import re
import os
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from time import sleep
from selenium.webdriver.common.action_chains import ActionChains
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?) ', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
driver_url = r"C:\edgedriver_win64\msedgedriver.exe"
prefs = {'profile.default_content_settings.popups': 0,
'download.default_directory':r'D:\从C盘移过来的\havdif\Desktop\python\金融数据获取\现代投资'}
options = webdriver.EdgeOptions()
options.add_experimental_option('prefs', prefs)
browser = webdriver.Edge(executable_path=driver_url, options=options)
browser.get('http://www.szse.cn/disclosure/listed/fixed/index.html')
element = browser.find_element(By.ID, 'input_code') # Find the search box
element.send_keys('现代投资' + Keys.RETURN)
browser.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
browser.find_element(By.LINK_TEXT, "年度报告").click()
data_ele = browser.find_element(By.ID, 'disclosure-table')
innerHTML = data_ele.get_attribute('innerHTML')
f = open('innerHTML.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
# html = to_pretty('innerHTML.html')
w = open('innerHTML.html',encoding='utf-8')
html = w.read()
w.close()
dt = DisclosureTable(html)
df = dt.get_data()
df.to_csv('data.csv')
for i in range(len(df['attachpath'])):
download_link = df['attachpath'][i]
browser.get(download_link)
browser.quit()
(1)首先导入模块环境。
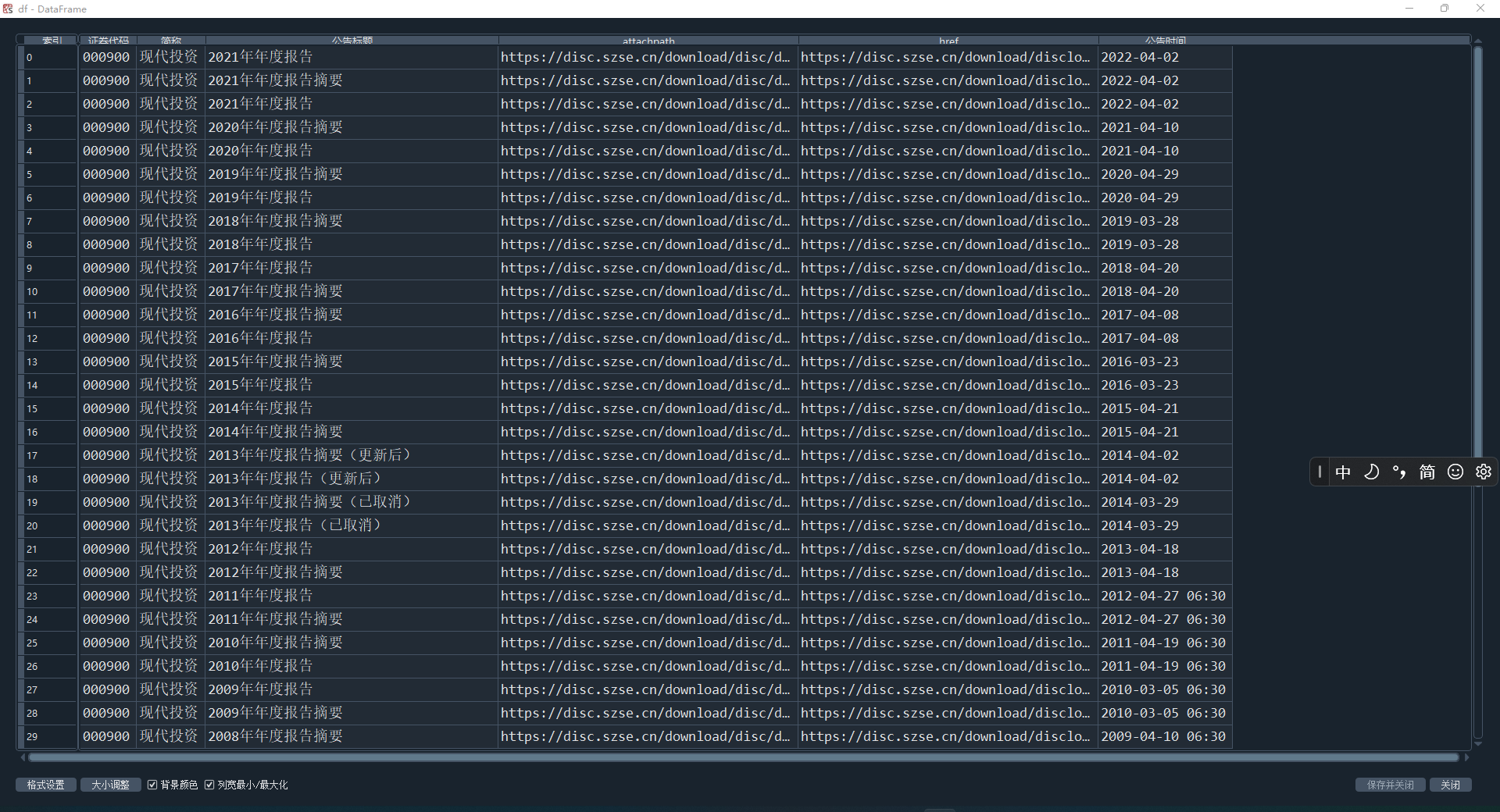
(2)定义一个类,类中包含多个函数变量,利用这些函数可以拆解提取深交所html内容 (主要是disclosure—table中的行业代码、行业名称、公告标题、简称等等,其中通过 定义herf前缀以及通过提取后缀可以合成行业报告的下载地址,以此合成的Dataframe为基本 出发点,可以通过循环下载年报)。
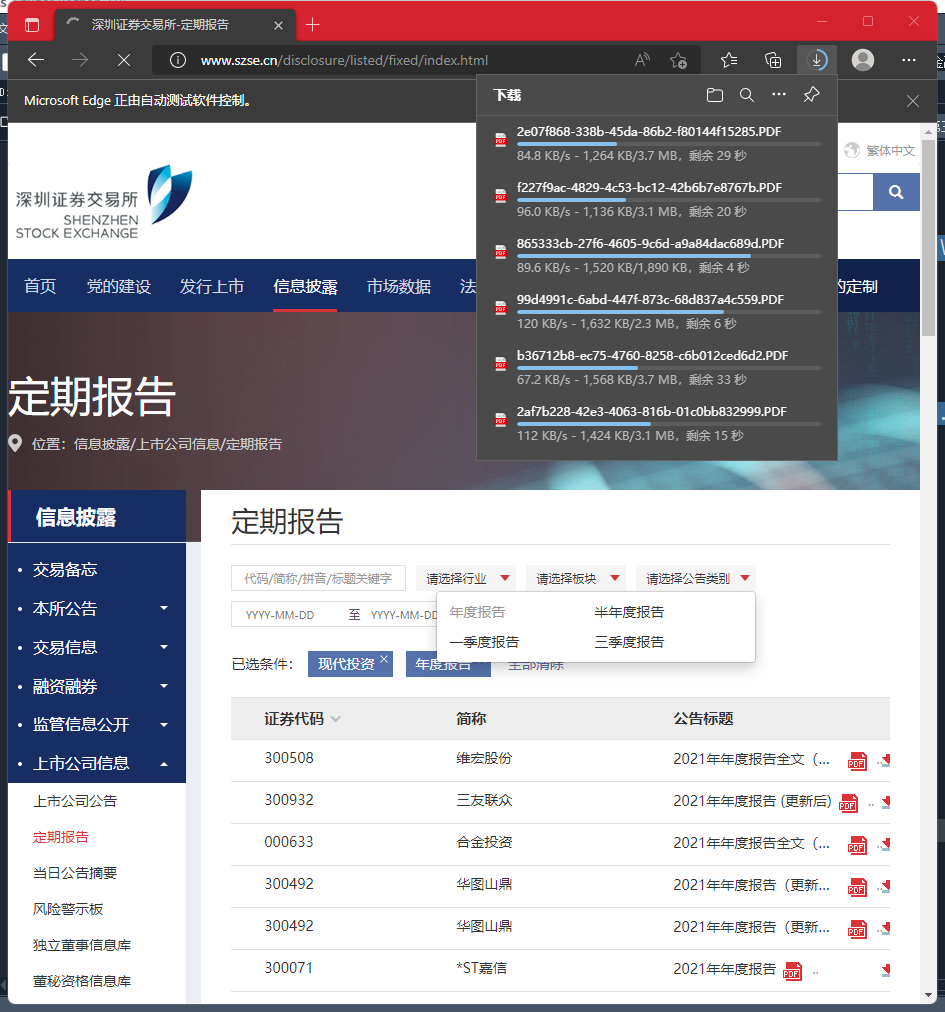
(3)定义Webdriver的驱动路径,并通过定义一个prefs将其与自定义下载路径相匹配, 获取Microsoft的下载路径,并将prefs赋予给路径选择,在驱动时确定这一下载路径,并匹配 driver网页下载路径为“http://www.szse.cn/disclosure/listed/fixed/index.html”
(4)通过By模块定位id为‘input_code’的搜索框,并输入返回‘现代投资’然后同样的选择 报告类型为年度报告。
(5)在筛选条件完成后,爬取disclosure—table的内容,创建新文件命名为‘inneHTML.html’, 并将内容写入后关闭。
(6)定义w读取innerHTML.html的内容,然后利用DisclosureTable类处理内容,得到DataFrame, 并将内容保存在csv文件中,然后循环获取数据表中attachpath的内容并利用webdriver爬取获得报告, 完成后关闭浏览器。