt = page.get_text()
if lb in txt:
start_pageno = n; break
# 获取右界页码
for n in range(start_pageno, len(doc)):
if ub in doc[n].get_text():
end_pageno = n; break
# 获取小范围内字符串
txt = ''
for n in range(start_pageno, end_pageno+1):
page = doc[n]
txt += page.get_text()
return(txt)
def get_th_span(txt):
years = '(20\d\d|199\d)\s*年末?' #|199\d
s = f'{years}\s*{years}.*?{years}'
p = re.compile(s, re.DOTALL)
matchobj = p.search(txt)
#
end = matchobj.end()
year1 = matchobj.group(1)
year2 = matchobj.group(2)
year3 = matchobj.group(3)
#
flag = (int(year1) - int(year2) == 1) and (int(year2) - int(year3) == 1)
#
while (not flag):
matchobj = p.search(txt[end:])
end = matchobj.end()
year1 = matchobj.group(1)
year2 = matchobj.group(2)
year3 = matchobj.group(3)
flag = (int(year1) - int(year2) == 1)
flag = flag and (int(year2) - int(year3) == 1)
#
return(matchobj.span())
def get_bounds(txt):
th_span_1st = get_th_span(txt)
end = th_span_1st[1]
th_span_2nd = get_th_span(txt[end:])
th_span_2nd = (end + th_span_2nd[0], end + th_span_2nd[1])
#
s = th_span_1st[1]
e = th_span_2nd[0]-1
#
while (txt[e] not in '0123456789'):
e = e-1
return(s,e)
def get_keywords(txt):
p = re.compile(r'\d+\s*?\n\s*?([\u2E80-\u9FFF]+)')
keywords = p.findall(txt)
keywords.insert(0,'营业收入')
return(keywords)
def parse_key_fin_data(subtext , keywords):
ss = []
s = 0
for kw in keywords:
n = subtext.find(kw,s)
ss.append(n)
s = n + len(kw)
ss.append(len(subtext))
data = []
#
p = re.compile('\D+(?:\s+\D*)?(?: (.*) |\(.*\))?')
p2 = re.compile('\s')
for n in range(len(ss)-1):
s = ss[n]
e = ss[n+1]
line = subtext[s:e]
# 获取可能换行的账户名称
matchobj = p.search(line)
account_name = p2.sub('', matchobj.group())
# 获取三年数据
amnts = line[matchobj.end():].split()
# 加上账户名称
amnts.insert(0, account_name)
# 追加到总数据
data.append(amnts)
return data
with open('营业收入.csv', 'w', encoding='gbk', newline='') as f:
a = csv.writer(f)
a.writerow(['公司名称','2013', '2014', '2015', '2016', '2017','2018','2019','2020','2021','2022'])
with open('归属于上市公司股东的净利润.csv', 'w', encoding='gbk', newline='') as f:
a = csv.writer(f)
a.writerow(['公司名称','2013', '2014', '2015', '2016', '2017','2018','2019','2020','2021','2022'])
name_sz.remove('哈工智能') # 由于哈工智能是十个企业中唯一一个上市未满十年的企业,所以单独处理哈工智能
name_sz.remove('京山轻机') #京山轻机在2021年读取错误,所以数据手动添加至excel
name_sz.remove('柳工') #柳工在2021、2022年读取错误
for name in name_sz:
os.chdir(name)
total_rev = [name]
total_profit = [name]
for year in range(2013,2023):
year = str(year)
filename = year + '年年度报告.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
span = get_bounds(txt)
subtxt = txt[span[0]:span[1]]
keywords = get_keywords(subtxt)
data = parse_key_fin_data(subtxt, keywords)
rev = data[0][1]
profit = data[1][1]
total_rev.append(rev)
total_profit.append(profit)
os.chdir('../')
with open('营业收入.csv', 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(total_rev)
with open('归属于上市公司股东的净利润.csv', 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(total_profit)
os.chdir('哈工智能')
total_rev = ['哈工智能',' ',' ',' ',' ']
total_profit = ['哈工智能',' ',' ',' ',' ']
for year in range(2017,2023):
year = str(year)
filename = year + '年年度报告.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
span = get_bounds(txt)
subtxt = txt[span[0]:span[1]]
keywords = get_keywords(subtxt)
data = parse_key_fin_data(subtxt, keywords)
rev = data[0][1]
profit = data[1][1]
total_rev.append(rev)
total_profit.append(profit)
os.chdir('../')
with open('营业收入.csv', 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(total_rev)
with open('归属于上市公司股东的净利润.csv', 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(total_profit)
os.chdir('京山轻机')
total_rev = ['京山轻机']
total_profit = ['京山轻机']
for year in range(2013,2021):
year = str(year)
filename = year + '年年度报告.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
span = get_bounds(txt)
subtxt = txt[span[0]:span[1]]
keywords = get_keywords(subtxt)
data = parse_key_fin_data(subtxt, keywords)
rev = data[0][1]
profit = data[1][1]
total_rev.append(rev)
total_profit.append(profit)
total_rev.append(' ')
total_profit.append(' ')
filename = '2022年年度报告.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc).replace(' ','')
span = get_bounds(txt)
subtxt = txt[span[0]:span[1]]
keywords = get_keywords(subtxt)
data = parse_key_fin_data(subtxt, keywords)
rev = data[0][1]
profit = data[1][1]
total_rev.append(rev)
total_profit.append(profit)
os.chdir('../')
with open('营业收入.csv', 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(total_rev)
with open('归属于上市公司股东的净利润.csv', 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(total_profit)
os.chdir('柳工')
total_rev = ['柳工']
total_profit = ['柳工']
for year in range(2013,2021):
year = str(year)
filename = year + '年年度报告.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
span = get_bounds(txt)
subtxt = txt[span[0]:span[1]]
keywords = get_keywords(subtxt)
data = parse_key_fin_data(subtxt, keywords)
rev = data[0][1]
profit = data[1][1]
total_rev.append(rev)
total_profit.append(profit)
os.chdir('../')
with open('营业收入.csv', 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(total_rev)
with open('归属于上市公司股东的净利润.csv', 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(total_profit)

 回到目录
回到目录
本部分为对十年的营业收入以及归属于上市公司股东的净利润进行绘图。本来是想要将十家公司十年的数据都绘制在同一张图上,但是发现这十家企业的数据最大相差的有八百倍,放在同一张图表上显然不合适,所以在此采取了分开绘制的方式进行画图。
## 营业收入画图
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif']=['KaiTi']
mpl.rcParams['axes.unicode_minus']=False
import os
os.chdir(r"E:\2023spring\金融数据获取与处理\大作业\深交所")
df = pd.read_csv('营业收入.csv', encoding='gbk', index_col=0).T
x = df.index.to_list()
y1 = df['中联重科'].astype(float)//10000000
y1 = y1.to_list()
y2 = df['徐工机械'].astype(float)//10000000
y2 = y2.to_list()
y3 = df['中兵红箭'].astype(float)//10000000
y3 = y3.to_list()
y4 = df['柳工'].astype(float)//10000000
y4 = y4.to_list()
y5 = df['甘化科工'].astype(float)//10000000
y5 = y5.to_list()
y6 = df['哈工智能'].astype(float)//10000000
y6 = y6.to_list()
y7 = df['恒立实业'].astype(float)//10000000
y7 = y7.to_list()
y8 = df['山推股份'].astype(float)//10000000
y8 = y8.to_list()
y9 = df['京山轻机'].astype(float)//10000000
y9 = y9.to_list()
y10 = df['石化机械'].astype(float)//10000000
y10 = y10.to_list()
def pic(y, name):
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.figure(figsize=(10,8))
plt.plot(x, y, marker='o', markersize=1, color='#5B9BD5')
plt.grid(axis='y',color='#E0E0E0')
plt.title(name + '营业收入 单位:千万元', fontsize=15)
plt.savefig(name + '营业收入.png', dpi=300, bbox_inches ='tight')
plt.show()
pic(y1, '中联重科')
pic(y2, '徐工机械')
pic(y3, '中兵红箭')
pic(y4, '柳工')
pic(y5, '甘化科工')
pic(y6, '哈工智能')
pic(y7, '恒立实业')
pic(y8, '山推股份')
pic(y9, '京山轻机')
pic(y10, '石化机械')
#对比图绘制
plt.rcParams['font.sans-serif'] = ['KaiTi']
df.plot(kind='bar',figsize=(20,8))
plt.title('十家公司营业收入对比图', fontsize=20)
plt.legend(fontsize=15,framealpha=0.5,loc="upper left")
plt.savefig('十家公司营业收入对比图', dpi=300, bbox_inches ='tight')
plt.show()
## 归属于上市公司股东的净利润画图
import pandas as pd
from pylab import mpl
mpl.rcParams['font.sans-serif']=['KaiTi']
mpl.rcParams['axes.unicode_minus']=False
import os
os.chdir(r"E:\2023spring\金融数据获取与处理\大作业\深交所")
df = pd.read_csv('归属于上市公司股东的净利润.csv', encoding='gbk', index_col=0).T
x = df.index.to_list()
y1 = df['中联重科'].astype(float)//10000000
y1 = y1.to_list()
y2 = df['徐工机械'].astype(float)//10000000
y2 = y2.to_list()
y3 = df['中兵红箭'].astype(float)//10000000
y3 = y3.to_list()
y4 = df['柳工'].astype(float)//10000000
y4 = y4.to_list()
y5 = df['甘化科工'].astype(float)//10000000
y5 = y5.to_list()
y6 = df['哈工智能'].astype(float)//10000000
y6 = y6.to_list()
y7 = df['恒立实业'].astype(float)//10000000
y7 = y7.to_list()
y8 = df['山推股份'].astype(float)//10000000
y8 = y8.to_list()
y9 = df['京山轻机'].astype(float)//10000000
y9 = y9.to_list()
y10 = df['石化机械'].astype(float)//10000000
y10 = y10.to_list()
def pic(y, name):
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.figure(figsize=(10,8))
plt.plot(x, y, marker='o', markersize=1, color='#636363')
plt.grid(axis='y',color='#E0E0E0')
plt.title(name + '归属于上市公司股东的净利润 单位:千万元', fontsize=15)
plt.savefig(name + '归属于上市公司股东的净利润.png', dpi=300, bbox_inches ='tight')
plt.show()
pic(y1, '中联重科')
pic(y2, '徐工机械')
pic(y3, '中兵红箭')
pic(y4, '柳工')
pic(y5, '甘化科工')
pic(y6, '哈工智能')
pic(y7, '恒立实业')
pic(y8, '山推股份')
pic(y9, '京山轻机')
pic(y10, '石化机械')
#对比图绘制
plt.rcParams['font.sans-serif'] = ['KaiTi']
df.plot(kind='bar',figsize=(20,8))
plt.title('十家公司归属于上市公司股东的净利润对比图', fontsize=20)
plt.legend(fontsize=15,framealpha=0.5,loc="upper left")
plt.savefig('十家公司归属于上市公司股东的净利润对比图', dpi=300, bbox_inches ='tight')
plt.show()
回到目录
在金融数据获取与处理这门课上,我第一次对爬虫以及数据分析有了初步的了解与概况。这是我第一次运用制作网页的方式来完成大作业,也是我第一次运用爬虫和pdf解析,很新鲜也很折磨。在此要感谢吴老师的指导以及前几届学长学姐,这一个大作业写了有大半个月,这半个多月以来经常打开老师的网址浏览学长学姐的代码,确实也给我带来了很多启发与灵感。万事开头难,一开始着手这个报告时没有什么头绪,我就开始阅读上一届同学的报告,然后开始进行规划。我将这次大作业分成了6个部分,分别为股票代码获取、获取深交所表格、表格分析以及pdf下载、公司基本信息提取、营业收入与净利润的提取以及画图这几部分。有了一个具体规划后,庞大的命题就变成细小的问题,我就紧跟着规划来一步一步填充自己的整个大纲。在写这个大作业时,我觉得思路很重要,没有思路代码就无从下手,我也从老师和学长学姐那里学到了很多思路,比如说如何爬取深交所的表格以及如何下载pdf等。虽然说我完成了这个大作业,但是我依然觉得自己有不足的地方,正则表达式运用得并不熟练,以及提取的数据并不是那么的准确。希望在未来我能够进一步改善这些代码,做到更好。
回到目录