浏览器界面:
运行结果: list.csv
import fitz
import re
import pandas as pd
import numpy as np
import os
import time
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import matplotlib.pyplot as plt
os.chdir('/Users/leohuang/Desktop/学习/计算机/python/期末报告')
from parse_cninfo_table import *
#Step1 提取对应行业股票代码
pdf1 = fitz.open('上市公司行业分类.pdf')
text = ''
for page in pdf1:
text += page.get_text()
p1 = re.compile('\n65\n(.*?)\n66', re.DOTALL)
ext_ind = re.findall(p1, text)
p2 = re.compile('.*?\n(\d{6})\n.*?')
code = re.findall(p2, text_ind[0])
获取软件和信息技术服务业上市公司股票代码,读取pdf后利用正则表达式取行业代码位于65和66之间的所有内容,再提取其中全部的6位数字,结果如下图所示:
browser = webdriver.Chrome() #使用Chrome浏览器
browser.maximize_window()
def get_cninfo(code): #爬取巨潮网年报信息
browser.get('http://www.cninfo.com.cn/new/commonUrl/pageOfSearch?url=disclosure/list/search&checkedCategory=category_ndbg_szsh')
browser.find_element(By.CSS_SELECTOR, ".el-autocomplete > .el-input--medium > .el-input__inner").send_keys(code)
time.sleep(1) #注意为联网加载留出时间
browser.find_element(By.CSS_SELECTOR, ".query-btn").send_keys(Keys.DOWN)
browser.find_element(By.CSS_SELECTOR, ".query-btn").send_keys(Keys.ENTER)
time.sleep(2)
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").click()
time.sleep(0.5)
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").clear()
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").send_keys("2013-01-01")
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").send_keys(Keys.ENTER)
time.sleep(0.1)
browser.find_element(By.CSS_SELECTOR, ".query-btn").click()
time.sleep(2)
element = browser.find_element(By.CLASS_NAME, 'el-table__body')
innerHTML = element.get_attribute('innerHTML')
return innerHTML
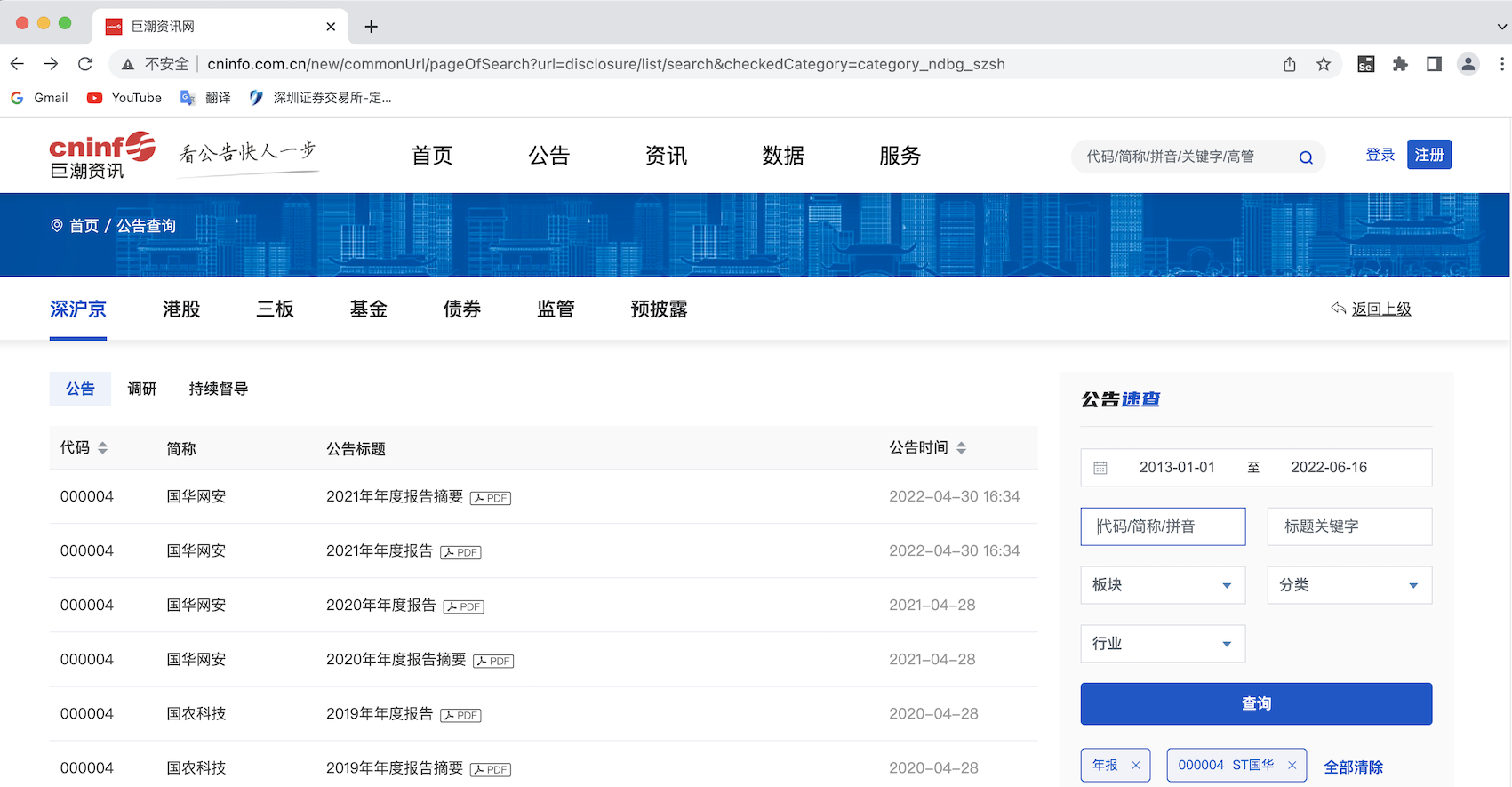
使用WebDriver打开浏览器后全屏以防止自动操作出错,本次期末作业我选取的数据源为巨潮网,其定期报告界面的筛选可以通过Selenium IDE工具对操作进行编码,
日期输入框可以人工输入,避免了上交所官网定期报告界面点选日期操作出错的问题。另一方面,巨潮网集合了各个交易所上市的股票信息,这对批量下载数据提供了便利,是相关工作者的优质信息渠道。
登入网站后,此处我使用Selenium IDE提供的方法构建网页代码获取函数,对输入信息对象进行定位,在执行回车、单击搜索键等操作时应注意设置时间间隔以保证每一个动作执行完成后再进入下一步,
成功获取页面信息后返回页面innerHTML。
def html_to_df(innerHTML): #转换为Dataframe
f = open('innerHTML.html','w',encoding='utf-8') #创建html文件
f.write(innerHTML)
f.close()
f = open('innerHTML.html', encoding="utf-8")
html = f.read()
f.close()
dt = DisclosureTable(html) #使用chinfo解析方法中的DisclosureTable类
df = dt.get_data()
return df
df = pd.DataFrame()
for i in code:
innerHTML = get_cninfo(i) #开始获取网页信息
time.sleep(0.1)
df = df.append(html_to_df(innerHTML))
time.sleep(0.1)
#df.to_csv('list.csv')
#df = pd.read_csv('list.csv')
#df = df.iloc[:,1:]
#df['证券代码'] = df['证券代码'].apply(lambda x:'{:0>6d}'.format(x))
将读取并解析HTML文件的代码编制为函数以便循环,参考老师上课编写的解析深交所定期报告界面代码 我根据巨潮网定期报告表格HTML内容,编写了解析巨潮网页信息披露表格的类,导入后即可使用:
parse_chinfo_table.py
另外读取网页后应及时保存为csv文件备份信息,避免变量丢失而下载内容较多导致难以再次获取数据。
浏览器界面:
运行结果:
list.csv
def filter_links(words,df0,include=True): #筛选列表中相关内容的函数
ls = []
for word in words:
if include:
ls.append([word in f for f in df0['公告标题']])
else:
ls.append([word not in f for f in df0['公告标题']])
index = []
for r in range(len(df0)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df1 = df0[index]
return(df1)
words1 = ["摘要","已取消","英文"]
list = filter_links(words1,df,include=False) #去除摘要和已取消的报告等
fun1 = lambda x: re.sub('(?<=报告).*', '', x)
fun2 = lambda x: re.sub('.*(?=\d{4})', '', x)
list['公告标题'] = list['公告标题'].apply(fun1) #去除“20xx年(年)度报告”前后内容
list['公告标题'] = list['公告标题'].apply(fun2)
list = list.drop_duplicates(['证券代码','公告标题'], keep='first') #删去重复值,保留最新一项
list['年份'] = [re.search('\d{4}', title).group() for title in list['公告标题']]
list['公告标题'] = list['简称']+list['公告标题']
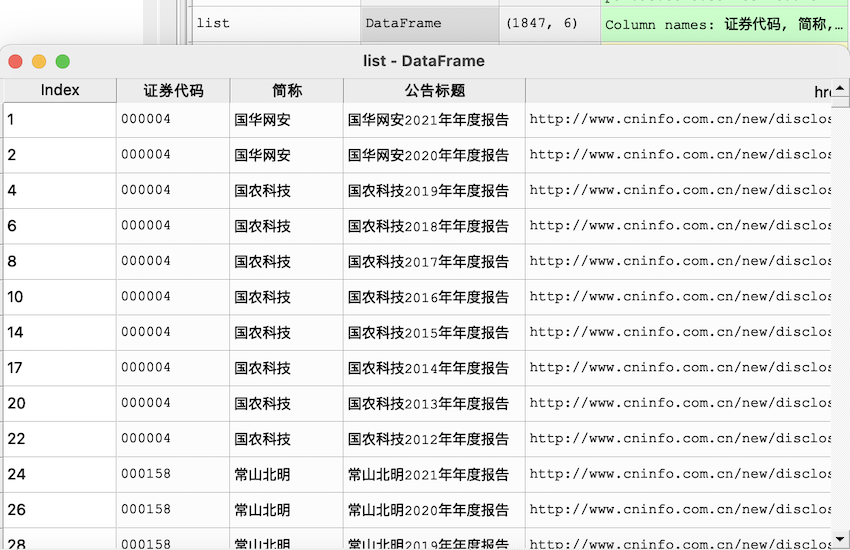
首先参考老师上课编写的筛选函数,将报告列表中可能存在的非年报内容根据标题筛选出去。下一步整理报告的标题格式,这一步建立在
上一步完全将摘要、取消版等我们不需要的数据剔除出去,在我分配到的行业中存在的问题主要有:英文版年报、取消的年报以及对应年份缺失的年报
(公告界面上仅存在摘要或已取消的报告),进行去除后用正则表达式将年报标题修改为XXXX20XX年(年)年报的格式,生成需下载年报的list,
如图,共有1847项:
os.makedirs('files')
os.chdir('/Users/leohuang/Desktop/学习/计算机/python/期末报告/files')
def get_pdf(r): #构建下载巨潮网报告pdf函数
p_id = re.compile('.*var announcementId = "(.*)";.*var announcementTime = "(.*?)"',re.DOTALL)
contents = r.text
a_id = re.findall(p_id, contents) #获取下载报告地址的参数
new_url = "http://static.cninfo.com.cn/finalpage/" + a_id[0][1] + '/' + a_id[0][0] + ".PDF"
result = requests.get(new_url, allow_redirects=True) #组合正确定向网址并访问
time.sleep(1)
return result
for c in code:
rpts = list[list['证券代码']==c]
for row in range(len(rpts)):
r = requests.get(rpts.iloc[row,3], allow_redirects=True)
time.sleep(0.3)
try:
result = get_pdf(r)
f = open(rpts.iloc[row,2]+'.PDF', 'wb') #下载并命名
f.write(result.content)
f.close()
r.close()
except:
print(rpts.iloc[row,2]+“下载出错”)
用巨潮网下载数据存在一个问题,其定期报告表格HTML中给出的跳转网址不是最终的年报文件网址,而是根据跳转网址中HTML的
参数再进行重定向,但利用request访问时其并不会自动重定向至文件页面,故根据网址格式提取数据后再次输入网页并访问,如图,
下载页的网址格式为http://static.cninfo.com.cn/finalpage/+/announcementId+/announcementTime:

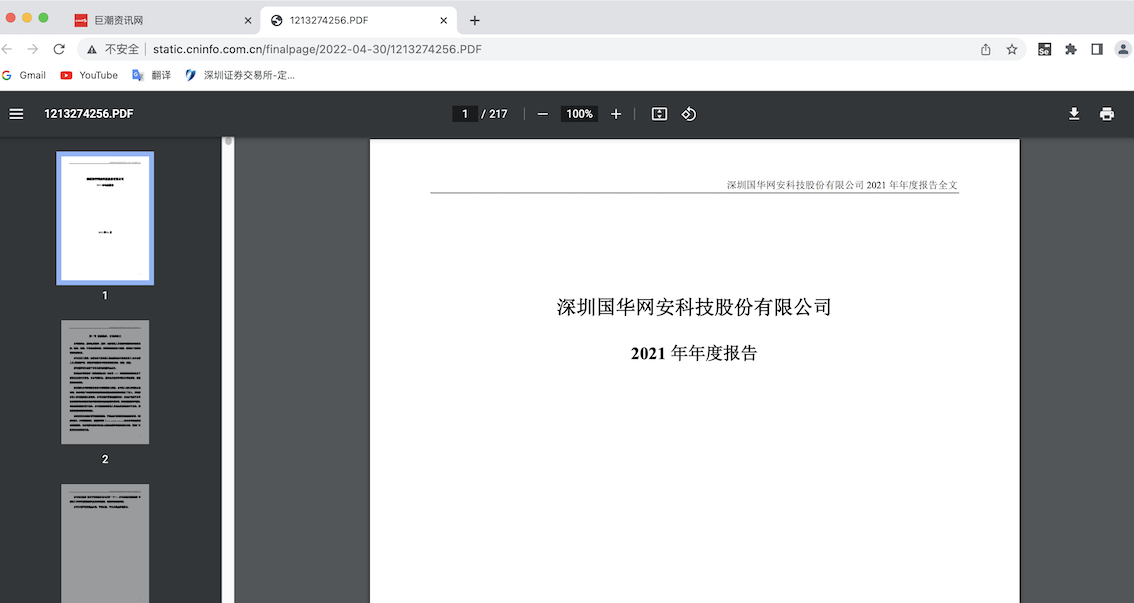
之后根据list中的数据逐个下载,下载时注意留出时间间隔,有个别年报下载可能出现问题,手动补上即可。
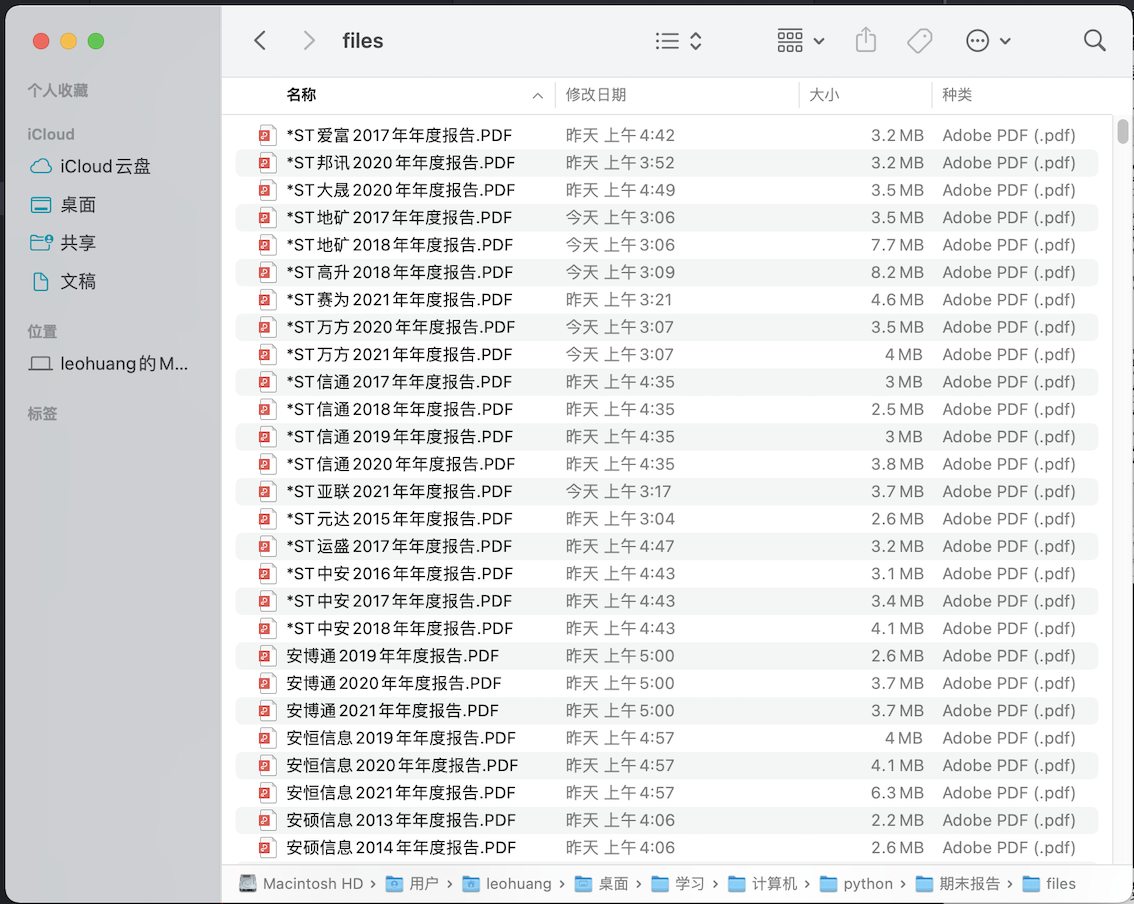
#Step3 解析年报数据
def get_adata(rpt): #构建获取营业收入和每股收益数据的函数
text = ''
for page in rpt:
text += page.get_text()
p_s = re.compile('(?<=\\n)[\D、]?\D*?主要\D*?数据和\D*?(?=\\n)(.*?)稀', re.DOTALL)
txt = p_s.search(text).group(0) #匹配对应内容
p1 = re.compile('营(.*?)归',re.DOTALL) #匹配年报中3年的营业收入
data = p1.search(txt).group()
data = data.replace('\n', '') #替换掉换行符
p_digit = re.compile(r'(-)?\d[,0-9]*?\.\d{1,2}') #匹配内容中的数字到小数点后2位
turnover = p_digit.search(data).group()
turnover = turnover.replace(',','') #去掉逗号
p2 = re.compile('基(.*?)稀',re.DOTALL) #匹配年报中3年的基本每股收益
data = p2.search(txt).group()
data = data.replace('\n', '')
pe = p_digit.search(data).group()
return turnover,pe
#获取营业收入和每股收益数据
turnovers = pd.DataFrame(columns=['公司'] + [year for year in range(2012,2022)])
pes = pd.DataFrame(columns=['公司'] + [year for year in range(2012,2022)])
for i in range(len(code)):
firm = list[list['证券代码']==code[i]]
turnovers.loc[i,'公司'] = firm.iloc[0,1]
pes.loc[i,'公司'] = firm.iloc[0,1]
for item in range(len(firm)):
try:
rpt = fitz.open(firm.iloc[item,2]+'.PDF')
turnover, pe = get_adata(rpt)
turnovers[int(firm.iloc[item,-1])][i] = turnover
pes[int(firm.iloc[item,-1])][i] = pe
except:
print(firm.iloc[item,2]+'解析出错')
turnovers_n = turnovers.iloc[:,1:].astype('float')
turnovers_n.index = turnovers['公司']
turnovers_n.loc['皖通科技',2012] = 660944646.11 #手动输入读取时乱码的文件数据
turnovers_n.loc['德生科技',2018] = 459913767.01
turnovers_n.loc['万达信息',2013] = 2680566934.70
turnovers_n.to_csv('营业收入汇总.csv')
pes_n = pes.iloc[:,1:].astype('float')
pes_n.index = pes['公司']
pes_n.loc['皖通科技',2012] = 0.49
pes_n.loc['德生科技',2018] = 0.54
pes_n.loc['万达信息',2013] = 0.26
pes_n.to_csv('每股收益汇总.csv')
提取年报数据存在的问题较多,此处编写的正则表达式只是适应于我本次所分析的年报,将处理文档范围进一步扩大
可能出现其他问题,此处将我遇到的问题和潜在问题列示如下:
(1)读取年报文件时文字乱码
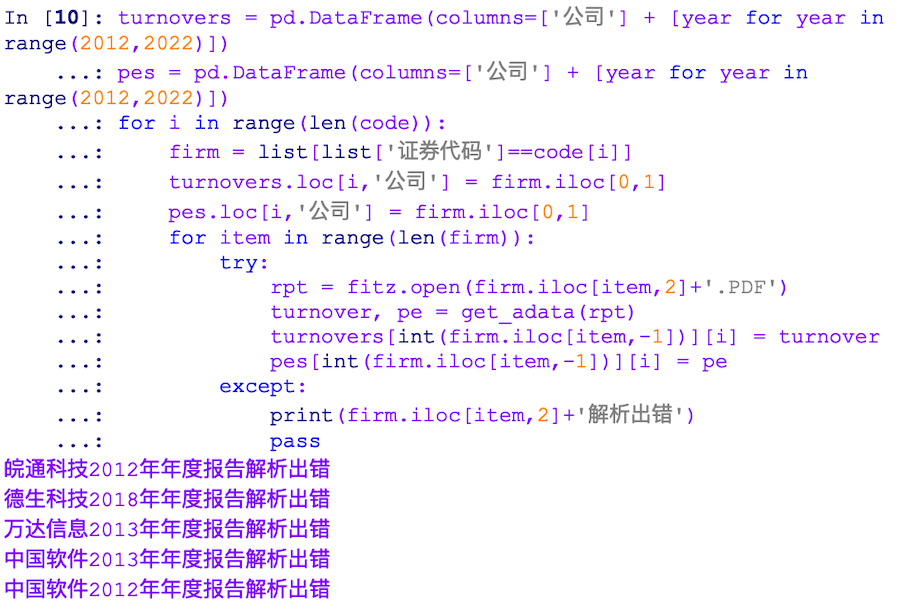
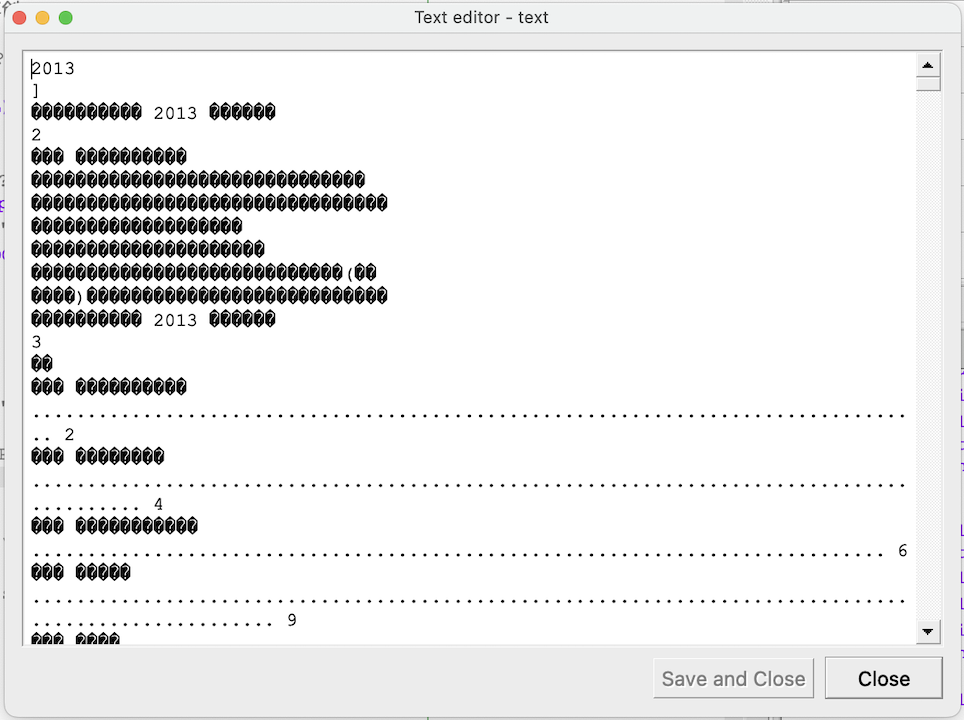
报错的文件中,皖通科技2012年年度报告、德生科技2018年年度报告、万达信息2013年年度报告这三项解析时出现乱码:
(2)未考虑小标题内文字之间存在的空格
如图,标题中公司近三年文字与数字之间存在空格,导致匹配财务数据位置出现问题,修改正则表达式后即可正常读取

(3)未考虑营业收入单位问题
经过对营业收入结果长度进行判断测试,我所处理的年报中并未发现“元”以外的单位,若存在不同单位,
应利用正则表达式提取单位信息后对营业收入进行倍数处理。
(4)未考虑小数点位数问题
我用于匹配数字的正则表达式固定取小数点后两位的数字,但存在个别公司营业收入无小数点或者每股收益小于0.01,
导致匹配结果错误或者为0,对应地调整正则表达式使其适配即可正常获取。
(5)其他问题
经过与同学的讨论,发现其他同学还遇到了解析文件后出现繁体字、英文等问题,这些问题在我所解析的文件中未曾遇到,
但当需解析文件的量提升后,则更容易出现正则表达式无法正常匹配的问题,需要针对不同情况调整正则表达式。
以下为最终结果及csv:

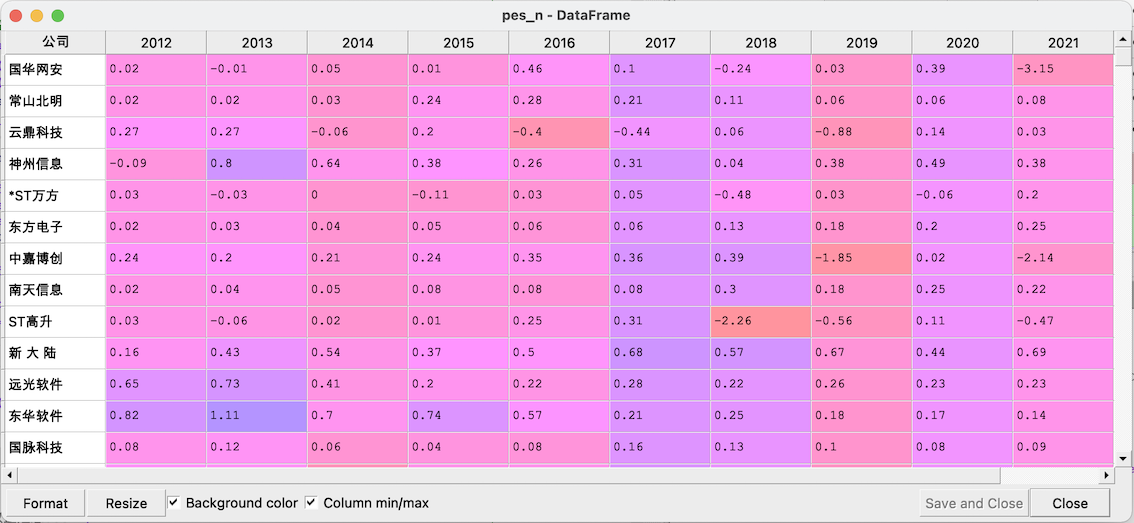
营业收入汇总.csv
每股收益汇总.csv
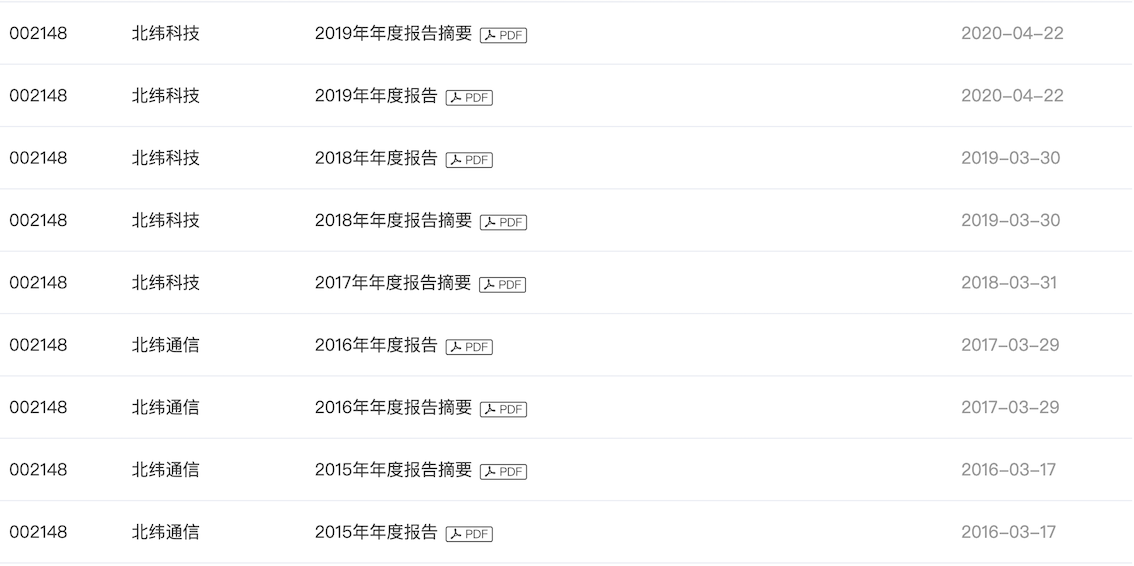
最终结果亦存在缺失值,原因有二:公司上市时间不足10年、公告页面某年年度报告缺失,例如北纬科技2017年未在巨潮网公布完整年报,手动查询后补上即可,
另外注意将字符型数据转化为浮点型数据。
def get_bdata(rpt):
text = ''
for page in rpt:
text += page.get_text()
p1 = re.compile('(?<=\\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\\n)', re.DOTALL)
infom1 = p1.findall(text)[0]
p2 = re.compile('(?<=\n)公司\w*网\s?址:?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
infom2 = p2.findall(text)[0]
return infom1,infom2
rpt = fitz.open(firm.iloc[firm['年份'].argsort().iloc[-1],2]+'.PDF')
info = pd.DataFrame(columns=['股票代码', '股票简称', '办公地址', '公司网址'])
for i in range(len(code)):
firm = list[list['证券代码']==code[i]]
try:
rpt = fitz.open(firm.iloc[firm['年份'].argsort().iloc[-1],2]+'.PDF')
info1,info2 = get_bdata(rpt) #以年份排序索引,获取最新一期年报
info.loc[i,'股票代码'] = firm.iloc[0,0]
info.loc[i,'股票简称'] = firm.iloc[0,1]
info.loc[i,'办公地址'] = info1
info.loc[i,'公司网址'] = info2
except:
print(firm.iloc[firm['年份'].argsort().iloc[-1],2]+'解析出错')
info.to_csv('公司信息.csv')
提取过程与获取营业收入和每股收益类似,只需要修改正则表达式即可,获取地址和网址所选年报为网页公布的最新一期年报,
解析量明显少于提取营业收入,未发生报错。
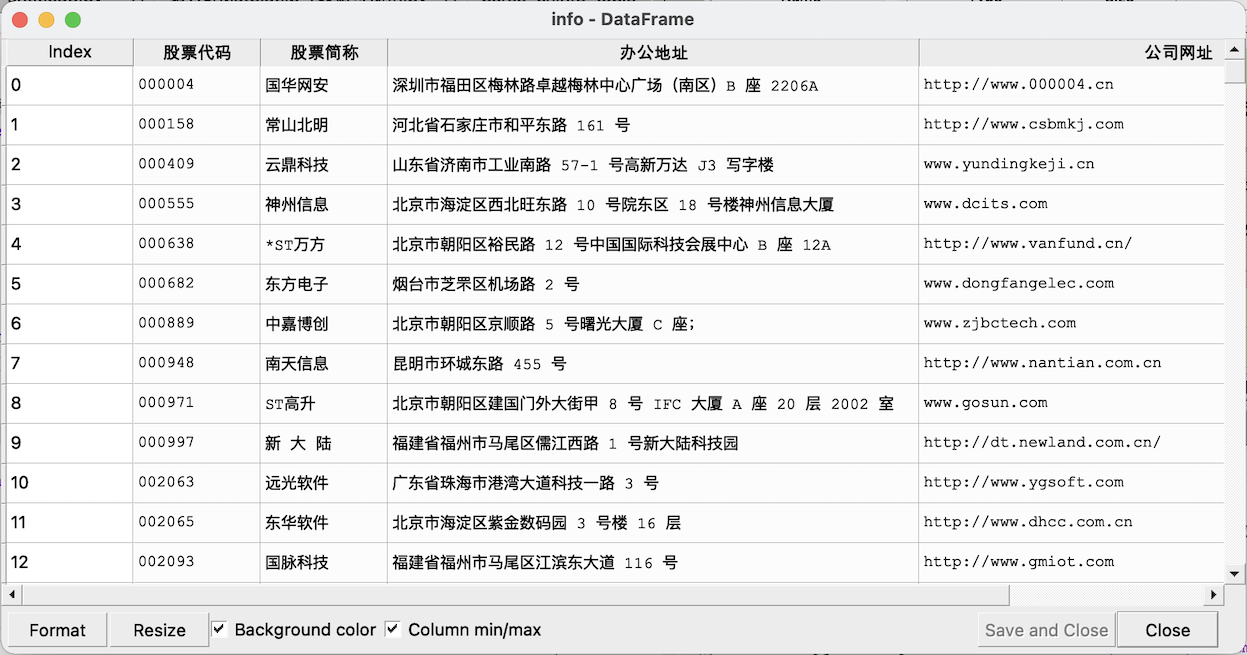
公司信息.csv
#Step4 绘制图表并分析
#绘制营业收入变化趋势图表
plt.rcParams['font.sans-serif']=['SimHei'] #确保显示中文
plt.rcParams['axes.unicode_minus'] = False #确保显示负数的参数设置
chart1 = turnovers_n
chart1['公司简称'] = turnovers_n.index
chart1.index = [i for i in range(len(chart1))]
chart1 = chart1.dropna() #去除数据有缺失或不足十年的公司
chart1['mean'] = chart1.iloc[:,:10].apply(lambda x: x.sum()/10, axis=1)
chart1 = chart1.sort_values('mean', ascending=False)[:10] #取平均值排序
chart1.iloc[:,:10] = chart1.iloc[:,:10]/100000000
i = 9 #画图
plt.plot(chart1.columns[:10], chart1.iloc[i,:10], marker='o')
plt.xticks(np.linspace(2012,2021,10))
plt.xlabel('年份',fontsize=13)
plt.ylabel('营业收入(亿元)',fontsize=11)
plt.title(chart1.iloc[i,10]+"营业收入折线图",fontsize=14)
plt.show()
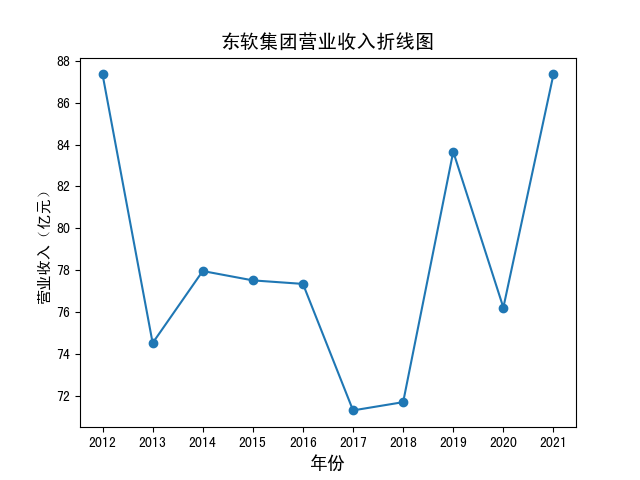
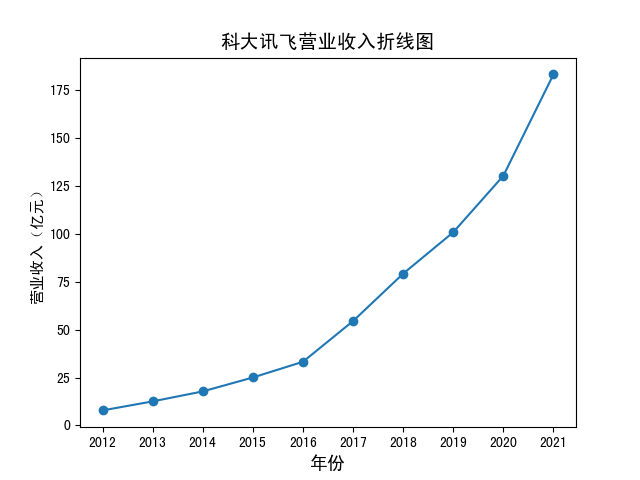
绘图前注意中文设置,此处我删去了数据不足十年的股票,之后取股票十年的平均值排序,取最高的十家公司绘图,
以下为结果,此处单独展示3张图,其余用多子图形式展示。
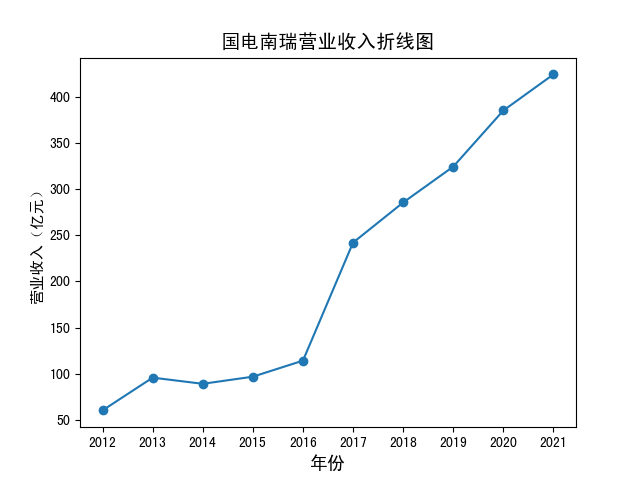
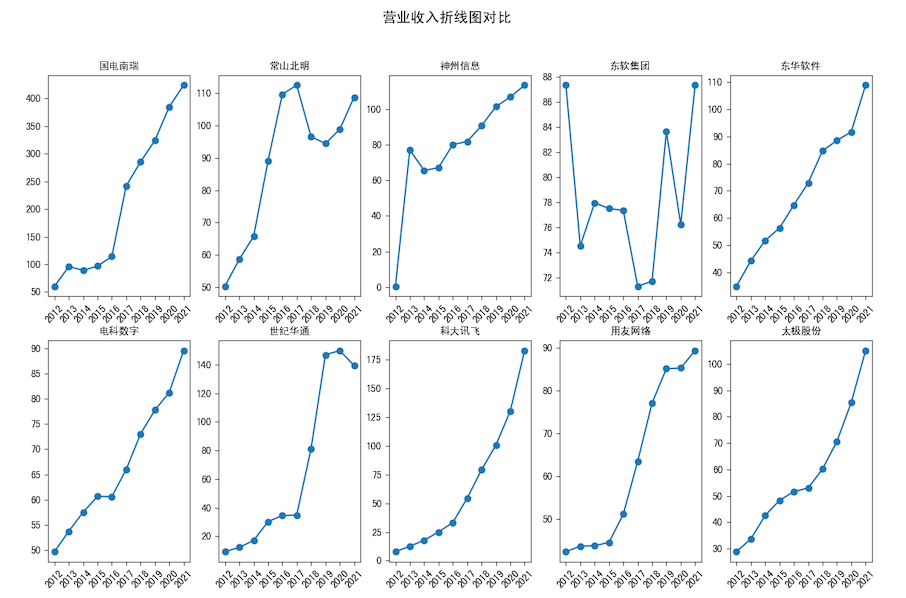
营业收入.zip
分析:平均营业收入最高的公司为国电南瑞,数据为211.6192亿元,大部分企业为持续增长,其中常山北明和东软集团波动较大,
事实上软件与信息技术服务业在这十年中,大多数企业处于成长期,在未受到明显冲击的情况下,营业收入一般呈上升态势
该分析存在的问题主要是未考虑股票退市、借壳上市等情况,故营业收入可能在某些年差距较大,可以考虑在筛选报告的步骤中添加条件。
#绘制每股收益变化趋势图表
chart2 = pes_n
chart2['公司简称'] = pes_n.index
chart2.index = [i for i in range(len(chart2))]
chart2['mean'] = chart2.iloc[:,:10].apply(lambda x: x.sum()/10, axis=1)
chart2 = chart2.sort_values('mean', ascending=False)[:10]
for i in range(10):
plt.subplot(2,5,i+1)
plt.plot(chart2.columns[:10], chart2.iloc[i,:10], marker='o')
plt.xticks(np.linspace(2012,2021,5,dtype=int))
plt.title(chart2.iloc[i,10],fontsize=10)
plt.suptitle('基本每股收益对比', fontsize=14)
plt.show()
与上一部分一样,此处单独展示3张图,其余用多子图形式展示。
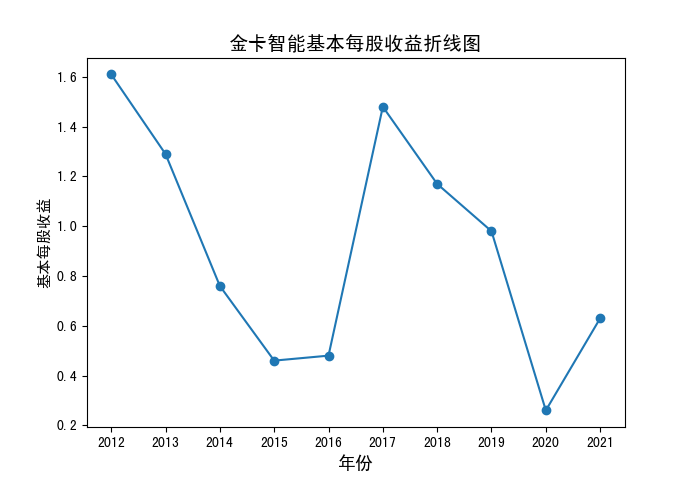
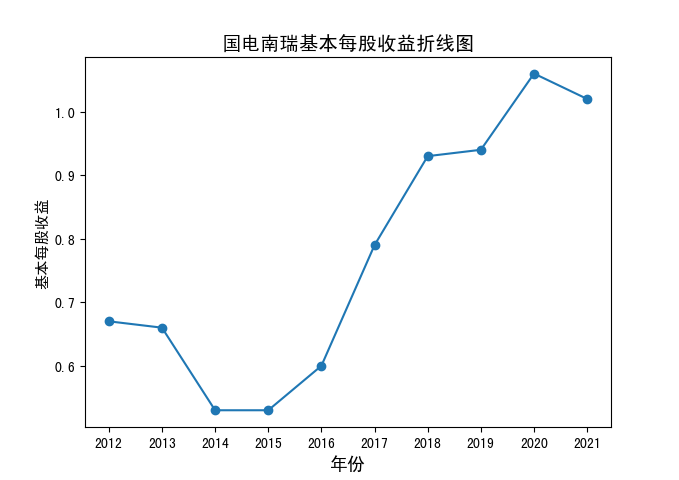
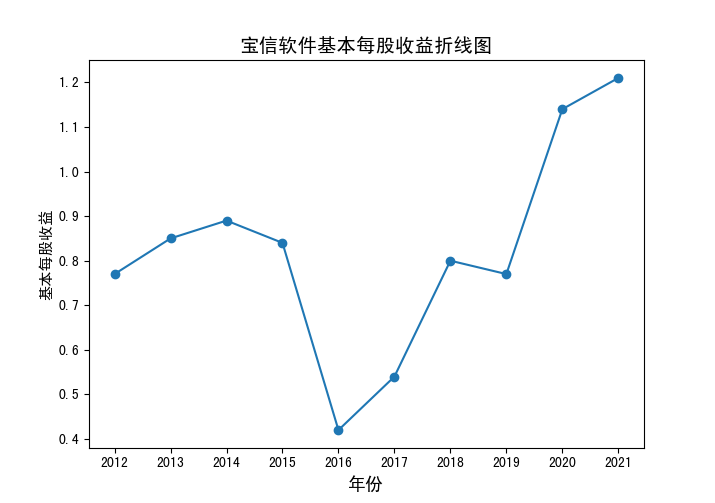
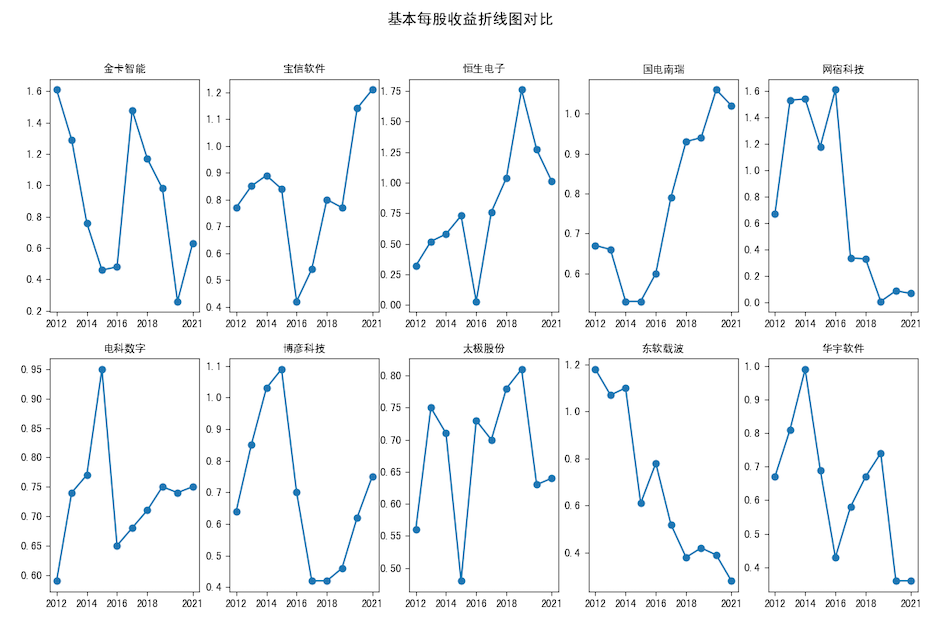
基本每股收益.zip
分析:可以发现,国电南瑞、电科数字、太极股份也位列平均营业收入前十位中,但其他营业收入前十位的公司平均每股收益并非很高,且相比于营业收入
平均每股收益波动更大一些,除了东钦载波的明显下降趋势,其他似乎并无明显规律。
#绘制逐年营业收入和每股收益图表
year = 2021
item = pd.concat([turnovers_n[year], turnovers_n['公司简称']], axis=1)
item[year] = item[year]/100000000
item = item.sort_values(year, ascending=False).iloc[:10]
plt.bar(item['公司简称'],height=item[year],width=0.5)
plt.title(str(year)+'年营业收入分布柱状图')
plt.ylabel('营业收入(亿元)',fontsize=11)
plt.xticks(rotation=45)
plt.show()
year = 2021
item = pd.concat([pes_n[year], pes_n['公司简称']], axis=1)
item[year] = item[year]
item = item.sort_values(year, ascending=False).iloc[:10]
plt.bar(item['公司简称'],height=item[year],width=0.5)
plt.title(str(year)+'年每股收益分布柱状图')
plt.ylabel('基本每股收益',fontsize=11)
plt.xticks(rotation=45)
plt.show()
以下展示营业收入结果:
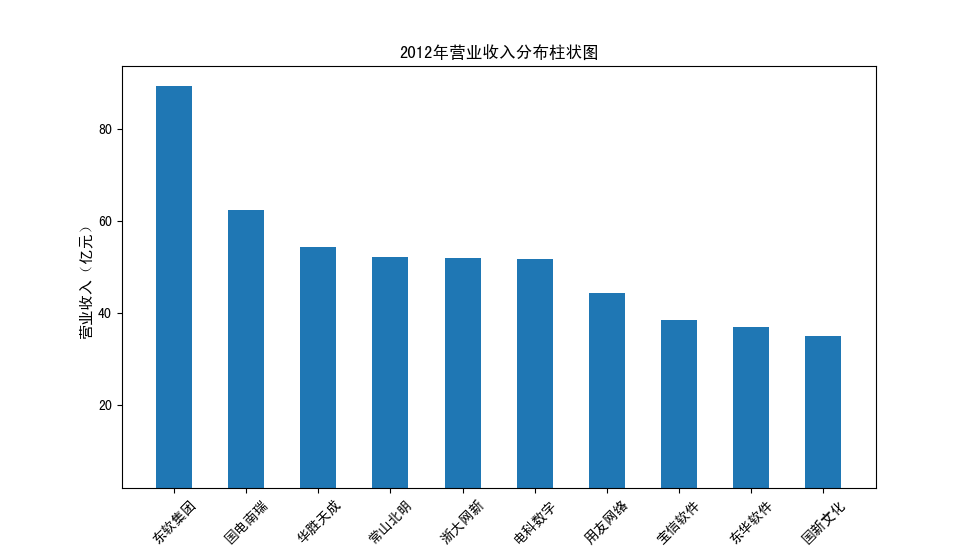
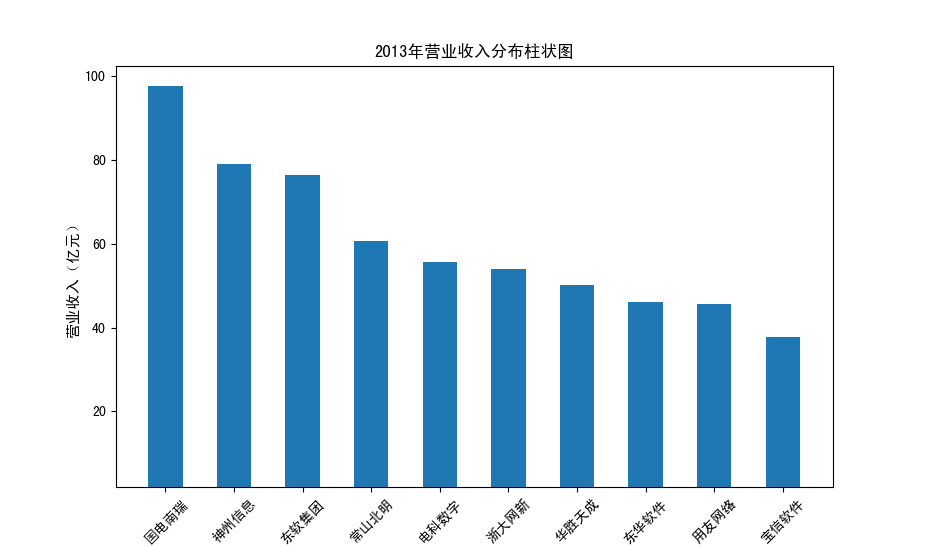
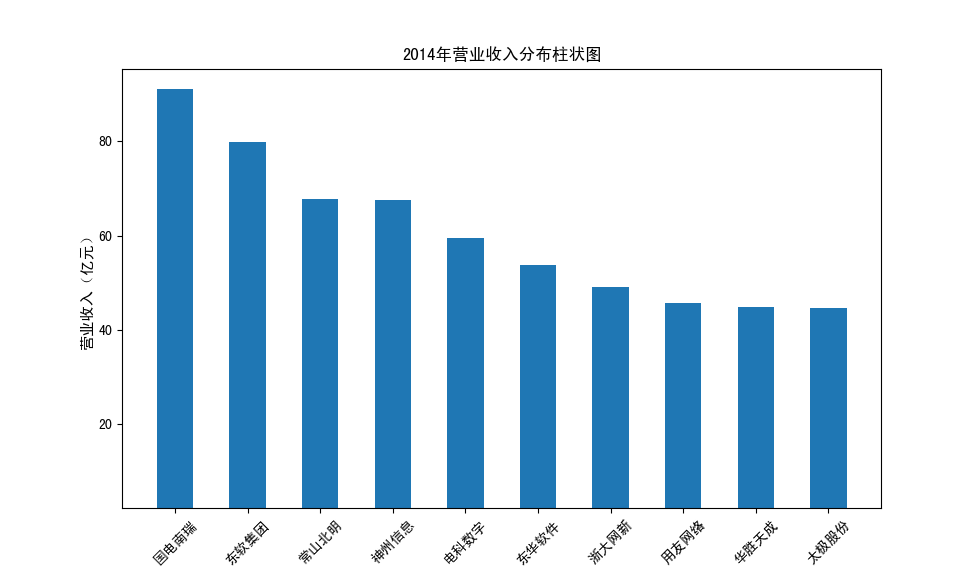
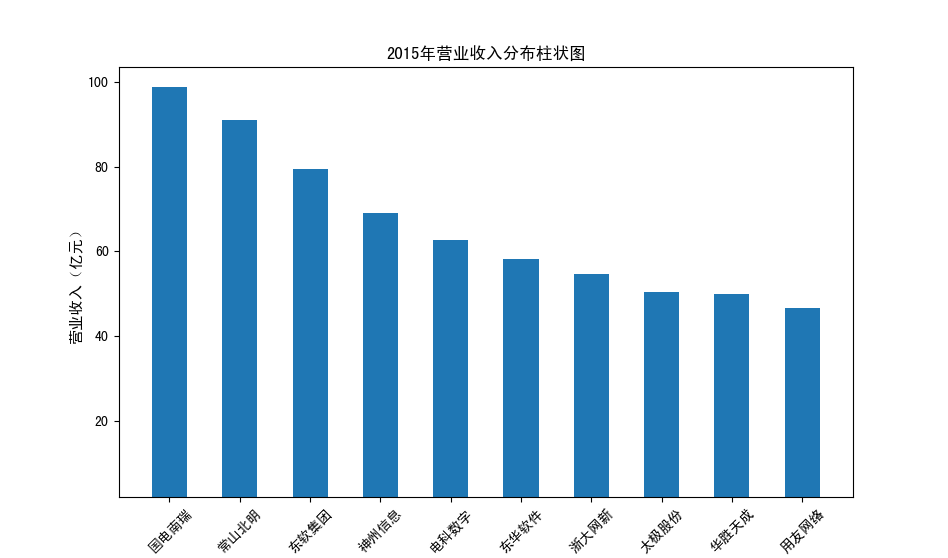
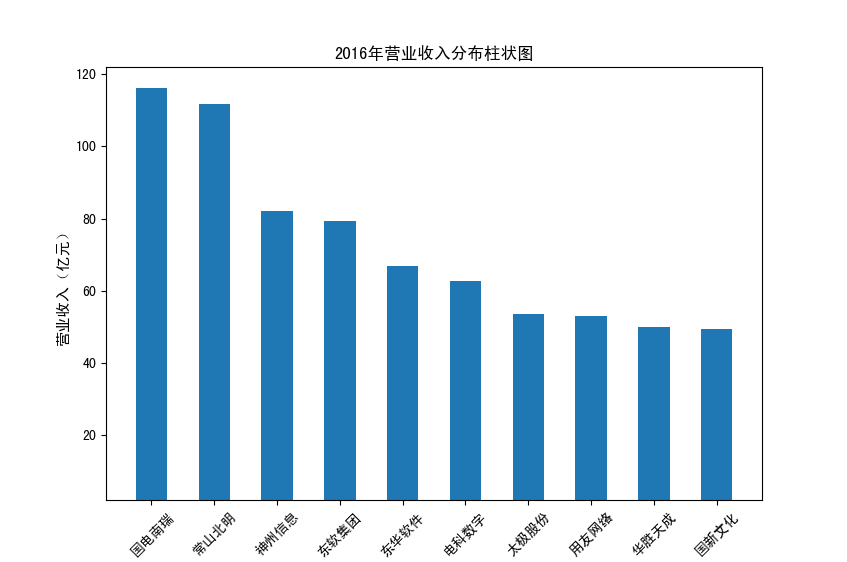
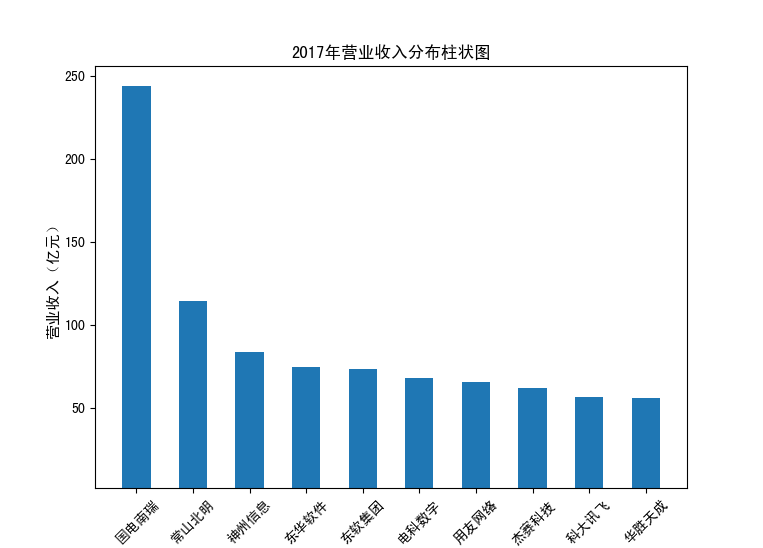
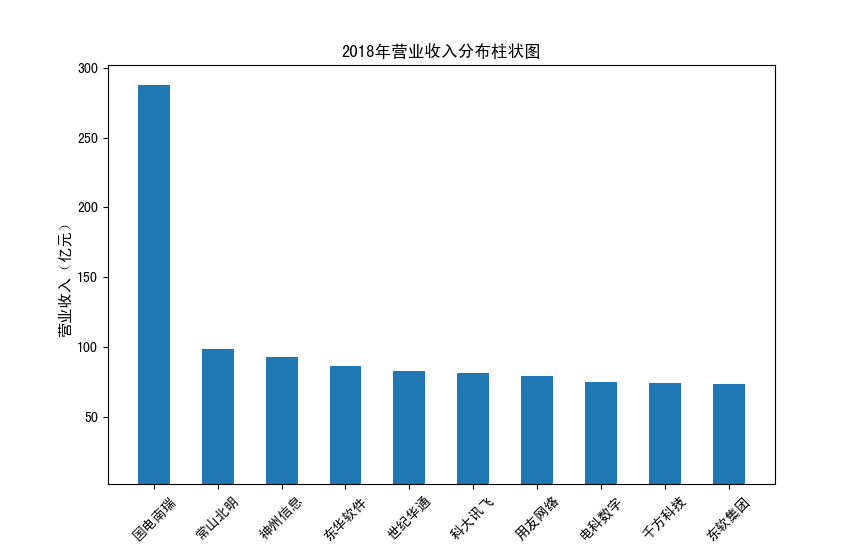
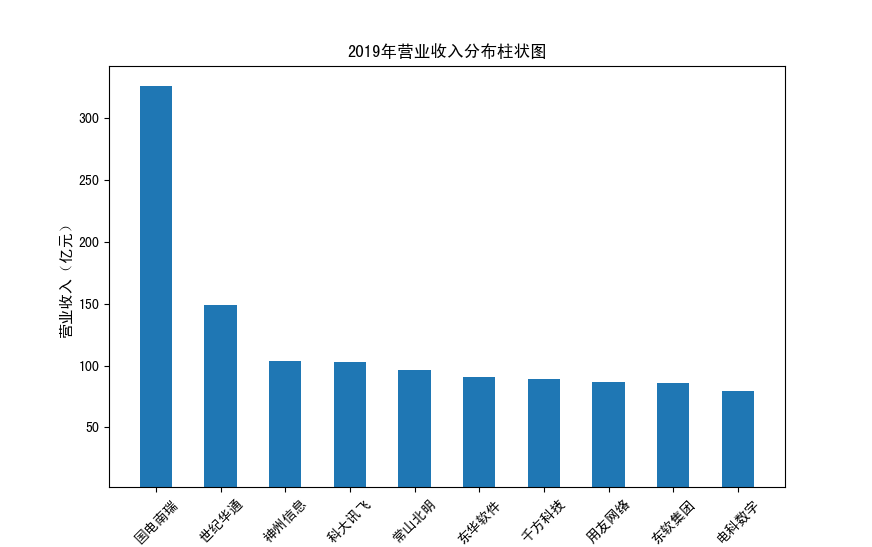
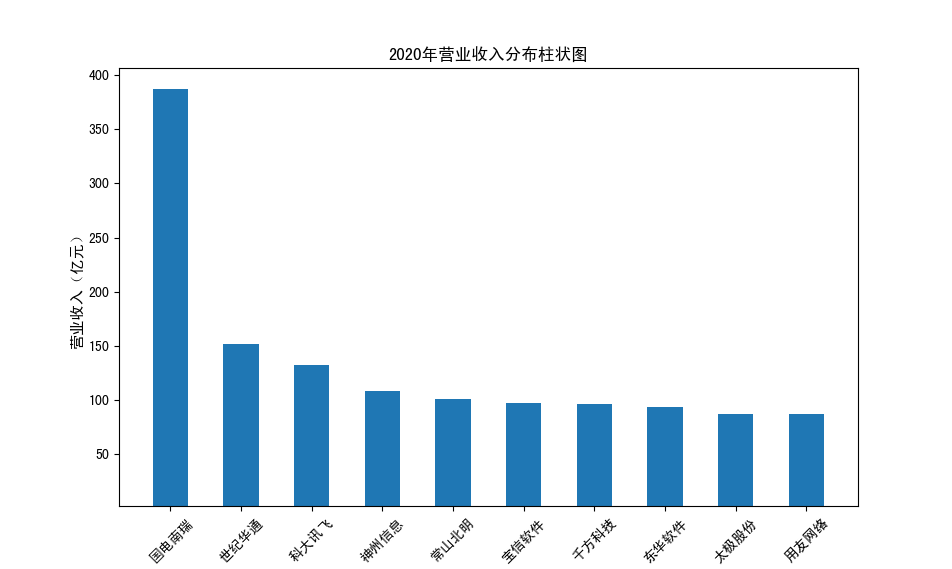
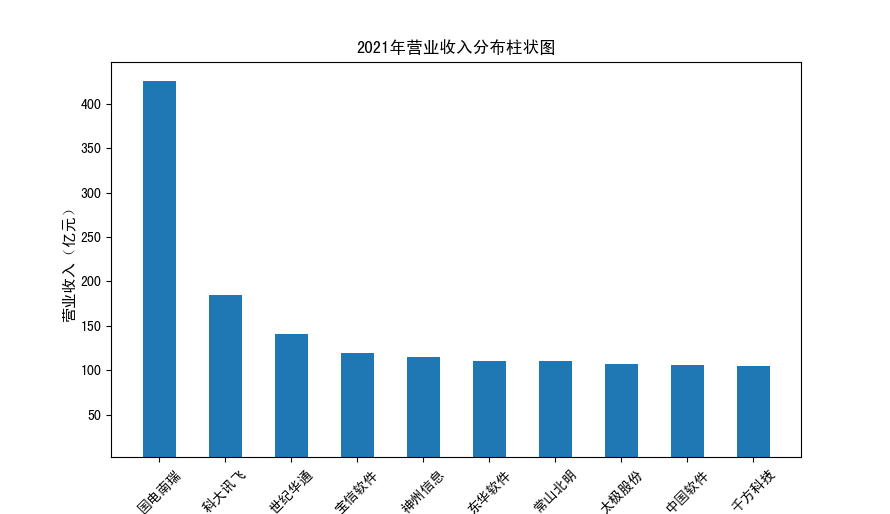
以下展示每股收益结果:
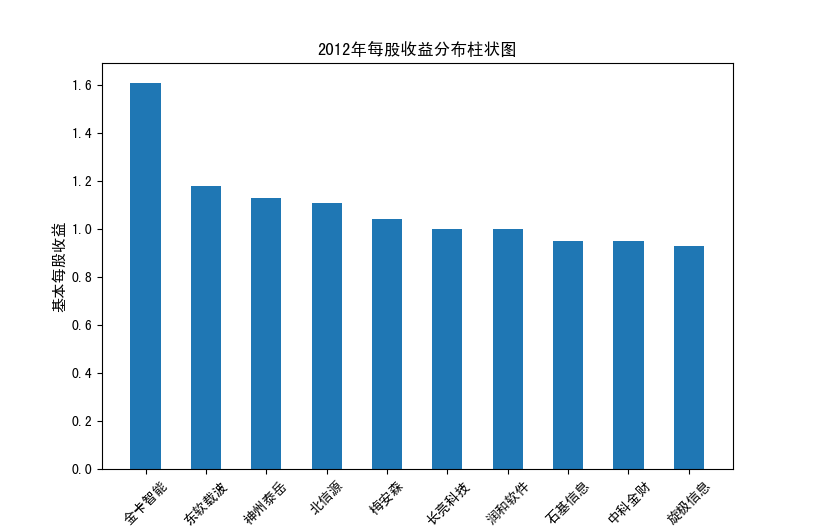
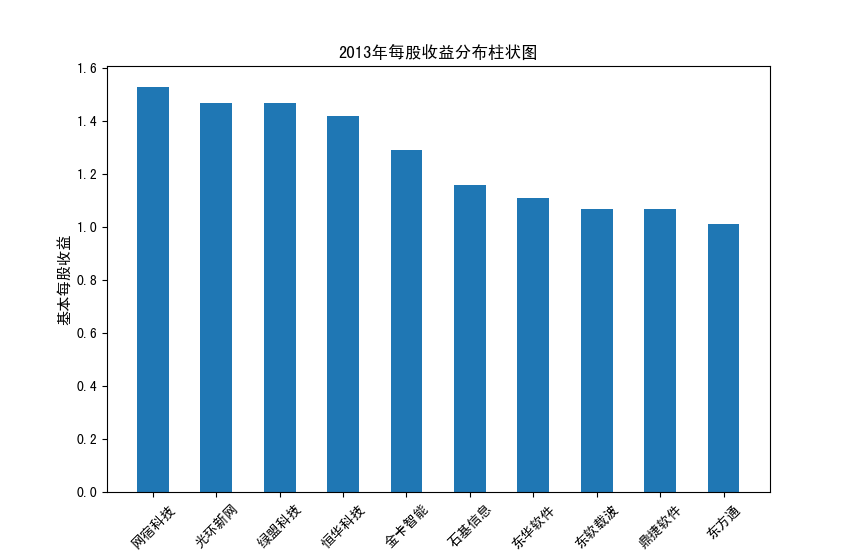
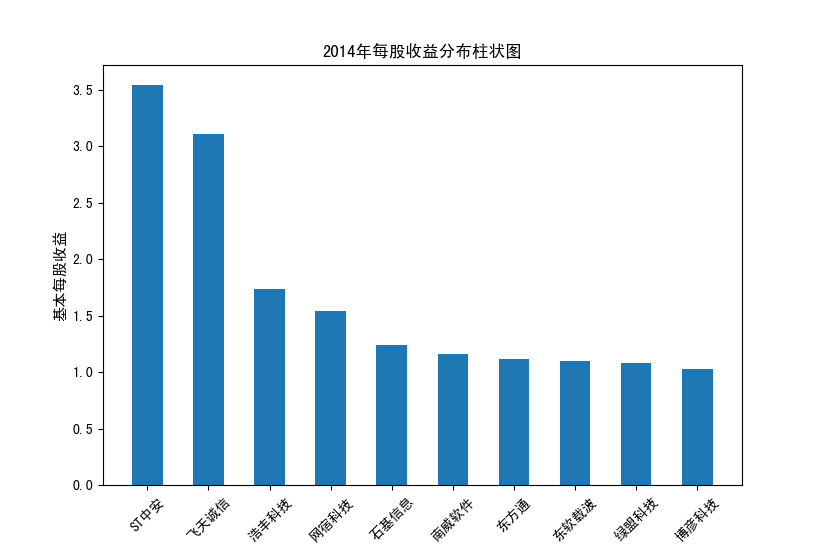
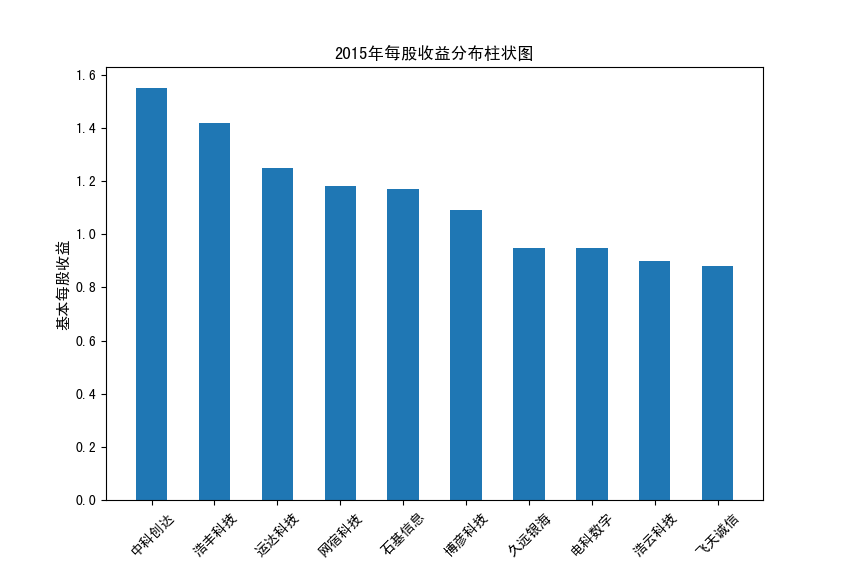
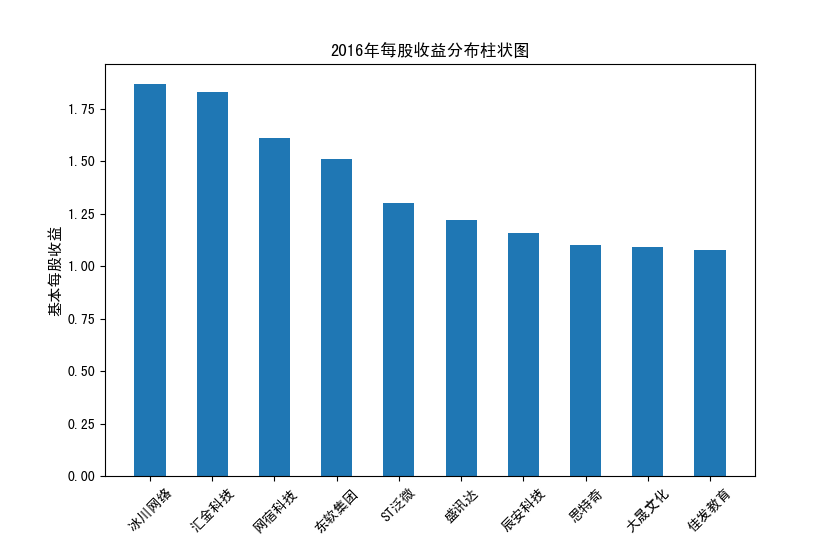

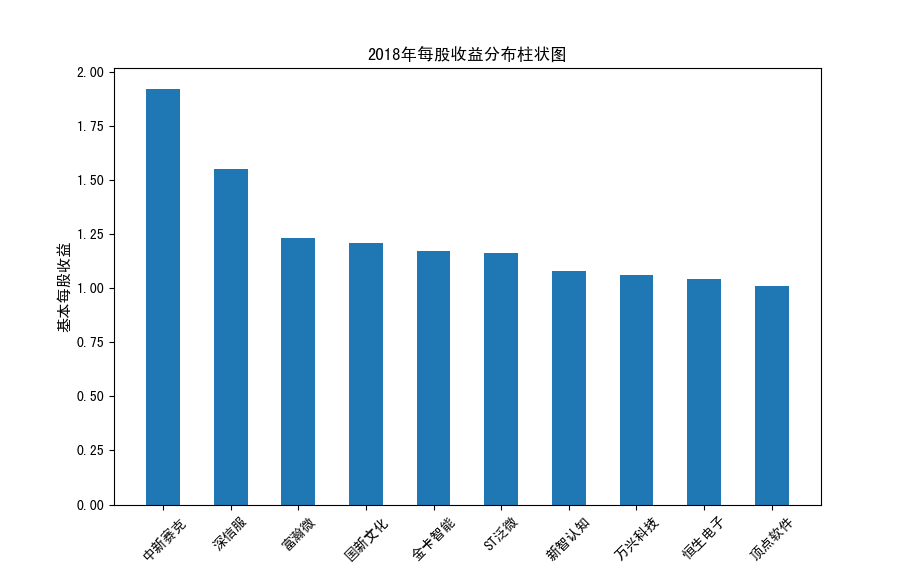
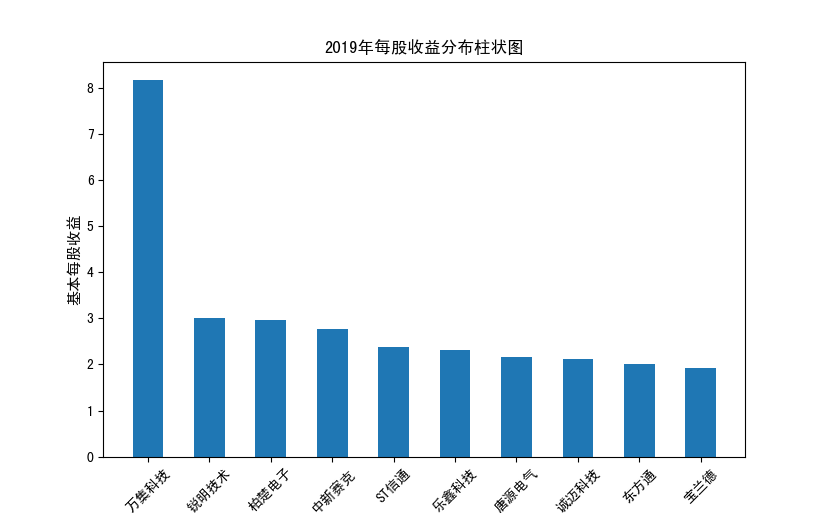
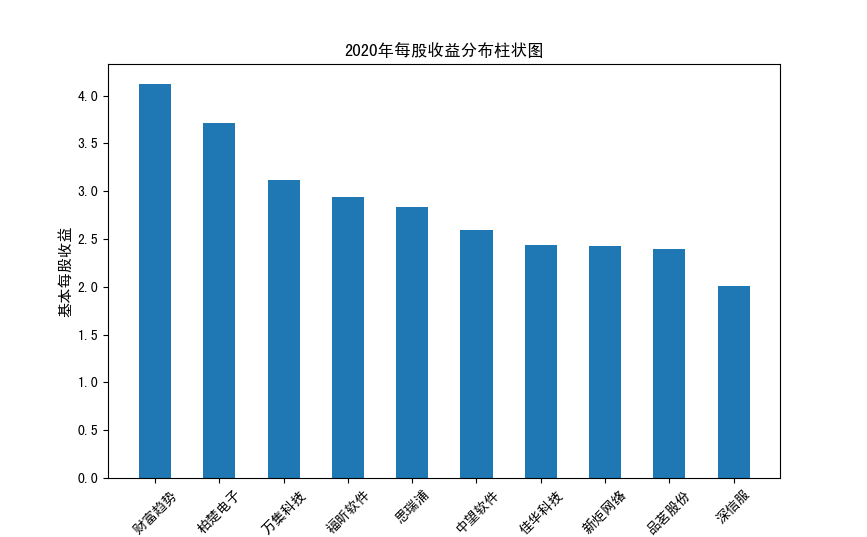
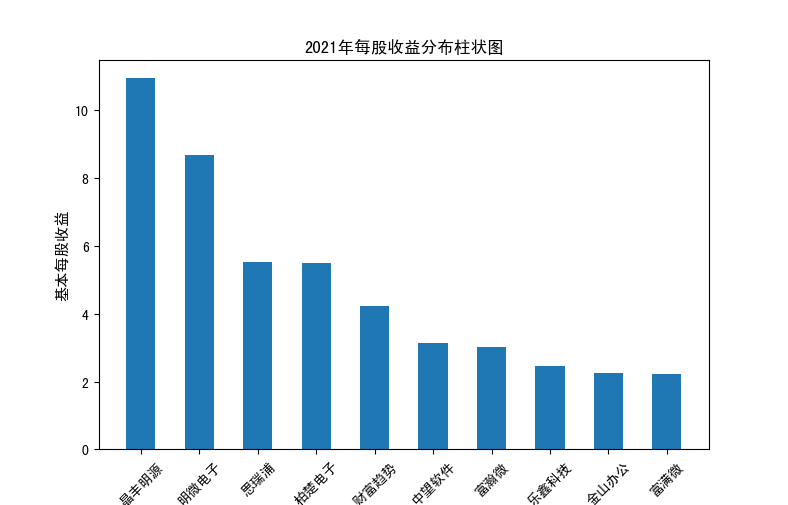
分析:从营业收入可以看出国电南瑞属于该行业龙头,自2012年超过东钦集团后十年来一直处于第一位,且自从2017年起超越
第二位约一倍,稳定占据市场份额。东钦载波自2013年开始持续走低,其余公司营业收入位次时常交替,其中常山北明公司
经常位于第二,经查询资料,国电南瑞属于国家电网系统内首家上市公司,业内地位较高,收入稳定,增长态势良好。
而根据每股收益数据,我们可以发现其位次与营业收入没有必然关系,这也从实际角度说明了一些小盘股可能相较于行业龙头
在股票收益上可能更高,且排行不稳定,反映了市场的波动性,在股票市场上很难单纯通过选择公司找到真正意义上的“常胜将军”。
但从行业整体而言,筛选股价收益最高的十家企业,往往都能获得高于1的基本每股收益,说明软件与信息技术行业的盈利能力较强
具备投资潜力。
经过本次期末作业的练习,我对独立完成这样一个较长流程的Python项目有了新的体会。从提取网页表格数据,到获取年报数据并绘图,
每一步在实际操作时都容易出现较多的问题,由于我所分配到的行业公司较多,故在下载、解析数据时时常因为一些特殊情况导致程序无法正常运行,
例如公告标题的不规范、年报格式的不规范等,都容易使较为细致而严格的正则表达式出现问题,在筛选数据时,也需要考虑更多的情况,提高代码的容错能力。
另一方面,本项目涉及到的库较多,需要对各个库的功能都比较熟悉,除了本课程中接触到的正则表达式、request、Selenium、PyMuPDF等,还需要对pandas、matplotlib等基础数据分析库有一定掌握
,将各个数据进行正确处理,构建明确的算法才能获得需要的结果,由于整个流程相对较长,需要理清各个变量之间的关系,这对提升我们的编程素质有较大的帮助。
事实上,如果从0开始编写这份代码,我们可能需要花费比较长的时间才能完成,老师在课堂上为我们编写的方法减少了我们的工作量,也为我们自己编码提供了思考方向。
选择这门课程的初衷是想尝试处理金融基本面数据,为量化投资的学习实践提供帮助,而实际上,我在这门课程中的收获并不止这些,学习多个之前未接触到的Python库,
拓宽了我对这门编程语言的认识,也进一步感受到Python的强大,此前对于C语言等编程语言的学习更多的是掌握算法的编制和提高解决问题的能力,Python在这一基础上为
我们提供了更多解决问题的利器,为更多的程序学习者带来了便利。
最后感谢老师这一个学期以来的指导,这门课程的内容非常充实,对金融专业同学在程序方面的学习有很大的帮助,希望未来这门课能越开越好,让更多的同学深入了解Python。