import re
import pandas as pd
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import requests
from bs4 import BeautifulSoup
import time
import fitz
import matplotlib.pyplot as plt
from pandas import Series, DataFrame
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
%matplotlib qt5
print(fitz.__doc__)
os.chdir(r'C:\Users\20279\Desktop\金融数据获取期末代码测试')
导入环境,其中plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False %matplotlib qt5 三行为保证中文以及使得画完图后以弹窗形式单独显示。
doc = fitz.open('行业分类.pdf')
doc.page_count
page83 = doc.load_page(82)
text83 = page83.get_text()
page84 = doc.load_page(83)
text84 = page84.get_text()
p1 = re.compile(r'水上运输业(.*?)航空运输业', re.DOTALL)
toc = p1.findall(text84)
toc1 = toc[0]
p2 = re.compile(r'(?<=\n)(\d{1})(\d{5})\n(\w+)(?=\n)')
toc2 = p2.findall(toc1)
p3 = re.compile(r'水上运输业\n(\d{1})(\d{5})\n(\w+)(?=\n)')
toc3 = p3.findall(text83)
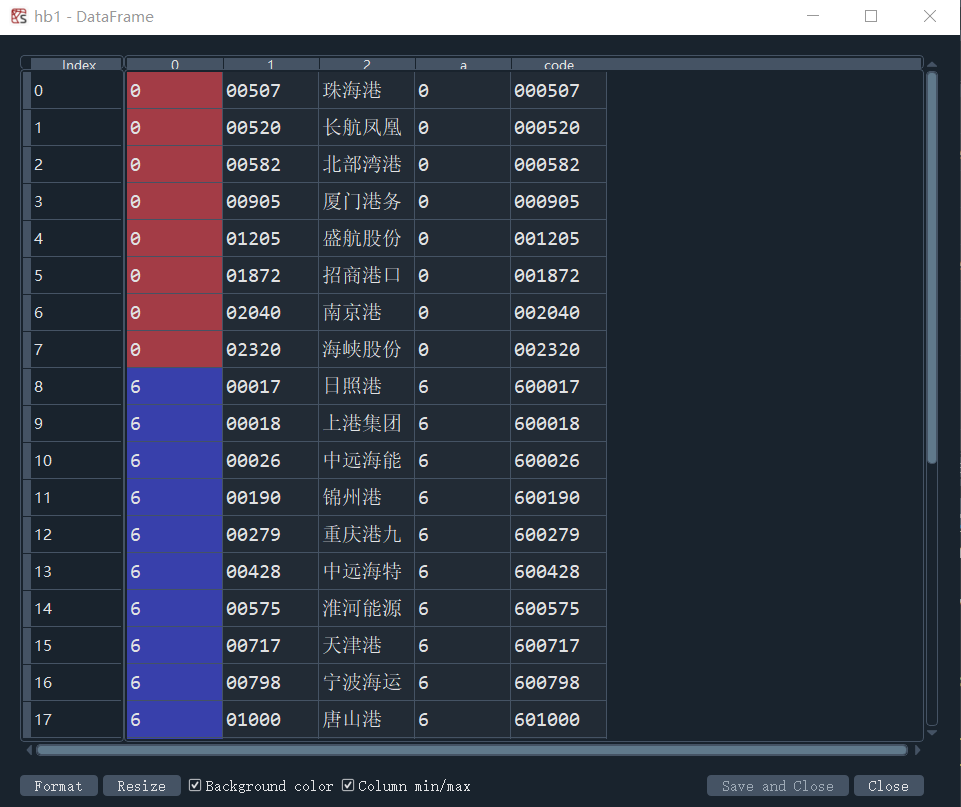
hb = toc3 + toc2
hb1 = pd.DataFrame(hb)
year = {'year': ['2012', '2013', '2014','2015', '2016', '2017', '2018', '2019', '2020', '2021']}
dy = pd.DataFrame(year)
hb1[0] = hb1[0].astype(int)
hb1['a'] = hb1[0].astype(str)
hb1['code'] = hb1['a'] + hb1[1]
sse = hb1.loc[(hb1[0]==6)]
szse = hb1.loc[(hb1[0]==0)]
sse['code'] = '6' + sse[1]
sse['code'] = sse['code'].astype(int)
sse = sse.reset_index(drop=True)
在使用后re解析pdf时,使匹配的结构为‘0’,‘00000’,‘公司名’,从而可以通过第一个数字来判断交易所,若为0或3则是深交所,6则为上交所。
driver_url = r"C:\edgedriver\msedgedriver.exe"
driver = webdriver.Edge(executable_path=driver_url, options=options)
'''szse'''
driver.get('http://www.szse.cn/disclosure/listed/fixed/index.html')
driver.implicitly_wait(10)
driver.set_window_size(1552, 840)
element = driver.find_element(By.ID, 'input_code')
element.send_keys('中联重科' + Keys.RETURN)
for i in range(len(szse)):
os.chdir(r'C:\Users\20279\Desktop\水上运输业10年内年度报告')
name = szse[2][i]
button = driver.find_element(By.CLASS_NAME, 'btn-clearall')
button.click()
element = driver.find_element(By.ID, 'input_code')
element.send_keys('%s'%name + Keys.RETURN)
driver.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
driver.find_element(By.LINK_TEXT, "年度报告").click()
time.sleep(2)
element = driver.find_element(By.ID, 'disclosure-table')
innerHTML = element.get_attribute('innerHTML')
f = open('innerHTML_%s.html'%name,'w',encoding='utf-8')
f.write(innerHTML)
f.close()
f = open('innerHTML_%s.html'%name,encoding='utf-8')
html = f.read()
f.close()
dt = DisclosureTable(html)
df = dt.get_data()
df['简称'] = name
df['公告时间'] = pd.to_datetime(df['公告时间'])
df['year'] = df['公告时间'].dt.year
df['year'] = df['year'] - 1
p_zy = re.compile('.*?(摘要).*?')
#删除公告标题中含有‘摘要’的行
for i in range(len(df)):
a = p_zy.findall(df['公告标题'][i])
if len(a) != 0:
df.drop([i],inplace = True)
df = df.reset_index(drop=True)
p_yw = re.compile('.*?(英文版).*?')
for i in range(len(df)):
a = p_yw.findall(df['公告标题'][i])
if len(a) != 0:
df.drop([i],inplace = True)
df = df.reset_index(drop=True)
p_nb = re.compile('.*?(年度报告).*?')
p_nb2 = re.compile('.*?(年报).*?')
#仅保留标题中含有年报或年度报告的内容,该步骤对深交所意义不大,但对解析上交所是十分关键的
for i in range(len(df)):
b1 = p_nb.findall(df['公告标题'][i])
b2 = p_nb2.findall(df['公告标题'][i])
if len(b1) == 0 and len(b2) == 0:
df.drop([i],inplace = True)
df = df.reset_index(drop=True)
#仅保留同一年中最晚发布的年报
df = df.drop_duplicates('year', keep='first', inplace=False)
df = df.reset_index(drop=True)
df['year_str'] = df['year'].astype(str)
df['name'] = name + df['year_str'] + '年年报'
name1 = df['简称'][0]
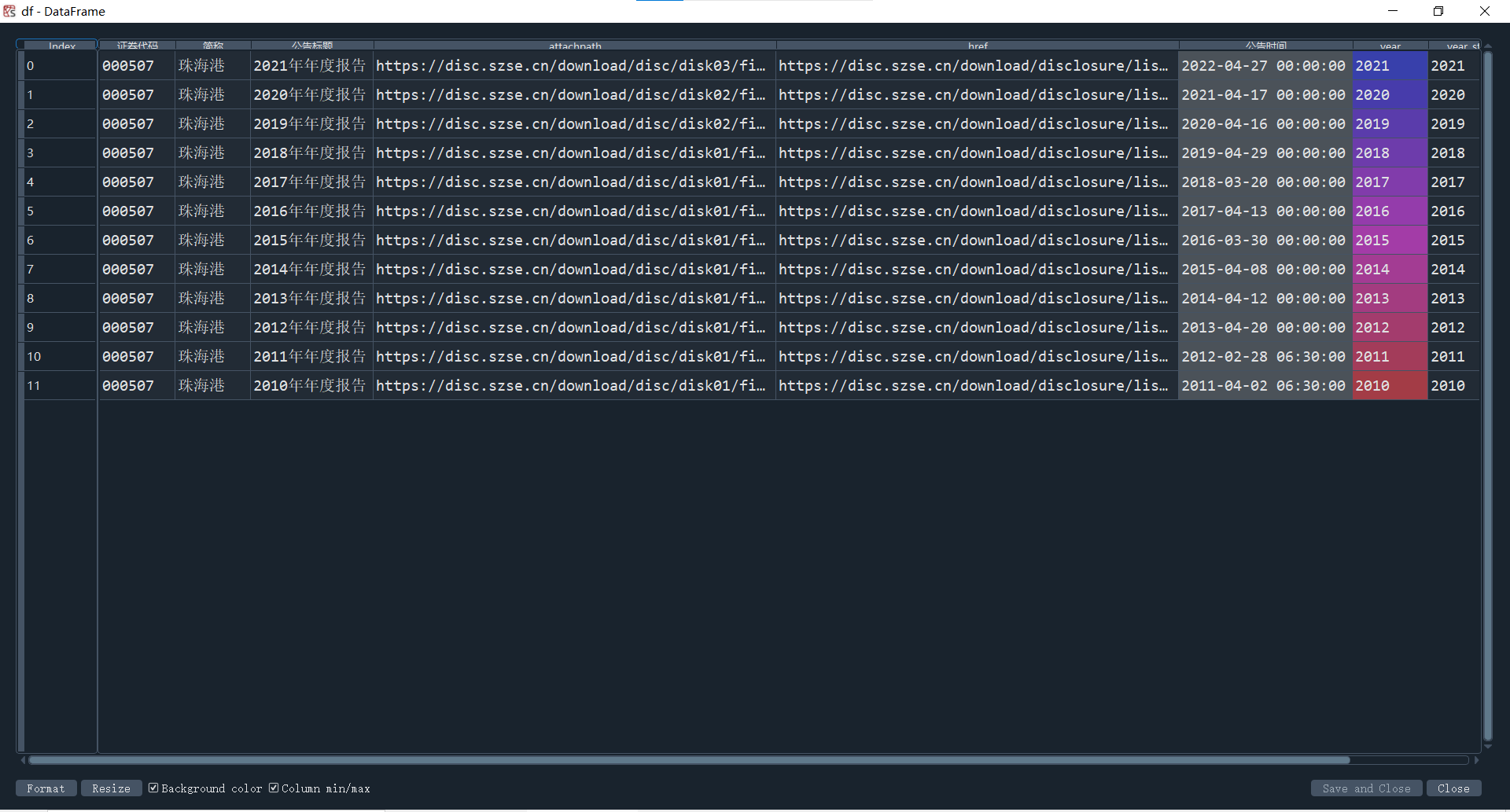
df.to_csv('%scsv文件.csv'%name1)
os.mkdir('%s年度报告'%name)
os.chdir(r'C:\Users\20279\Desktop\水上运输业10年内年度报告\%s年度报告'%name)
for y in range(len(dy)):
y = int(y)
ye = dy['year'][y]
name1 = df['简称'][0]
rename = name1 + ye
for a in range(len(df)):
if df['name'][a] == '%s年年报'%rename:
href0 = df.iat[a,3]
r = requests.get(href0, allow_redirects=True)
f = open('%s年度报告.pdf'%rename, 'wb')
f.write(r.content)
f.close()
r.close()
对于解析出来的dataframe,先剔除公告标题为摘要的行,我所使用的下载年报思路为;最晚上传的年报即为我需要下载的年报。通过该思路可以准确识别到需要下载的年报
,并且不需要去判断公告标题中是否含有如(更新后)等不统一的命名方式。
def get_link(txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
title = matchObj.group(2).strip()
return([attachpath, title])
p_a = re.compile('\n\s*(.*?)\s*?', re.DOTALL)
p_span = re.compile('\n\s*(.*?)\s*?', re.DOTALL)
get_code = lambda txt: p_a.search(txt).group(1).strip()
get_time = lambda txt: p_span.search(txt).group(1).strip()
def get_data(df_txt):
prefix_href = 'http://www.sse.com.cn/'
df = df_txt
ahts = [get_link(td) for td in df['公告标题']]
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['名称']]
#
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[1] for aht in ahts],
'href': [prefix_href + aht[0] for aht in ahts],
})
return(df)
driver.get('http://www.sse.com.cn/disclosure/listedinfo/regular/')
driver.implicitly_wait(10)
driver.set_window_size(1552, 840)
dropdown = driver.find_element(By.CSS_SELECTOR, ".selectpicker-pageSize")
dropdown.find_element(By.XPATH, "//option[. = '每页100条']").click()
time.sleep(1)
for i in range(len(sse)):
os.chdir(r'C:\Users\20279\Desktop\水上运输业10年内年度报告')
code = sse['code'][i]
driver.find_element(By.ID, "inputCode").clear()
driver.find_element(By.ID, "inputCode").send_keys("%s"%code)
driver.find_element(By.CSS_SELECTOR, ".js_reportType .btn").click()
driver.find_element(By.LINK_TEXT, "全部").click()
driver.find_element(By.CSS_SELECTOR, ".js_reportType .btn").click()
driver.find_element(By.LINK_TEXT, "年报").click()
time.sleep(1)
element = driver.find_element(By.CLASS_NAME, 'table-responsive')
innerHTML = element.get_attribute('innerHTML')
soup = BeautifulSoup(innerHTML)
html = soup.prettify()
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
#解析出来的trs中含有空格行,按以下方法进行删除
n = len(trs)
for i in range(len(trs)):
if n >= i:
if len(trs[i]) == 5:
del trs[i]
n = len(trs)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'名称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
df_data = get_data(df)
df_data = pd.concat([df_data, df['公告时间']], axis=1)
df_data['公告时间'] = pd.to_datetime(df_data['公告时间'])
df_data['year'] = df_data['公告时间'].dt.year
df_data['year'] = df_data['year'] - 1
name = df_data['简称'][0]
df_data['简称'] = name
#该部分与解析深交所部分相同
p_zy = re.compile('.*?(摘要).*?')
for i in range(len(df_data)):
a = p_zy.findall(df_data['公告标题'][i])
if len(a) != 0:
df_data.drop([i],inplace = True)
df_data = df_data.reset_index(drop=True)
p_yw = re.compile('.*?(英文版).*?')
for i in range(len(df)):
a = p_yw.findall(df['公告标题'][i])
if len(a) != 0:
df.drop([i],inplace = True)
df = df.reset_index(drop=True)
p_nb = re.compile('.*?(年度报告).*?')
p_nb2 = re.compile('.*?(年报).*?')
for i in range(len(df_data)):
b1 = p_nb.findall(df_data['公告标题'][i])
b2 = p_nb2.findall(df_data['公告标题'][i])
if len(b1) == 0 and len(b2) == 0:
df_data.drop([i],inplace = True)
df_data = df_data.reset_index(drop=True)
p_bnb = re.compile('.*?(半年).*?')
for i in range(len(df_data)):
c = p_bnb.findall(df_data['公告标题'][i])
if len(c) != 0:
df_data.drop([i],inplace = True)
df_data = df_data.drop_duplicates('year', keep='first', inplace=False)
df_data = df_data.reset_index(drop=True)
df_data['year_str'] = df_data['year'].astype(str)
df_data['name'] = name + df_data['year_str'] + '年年报'
name1 = df_data['简称'][0]
df_data.to_csv('%scsv文件.csv'%name1)
os.mkdir('%s年度报告'%name)
os.chdir(r'C:\Users\20279\Desktop\水上运输业10年内年度报告\%s年度报告'%name)
for y in range(len(dy)):
y = int(y)
ye = dy['year'][y]
name1 = df_data['简称'][0]
rename = name1 + ye
for a in range(len(df_data)):
if df_data['name'][a] == '%s年年报'%rename:
href0 = df_data.iat[a,3]
r = requests.get(href0, allow_redirects=True)
f = open('%s年度报告.pdf'%rename, 'wb')
f.write(r.content)
f.close()
r.close()
通过找到上交所网站的不严谨之处,我可以直接从上交所直接下载十年的年报而不需要调整时间跨度。
但通过该方法所得到的公告标题中含有大量与年报无关的报告,因此需要将它们剔除。
首先剔除公告标题中含有‘摘要’的行,再只保留含有‘年报’或‘年度报告’的行,最后通过提取年份删除年份中的重复值并保留第一个来获得需要下载的年报名单。
上交所部分公告标题中不含有年份信息,因此需要通过上传年份减1,再对其重命名。下载报告方式与深交所部分相同。
hbcwsj = pd.DataFrame(index=range(2012,2021),columns=['营业收入','基本每股收益'])
hbsj = pd.DataFrame()
for i in range(len(hb1)):
name2 = hb1[2][i]
code = hb1['code'][i]
dcsv = pd.read_csv(r'C:\Users\20279\Desktop\水上运输业10年内年度报告\%scsv文件.csv'%name2)
dcsv['year_str'] = dcsv['year'].astype(str)
os.chdir(r'C:\Users\20279\Desktop\水上运输业10年内年度报告\%s年度报告'%name2)
for r in range(len(dcsv)):
year_int = dcsv.year[r]
if year_int >= 2012:
year2 = dcsv.year_str[r]
aba = name2 + year2
doc = fitz.open(r'%s年度报告.PDF'%aba)
text=''
for j in range(22):
page = doc[j]
text += page.get_text()
p_rev = re.compile('(?<=\n)营业.*?收入.*?\n([\d+,.]+).*?(?=\n)')
revenue = float(p_rev.search(text).group(1).replace(',',''))
p_eps = re.compile('(?<=\n)基\n?本\n?每\n?股\n?收\n?益.*?\n.*?\n?([-\d+,.]+)\s*?(?=\n)')
eps = float(p_eps.search(text).group(1))
p_web = re.compile('(?<=\n).*?网址.*?\n(.*?)(?=\n)')
web = p_web.search(text).group(1)
p_site = re.compile('(?<=\n).*?办公地址.*?\n(.*?)(?=\n)')
site = p_site.search(text).group(1)
hbcwsj.loc[year_int,'营业收入'] = revenue
hbcwsj.loc[year_int,'基本每股收益'] = eps
hbcwsj = hbcwsj.astype(float)
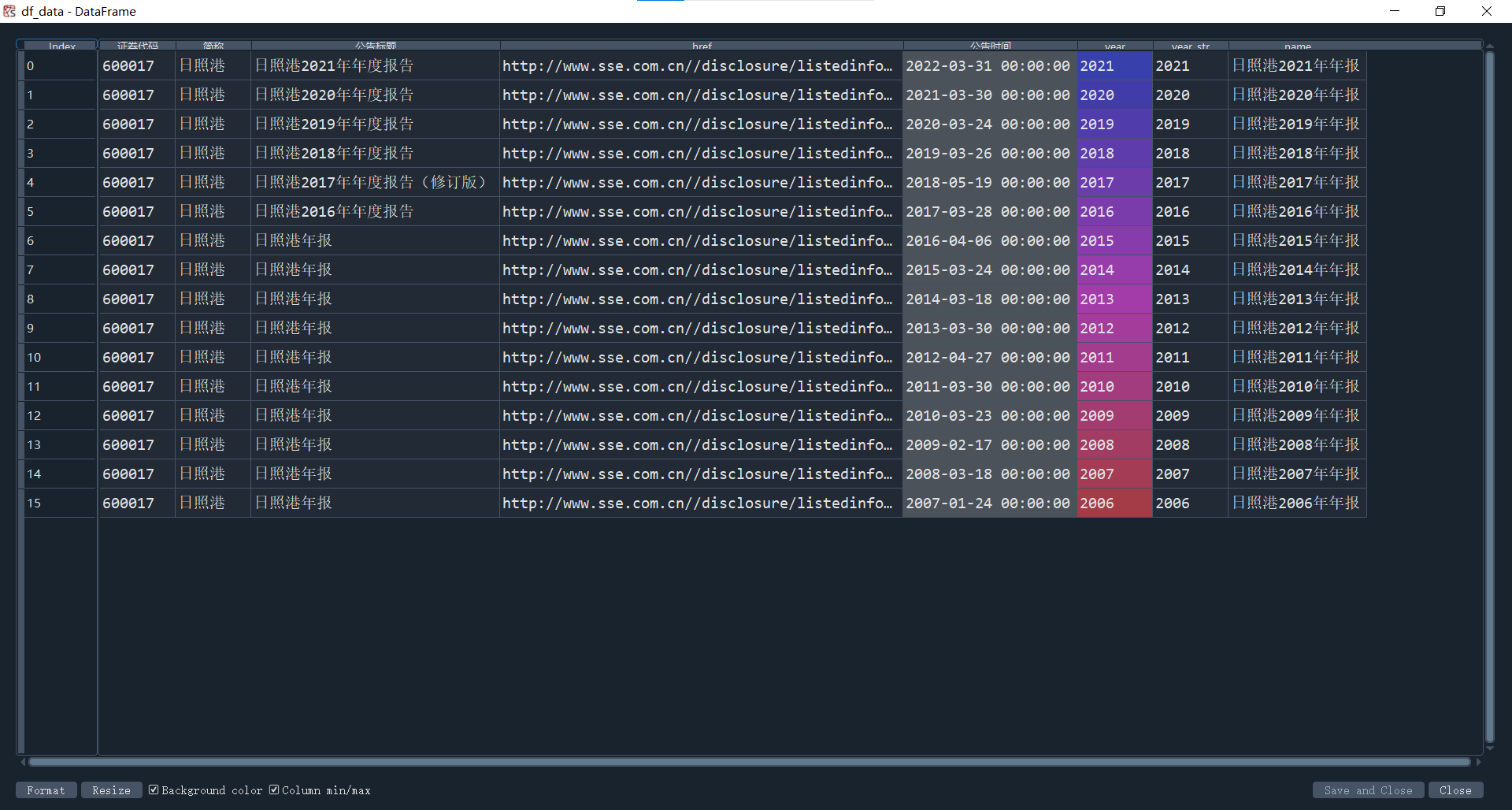
hbcwsj.to_csv(r'C:\Users\20279\Desktop\水上运输业10年内年度报告\%s财务数据.csv'%name2)
#将每家公司2021年的财务数据合并到一个dataframe中,以方便比较营业收入大小
hbsj = hbsj.append(hbcwsj.tail(1))
with open(r'C:\Users\20279\Desktop\水上运输业10年内年度报告\%s财务数据.csv'%name2, mode='a', encoding='utf-8') as f:
content='股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name2,code,site,web)
f.write(content)
结果实例如下图
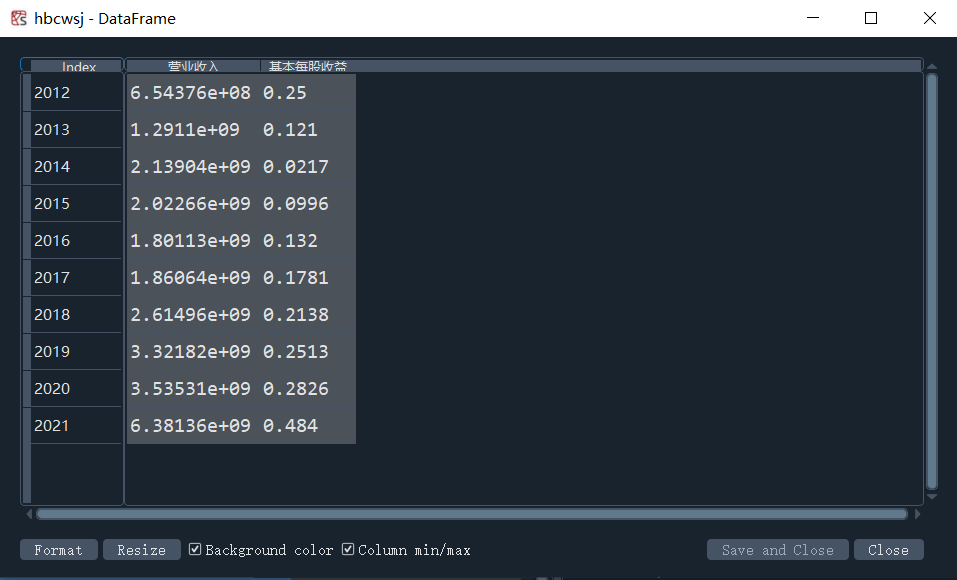
hbsj.index = Series(hb1[2])
hbsj.sort_values(by='营业收入',axis=0,ascending=True)
hbsj2 = hbsj.head(10)
hbsj2['name'] = hbsj2.index
hbsj2 = hbsj2.reset_index(drop=True)
plt.xlabel('年份')
plt.ylabel('营业收入')
plt.grid(True)
plt.title('十家营业收入最高的公司的收入走势图')
for i in range(len(hbsj2)):
name3 = hbsj2.name[i]
cwsj = pd.read_csv(r'C:\Users\20279\Desktop\水上运输业10年内年度报告\%s财务数据.csv'%name3)
cwsj = cwsj.iloc[:-3,]
cwsj.columns = ['year', 'rev', 'eps']
x = cwsj['year']
y = cwsj['rev']
plt.plot(x, y, label='%s'%name3, marker = 'o')
plt.legend(loc='upper left')
os.chdir(r'C:\Users\20279\Desktop\水上运输业10年内年度报告')
plt.savefig('十家营业收入最高的公司的收入走势图')
plt.clf()
plt.xlabel('年份')
plt.ylabel('eps')
plt.grid(True)
plt.title('十家营业收入最高的公司的eps走势图')
for i in range(len(hbsj2)):
name3 = hbsj2.name[i]
cwsj = pd.read_csv(r'C:\Users\20279\Desktop\水上运输业10年内年度报告\%s财务数据.csv'%name3)
cwsj.columns = ['year', 'rev', 'eps']
x = cwsj['year']
y = cwsj['eps']
plt.plot(x, y, label='%s'%name3, marker = 'o')
plt.legend(loc='upper left')
plt.savefig('十家营业收入最高的公司的eps走势图')
plt.clf()
结果如下图
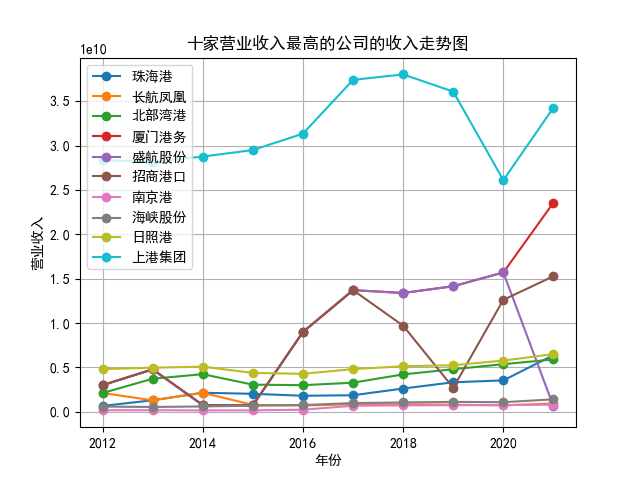
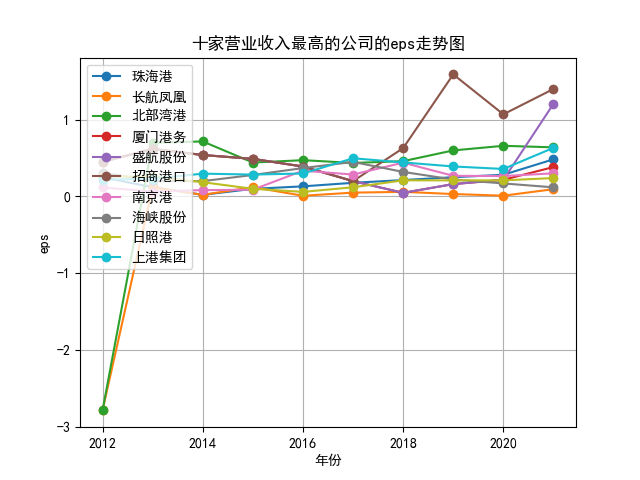
①在定义工作路径可以使用子文件夹和父文件夹的方法而不是每次重新定义。 ②部分步骤应改成函数形式如筛选需要下载的年报,从而方便调用也使得代码不那么臃肿。 ③变量命名需更有条理。
在下载年报的过程中,采用上传时间先后顺序来判断哪份年报是需要下载的思路有时候会出错。 部分公司在上传最终版年报后可能会继续上传英文版和繁体字版的年报,并且不会在公告标题处表明,这时下载的年报将无法解析。 对于该问题我的解决方法为手动替换。