#第一部分代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
browser = webdriver.Chrome()#点开Chorme
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')#打开深交所网页
element = browser.find_element(By.ID, 'input_code')
element.send_keys('浙江建投' + Keys.RETURN)
element = browser.find_element(By.ID, 'disclosure-table')
innerHTML = element.get_attribute('innerHTML')
f = open('innerHTML.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
browser.quit()
#第二部分代码
from bs4 import BeautifulSoup
import re
import pandas as pd
def to_pretty(fhtml):
f = open(fhtml,encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open(fhtml[0:-5]+'-prettified.html', 'w', encoding='utf-8')
f.write(html_prettified)
f.close()
return(html_prettified)
html = to_pretty('innerHTML.html')
def txt_to_df(html):
# html table text to DataFrame
p = re.compile('(.*?) ', re.DOTALL)#re.DOTALL 匹配包括换行在内的所有字符
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
return(df)
df_txt = txt_to_df(html)
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
get_code = lambda txt: p_a.search(txt).group(1).strip()
get_time = lambda txt: p_span.search(txt).group(1).strip()
def get_link(txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(df_txt):
prefix = 'https://disc.szse.cn/download'
prefix_href = 'https://www.szse.cn/'
df = df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
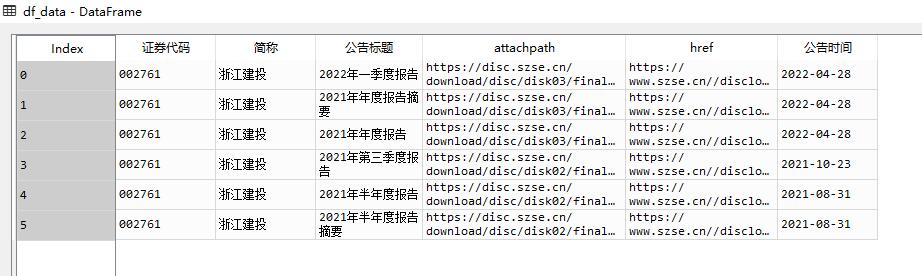
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
return(df)
df_data = get_data(df_txt)
df_data.to_csv('data_浙江建投.csv')
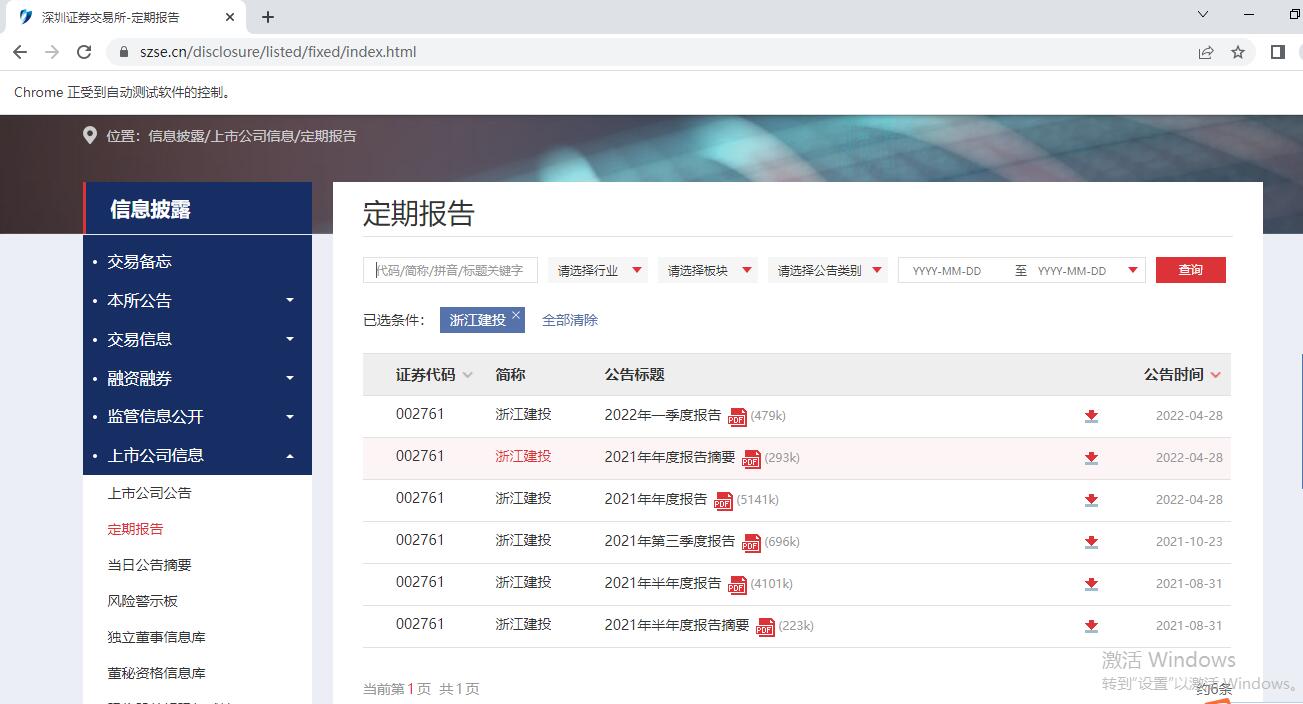
第一部分代码主要是运用seleium模块控制浏览器进行一些输入,点击,跳转等操作。通过网络检查,找到搜索框对应的标签是input_code,选择对应行业中的任意一个上市公司,例如浙江建投。获取浙江建投所披露的所有年报信息并保存为innerHTML,而后以编码‘utf-8’的形式写入新文件,最后关闭网页。
第二部分代码主要是运用BeautifulSoup模块和re模块,运用bs4提取HTML中的数据进行分析,而处理数据过程中主要运用正则表达式的re模块。通过网页检查,寻找需要的标题所在的标签对,而后定义函数,反复使用正则表达式的提取作用和非捕获模式提取出'证券代码''简称''公告标题''attachpath''href''公告时间'等内容,最后将提取出的数据存入'data_浙江建投'文件。