导入相应模块,按上交所和深交所分别获取所属行业的公司相关信息
from bs4 import BeautifulSoup
import re
import pdfplumber
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
page = pdfplumber.open("D:\行业PDF.pdf").pages[74] #获取第2页
table = page.extract_table()
stock = pd.DataFrame(table)
stock.columns = ['行业','行业代码','行业名称','公司代码','公司名称']
stock = stock.fillna(method='ffill')
stock = stock.iloc[1:,]
stock1 = pd.DataFrame(stock.loc[:,'行业代码'])
stock2 = pd.DataFrame(stock.loc[:,'公司代码'])
stock3 = pd.DataFrame(stock.loc[:,'公司名称'])
stock = stock1.join(stock2)
stock = stock.join(stock3)
stock.index = stock['公司代码']
stock = stock.loc['000407':'605368',]
stock.to_excel('stock_final.xlsx')
stock_sz = stock.loc['000407':'300435',]
stock_sh = stock.loc['600207':'605368',]
结果
爬取深交所网页
import time
for i in range(0,len(stock_sz)):
browser = webdriver.Chrome()
browser.get('http://www.szse.cn/disclosure/listed/fixed/index.html')
time.sleep(2)
element = browser.find_element(By.ID,'input_code')
browser.find_element(By.LINK_TEXT,'请选择公告类别').click()
browser.find_element(By.LINK_TEXT,'年度报告').click()
element = browser.find_element(By.ID,'input_code')
element.send_keys(stock_sz.iloc[i,1] )
time.sleep(2)
element.send_keys(Keys.ENTER)
browser.find_element(By.CSS_SELECTOR, ".input-left").click()
browser.find_element(By.CSS_SELECTOR, ".input-left").send_keys("2013-01-01")
browser.find_element(By.CSS_SELECTOR, ".input-right").click()
browser.find_element(By.CSS_SELECTOR, ".input-right").send_keys("2022-06-01")
browser.find_element(By.ID, "query-btn").click()
element = browser.find_element(By.ID,"disclosure-table")
time.sleep(2)
innerHTML = element.get_attribute("innerHTML")
time.sleep(2)
f = open("深交所年报.html",'a',encoding='utf-8')
f.write(innerHTML)
time.sleep(2)
f.close()
browser.find_element(By.CSS_SELECTOR, ".btn-clearall").click()
browser.quit()
time.sleep(2)
#对所爬取的网页进行处理
def to_pretty(fhtml):
f = open(fhtml,encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open(fhtml[0:-5]+'-prettified.html', 'w', encoding='utf-8')
f.write(html_prettified)
f.close()
return(html_prettified)
html = to_pretty('深交所年报.html')
def txt_to_df(html):
# html table text to DataFrame
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds1 = [p2.findall(tr) for tr in trs[1:]]
tds = list(filter(None, tds1))
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
return(df)
df_txt = txt_to_df(html)
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
get_code = lambda txt: p_a.search(txt).group(1).strip()
get_time = lambda txt: p_span.search(txt).group(1).strip()
def get_link(txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(df_txt):
prefix = 'https://disc.szse.cn/download'
prefix_href = 'https://www.szse.cn/'
df = df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
return(df)
df = get_data(df_txt)
#过滤年报摘要与已取消的年报
def tidy(df):
d = []
for index, row in df.iterrows():
title = row[2]
a = re.search("摘要|取消", title)
if a != None:
d.append(index)
name=row[1]
df1 = df.drop(d).reset_index(drop = True)
return df1
df = tidy(df)
#下载年报
import requests
for i in range (0,92):
r = requests.get(df['attachpath'][i], allow_redirects=True)
time.sleep(2)
f = open(df['证券代码'][i]+df['公告标题'][i]+'.pdf', 'wb')
f.write(r.content)
f.close()
r.close()
如图

爬取上交所网页
for i in range(0,len(stock_sh)):
browser = webdriver.Chrome()
browser.get("http://www.sse.com.cn/disclosure/listedinfo/regular/")
browser.find_element(By.ID, "inputCode").click()
element = browser.find_element(By.ID, "inputCode").send_keys(stock_sh.iloc[i,1])
time.sleep(2)
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
time.sleep(2)
browser.find_element(By.LINK_TEXT, "年报").click()
time.sleep(2)
# dropdown = browser.find_element(By.CSS_SELECTOR, ".show > .selectpicker")
# dropdown.find_element(By.XPATH, "//option[. = '年报']").click()
time.sleep(2)
element = browser.find_element(By.CLASS_NAME, 'table-responsive')
time.sleep(2)
innerHTML = element.get_attribute("innerHTML")
time.sleep(2)
f1 = open("上交所年报.html",'a',encoding='utf-8')
f1.write(innerHTML)
time.sleep(2)
browser.quit()
#对所爬取的网页进行处理
def to_pretty(fhtml):
f = open(fhtml,encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open(fhtml[0:-5]+'-prettified.html', 'w', encoding='utf-8')
f.write(html_prettified)
f.close()
return(html_prettified)
html = to_pretty('上交所年报.html')
def txt_to_df(html):
# html table text to DataFrame
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds1 = [p2.findall(tr) for tr in trs[1:]]
tds = list(filter(None, tds1))
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
return(df)
df_txt = txt_to_df(html)
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
p_space=re.compile('\s+(.*?)\s+',re.DOTALL)
get_a= lambda txt: p_a.search(txt).group(1).strip()
get_span = lambda txt: p_span.search(txt).group(1).strip()
get_space = lambda txt: p_space.search(txt).group(1).strip()
def get_link2(txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
href = matchObj.group(1).strip()
title = matchObj.group(2).strip()
return([href, title])
def get_data2(df_txt):
prefix_href = 'http://static.sse.com.cn/'
df = df_txt
codes = [get_span(td) for td in df['证券代码']]
short_names = [get_span(td) for td in df['简称']]
ahts = [get_link2(td) for td in df['公告标题']]
times = [get_space(td) for td in df['公告时间']]
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[1] for aht in ahts],
'href': [prefix_href + aht[0] for aht in ahts],
'公告时间': times
})
return(df)
df = get_data2(df_txt)
#过滤年报摘要与已取消的年报
def tidy(df):
d = []
for index, row in df.iterrows():
title = row[2]
a = re.search("摘要|取消", title)
if a != None:
d.append(index)
name=row[1]
df1 = df.drop(d).reset_index(drop = True)
return df1
df1 = tidy(df)
#下载上交所年报
import requests
for i in range (0,168):
href=df1.iloc[i,3]
r = requests.get(href, allow_redirects=True)
time.sleep(2)
f = open(df1['证券代码'][i]+df1['公告时间'][i]+'.pdf', 'wb')
f.write(r.content)
f.close()
r.close()
如图所示
导入相应模块,定义获取年报的函数,用正则表达式来提取年报中的营业收入和基本每股收益
import fitz
import re
import os
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
#合并所有公司的股票代码和简称
sj = pd.concat([stock_sz,stock_sh])
sj.reset_index(drop=True)
sj.to_csv(r"C:\Users\24078\Desktop\sj.csv")
如图所示
定义函数,获取年报中的营业收入
def getText(pdf):#定义函数获取文本
text = ''
doc = fitz.open(pdf)
for page in doc:
text += page.get_text()
doc.close()
text = text.replace(" "," \n")
text = text.replace("\n\n","\n")#由于后续subp匹配过程中,有的数字后面没有换行符,无法成功进行非贪婪的匹配,所以通过文本内部符号替换
return(text)
def get_content(pdf):#定义函数获取营业收入所在年报内容的位置
text = getText(pdf)
p = re.compile('(?<=\\n)\D、\s*\D*?主要\D*?数据\D*?\s*(?=\\n)(.*?)经营活动产生的',re.DOTALL)#定位各个年报固定位置的内容
content = p.search(text).group(0)
return(content)
def parse_data_line(pdf):#定义函数单独提取营业收入所在行的内容
content = get_content(pdf)
subp = "([0-9,.%\- ]*?)\n"
psub = "%s%s%s%s" % (subp,subp,subp,subp)
p =re.compile("(?<=\\n)营业(\D*?\n)+%s" % psub)#定义营业收入那一行的内容
lines = p.search(content)
lines = lines[0]#形成列表内容
return(lines)
#获取基本每股收益
def get_profit(pdf):
text = getText(pdf)
p = re.compile('(?<=\\n)\D、\s*\D*?主要\D*?指标\D*?\s*(?=\\n)(.*?)稀释每股',re.DOTALL)
profit = p.search(text).group(0)
return(profit)
def profit_data_line(pdf):
profit = get_profit(pdf)
subp = "([0-9,.%\- ]*?)\n"
psub = "%s%s%s%s" % (subp,subp,subp,subp)
p =re.compile("(?<=\\n)基本每股收益(\D*?\n)+%s" % psub)#定义每股收益那一行的内容
lines_profit = p.search(profit)
lines_profit = lines_profit[0]#形成列表内容
return(lines_profit)
#循环获取营业收入
df_sale = pd.DataFrame()#创建一个空表格
path = "C:\\Users\\24078\\gp"
os.chdir(path)
wjj = os.listdir(path)
for info in wjj:
domain = os.path.abspath(path) #获取文件夹的路径
info = os.path.join(domain,info) #完整路径
ste = info[-6:]#将公司名称赋给ste
filenames = os.listdir(ste)#获取各个公司文件夹中pdf文件的名称
sale = []
for pdf in filenames:
i=0
df = pd.DataFrame()#创建一个空表格
ste="\\"+ste
pdf = "\\"+pdf
x = "C:\\Users\\24078\\gp"+ste+pdf#形成路径链接(直接用pdf会打不开)
sale_gain = parse_data_line(x)
sale_gain = sale_gain.split("\n")#将列表里的字符串以换行符进行分割,形成新的列表
sale_gain = sale_gain[1]#取列表中第二个字符串,即营业收入
sale.append(sale_gain)#将营业收入放入新的列表
df.insert(i, ste, sale)#以列为单位加入表格
i=i+1
df_sale = df_sale.join(df, how='outer')
print('循环结束')
os.chdir("C:\\Users\\24078")
index1 = ['2012营业收入','2013营业收入','2014营业收入','2015营业收入','2016营业收入',\
'2017营业收入','2018营业收入','2019营业收入','2020营业收入','2021营业收入']
df_sale_T = pd.DataFrame(df_sale.values.T,columns=index1,index=df_sale.columns)
df_sale_T.to_csv("C:\\Users\\24078\\营业收入.csv")
营业收入如下所示
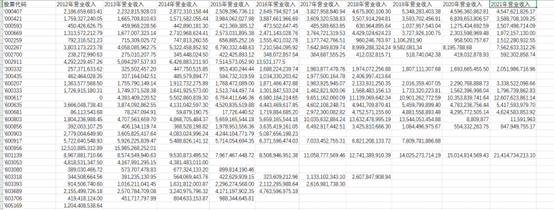
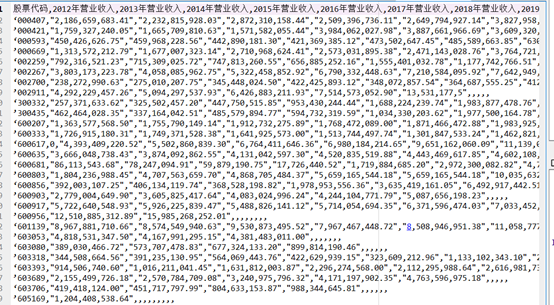
循环获取基本每股收益
df_profit = pd.DataFrame()
path = "C:\\Users\\24078\\gp"
os.chdir(path)
wjj = os.listdir(path)
for info in wjj:
domain = os.path.abspath(path) #获取文件夹的路径
info = os.path.join(domain,info) #完整路径
ste = info[-6:]
filenames = os.listdir(ste)#获取各个公司文件夹中pdf文件的名称
profit = []
for pdf in filenames:
i=0
df1 = pd.DataFrame()
ste='\\'+ste
pdf = "\\"+pdf
x = "C:\\Users\\24078\\gp"+ste+pdf#形成路径链接
profit_gain = profit_data_line(x)
profit_gain = profit_gain.split("\n")
profit_gain = profit_gain[1]
profit.append(profit_gain)
df1.insert(i, ste, profit)
i=i+1
df_profit = df_profit.join(df1, how='outer')
print('循环结束')
os.chdir("C:\\Users\\24078")
index2 = ['2012每股收益','2013每股收益','2014每股收益','2015每股收益','2016每股收益',\
'2017每股收益','2018每股收益','2019每股收益','2020每股收益','2021每股收益']
df_profit_T = pd.DataFrame(df_profit.values.T,columns=index2,index=df_profit.columns)
df_profit_T.to_csv("C:\\Users\\24078\\pf.csv")
基本每股收益结果
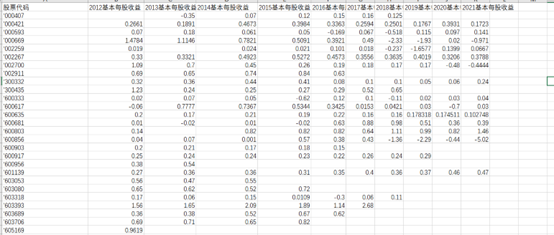
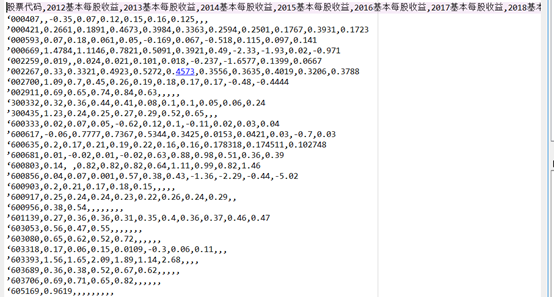
提取办公地址,公司网址
index_site = sj['公司代码'].drop_duplicates()
index_web = sj['公司代码'].drop_duplicates()
df_st = pd.DataFrame()#创建一个空表格
df_wb = pd.DataFrame()#创建一个空表格
filenames = os.listdir('C:\\Users\\24078\\2021年报')
st = []
wb = []
for pdf in filenames:
i=0
df2 = pd.DataFrame()#创建一个空表格
df3 = pd.DataFrame()
pdf = "\\"+pdf
x = "C:\\Users\\24078\\2021年报"+pdf#形成路径链接(直接用pdf会打不开)
text =getText(x)
p_site = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
site1 = p_site.search(text).group(0)
st.append(site1)
p_web = re.compile('(?<=\n)公司\w*网\s?址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
wb1 = p_web.search(text).group(0)
wb.append(wb1)
df2.insert(i,'办公地址' , st)#以列为单位加入表格
df3.insert(i,'网址', wb)
i=i+1
df_site = df_st.join(df2, how='outer')
df_web = df_wb.join(df3, how='outer')
df_site.index =index_site
df_web.index =index_web
df_site.to_csv("C:\\Users\\24078\\办公地址.csv")
df_web.to_csv("C:\\Users\\24078\\公司网址.csv")
办公地址结果如下
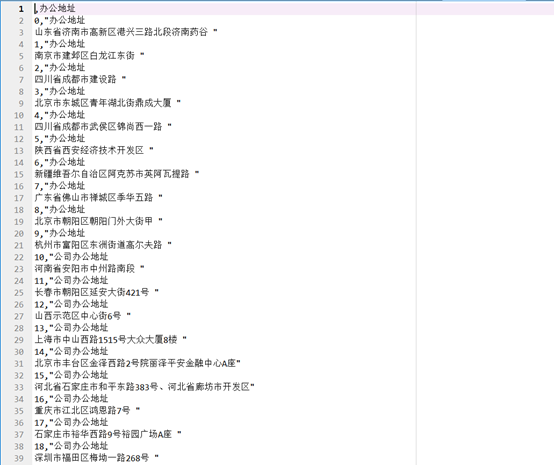
公司网址结果如下
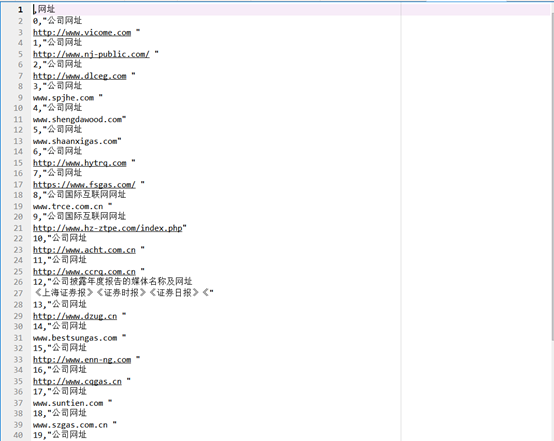
以下为绘制营业收入随时间的变化趋势图及其对比图
import matplotlib.pyplot as plt
import pandas as pd
from matplotlib.pyplot import MultipleLocator
import os
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
#导入营业收入数据,并分别按行提取和按列提取数据
sj_df1 = pd.read_csv("C:\\Users\\24078\\营业收入.csv")
sj_df2 = pd.DataFrame(sj_df1)
sj_df3 = sj_df2.iloc[8:18,1:]
sj_df4 = sj_df2.iloc[8:18,]
sj_df3.reset_index(drop=True)
list_row = sj_df3.values.tolist()#以行为单位取成列表,每个列表是十年同一公司的营业收入
#list_name = sj_df4['股票代码']#取索引
#print(list_name)
columns = list(sj_df3)
list_columns = []#以列为单位取的列表,每个都是每一年十家公司的营业收入
for c in columns:
d = sj_df3[c].values.tolist()
list_columns.append(d)#以列为单位取成列表
#将数据转化为以亿元为单位的浮点数
def change_type(list_x):
list_want=[]
for i in range(len(list_x)):
x_a = []
for j in range(len(list_x[1])):
a_a = list_x[i][j]
a_b = a_a.replace(",","")#将字符串中的,替换为空格
a_c = float(a_b)
a_d = a_c / 10**8#将数值缩小为亿分之一,便于在后续图标上展示
a_e = round(a_d,2)#保留两位小数
x_a.append(a_e)
list_want.append(x_a)
return(list_want)
list_row_1 = change_type(list_row)
list_columns_1 = change_type(list_columns)
os.chdir('..\\')#为了后续将图片保存在父文件夹中
name_list = ['2012',"2013","2014","2015","2016","2017","2018","2019",'2020','2021']
list_name_1 = ['300332','300435',"600207","600333",'600617',"600635","600681","600803","600856",'600903']
def y_ticks(list_row,list_name_1):
num_list_1 = list_row
rects = plt.barh(range(len(list_row)),num_list_1,color='rgby')
N = 10
index = np.arange(N)
plt.yticks(index,name_list)
plt.title(list_name_1+" 2012—2021营业收入对比")
plt.xlabel("营业收入(亿元)")
plt.ylabel("年份")
for rect in rects:
w=rect.get_width()
plt.text(w,rect.get_y()+rect.get_height()/2,w,size =10,ha='left',va='center')
plt.savefig(list_name_1 +".png",dpi = 600)
plt.show()
for i in range(len(list_row)):
y_ticks(list_row_1[i], list_name_1[i])
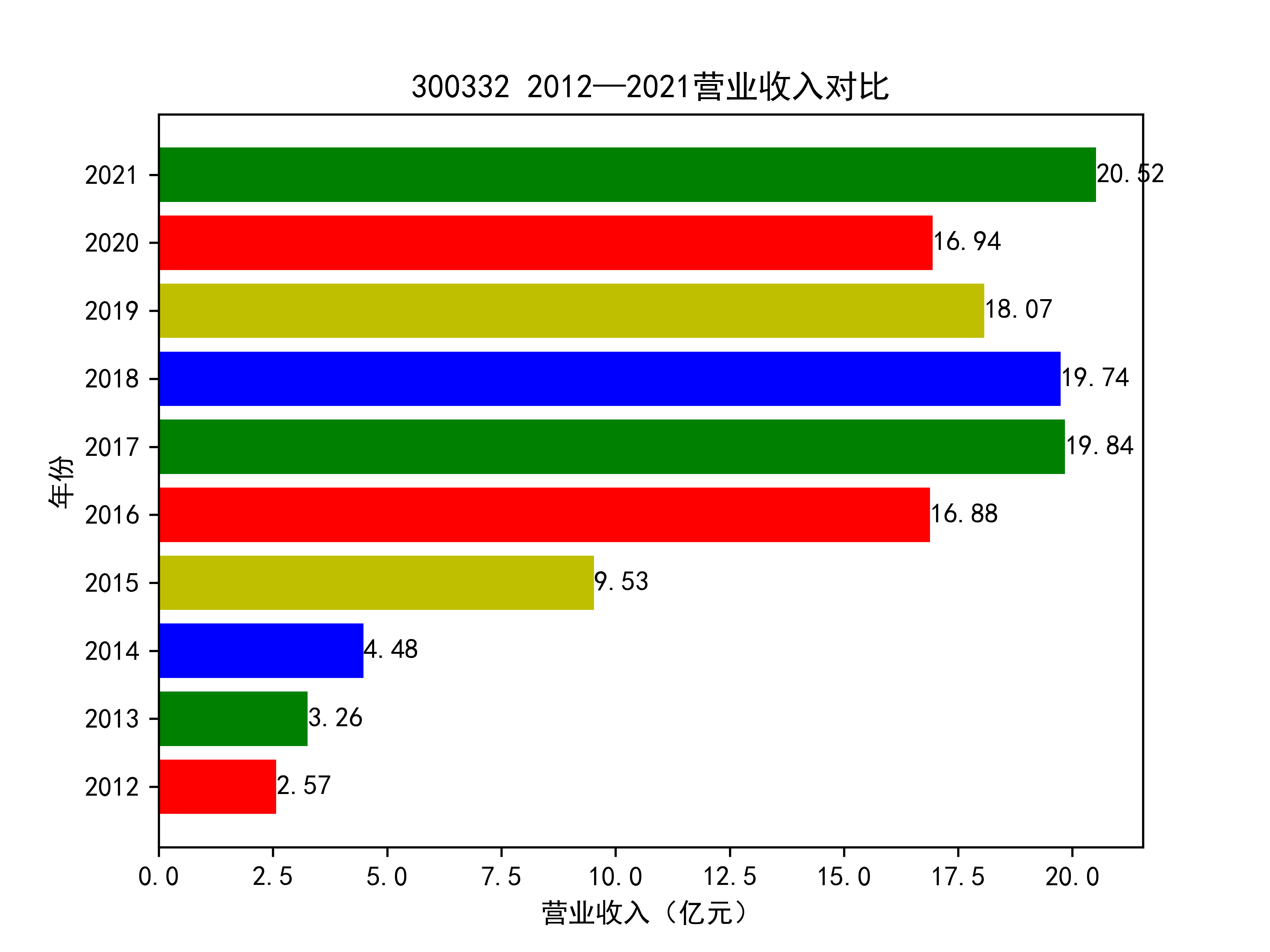
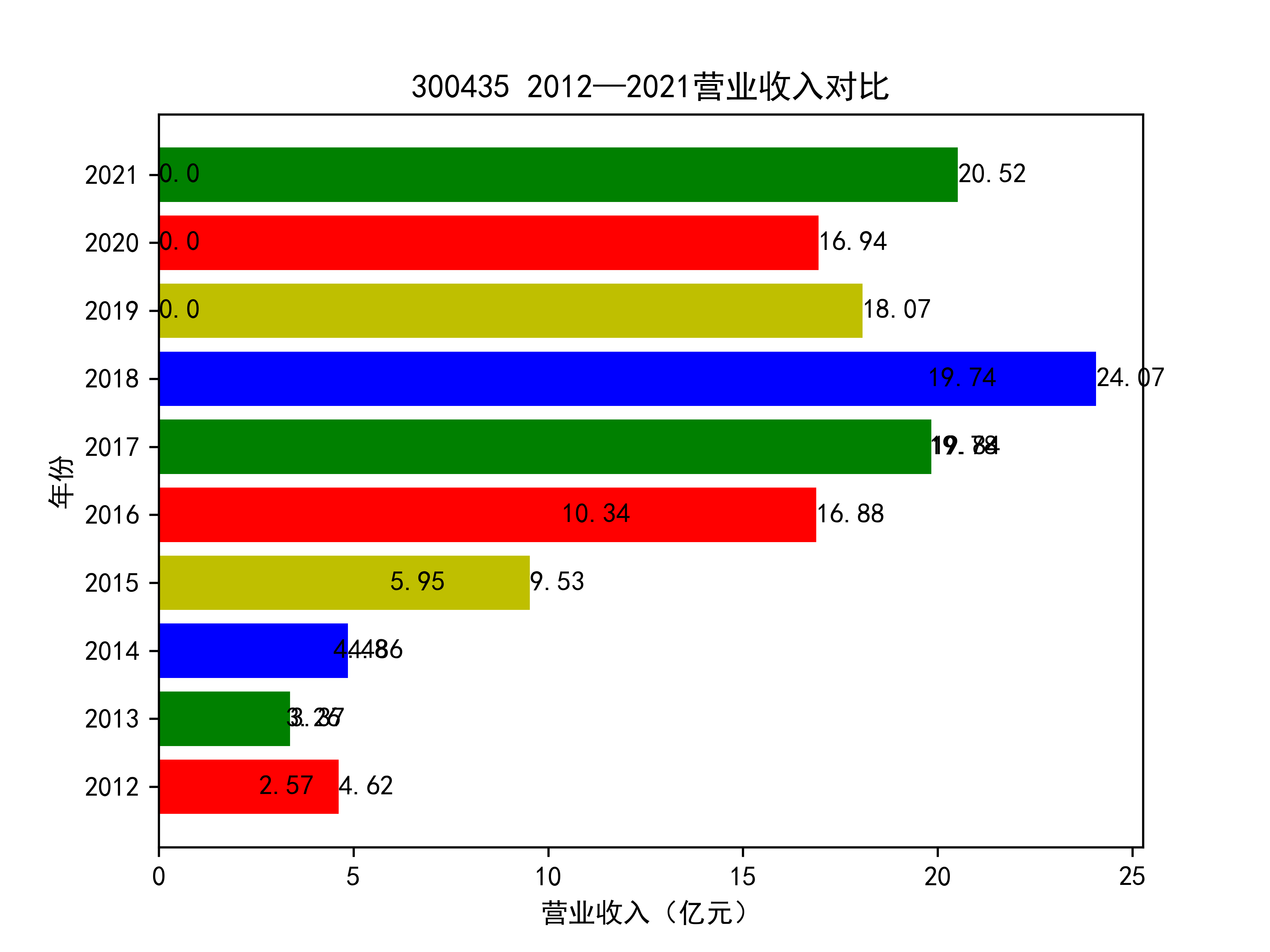
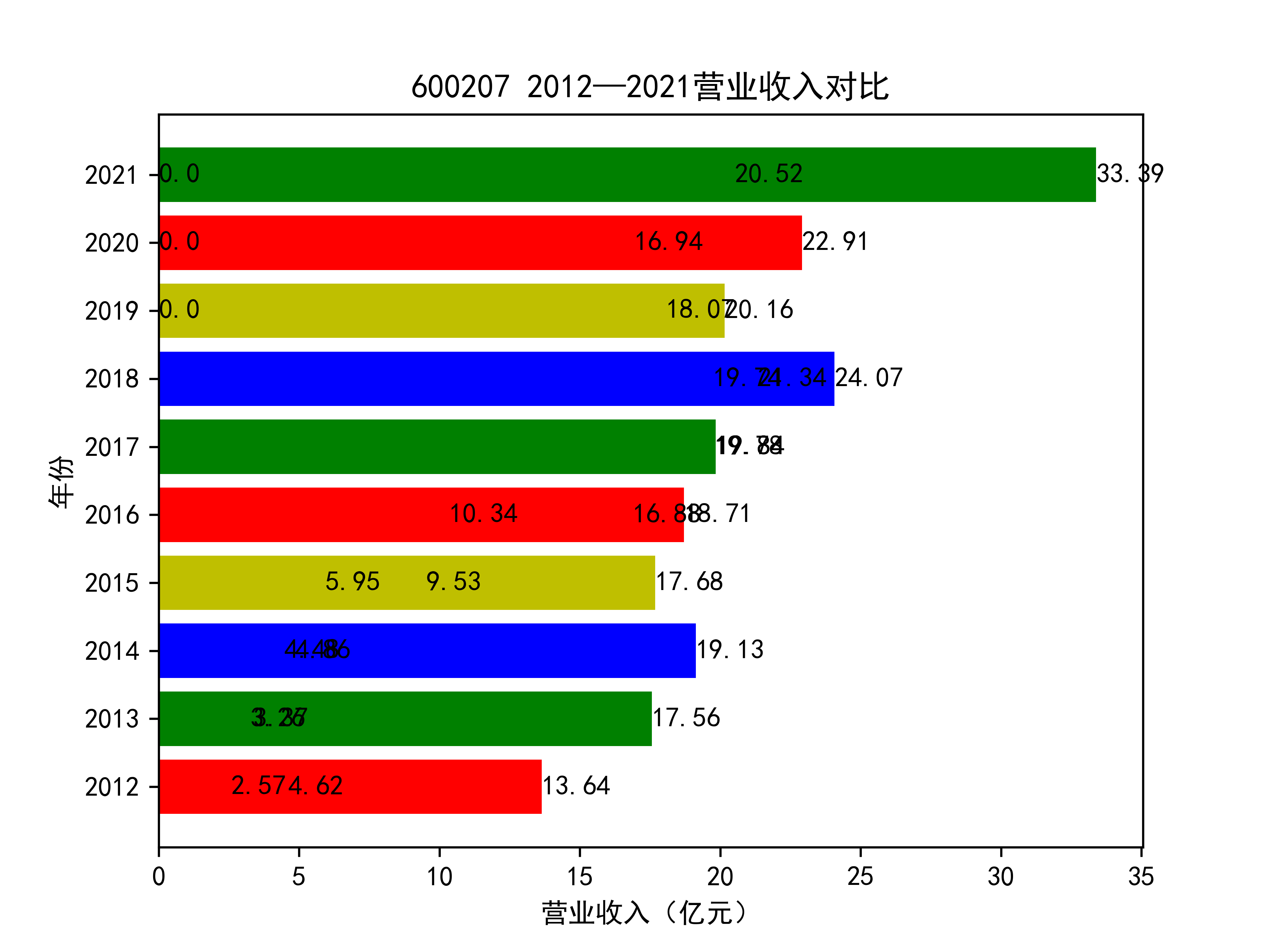
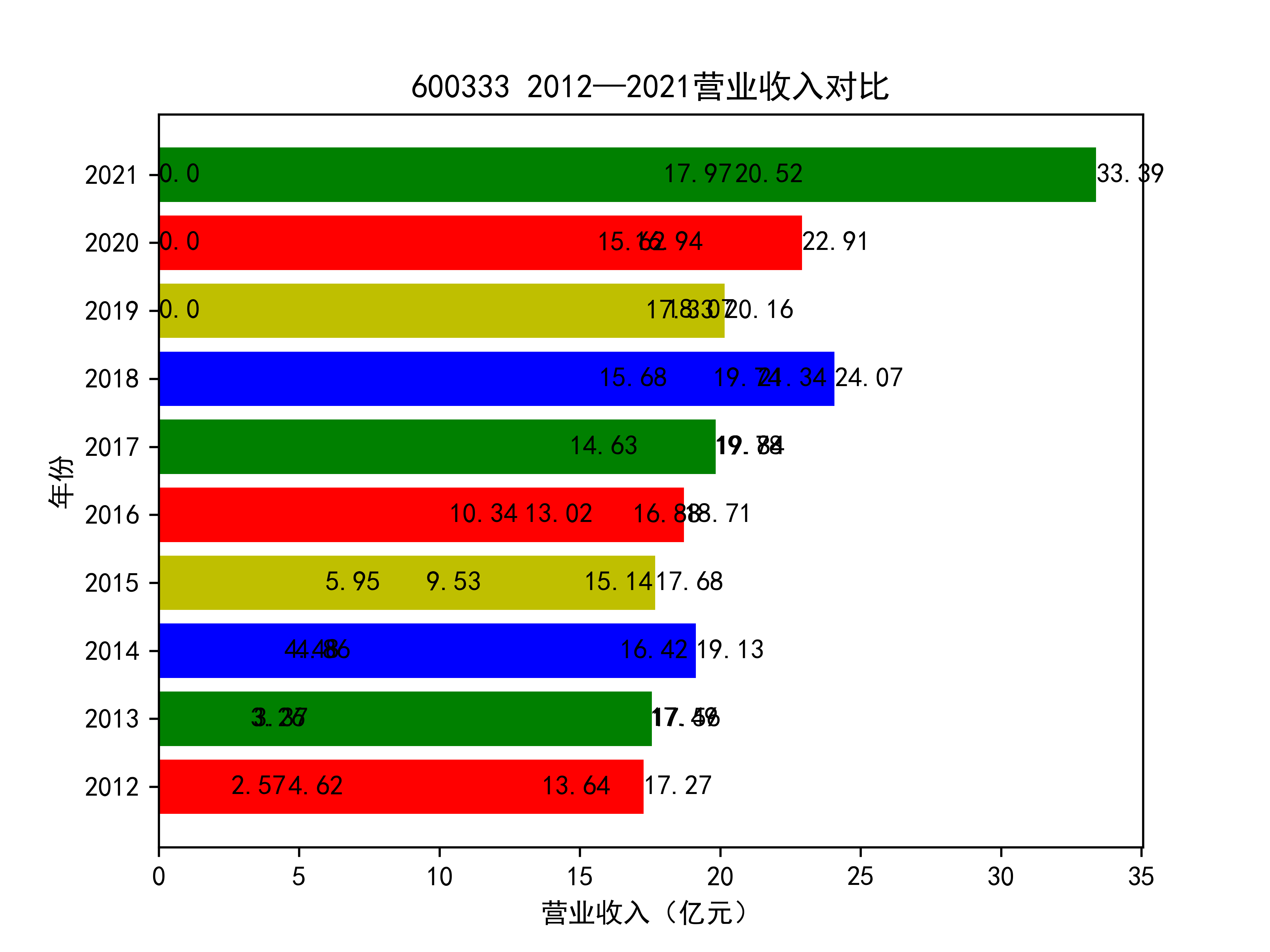
结果如图所示
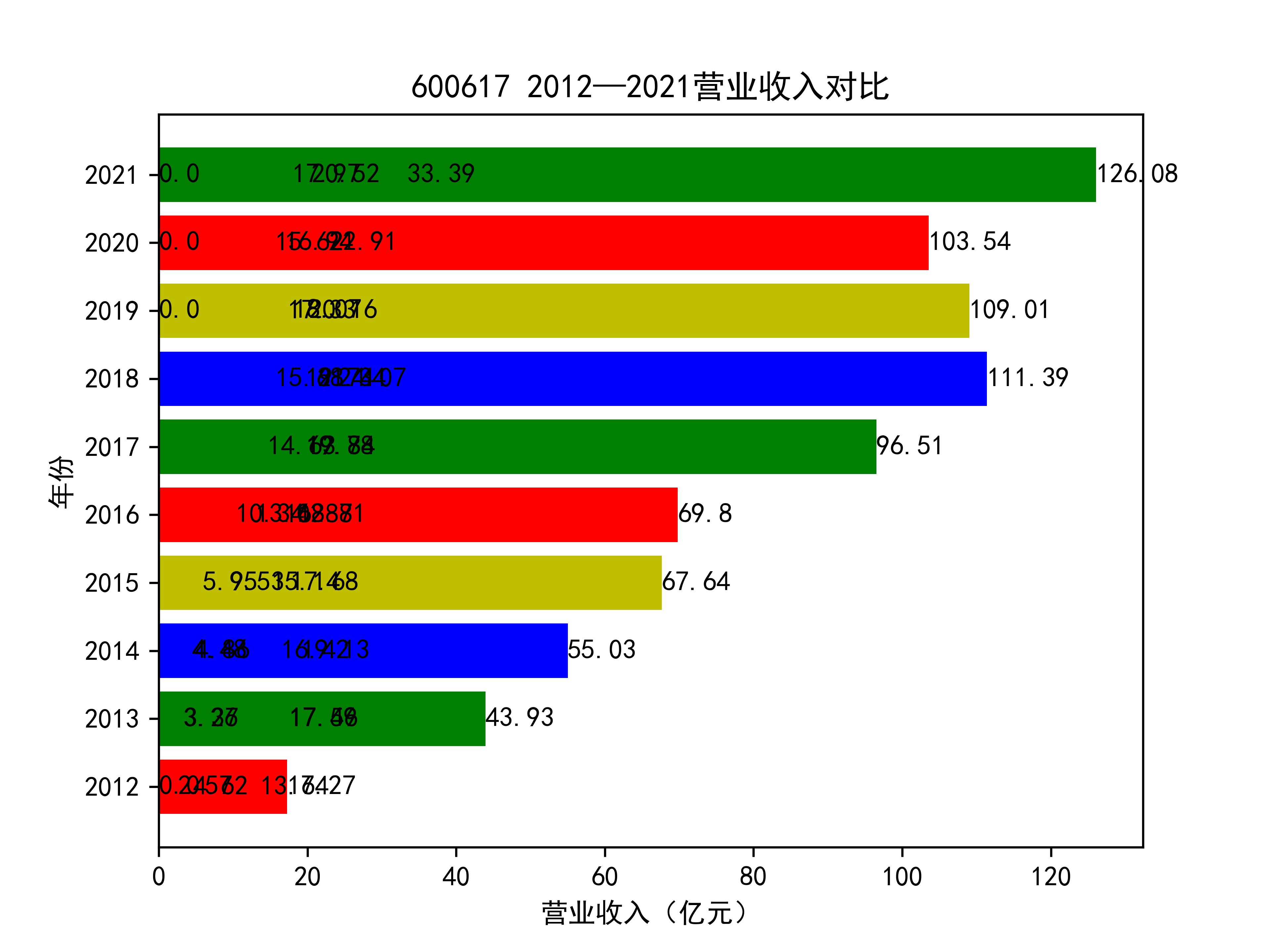
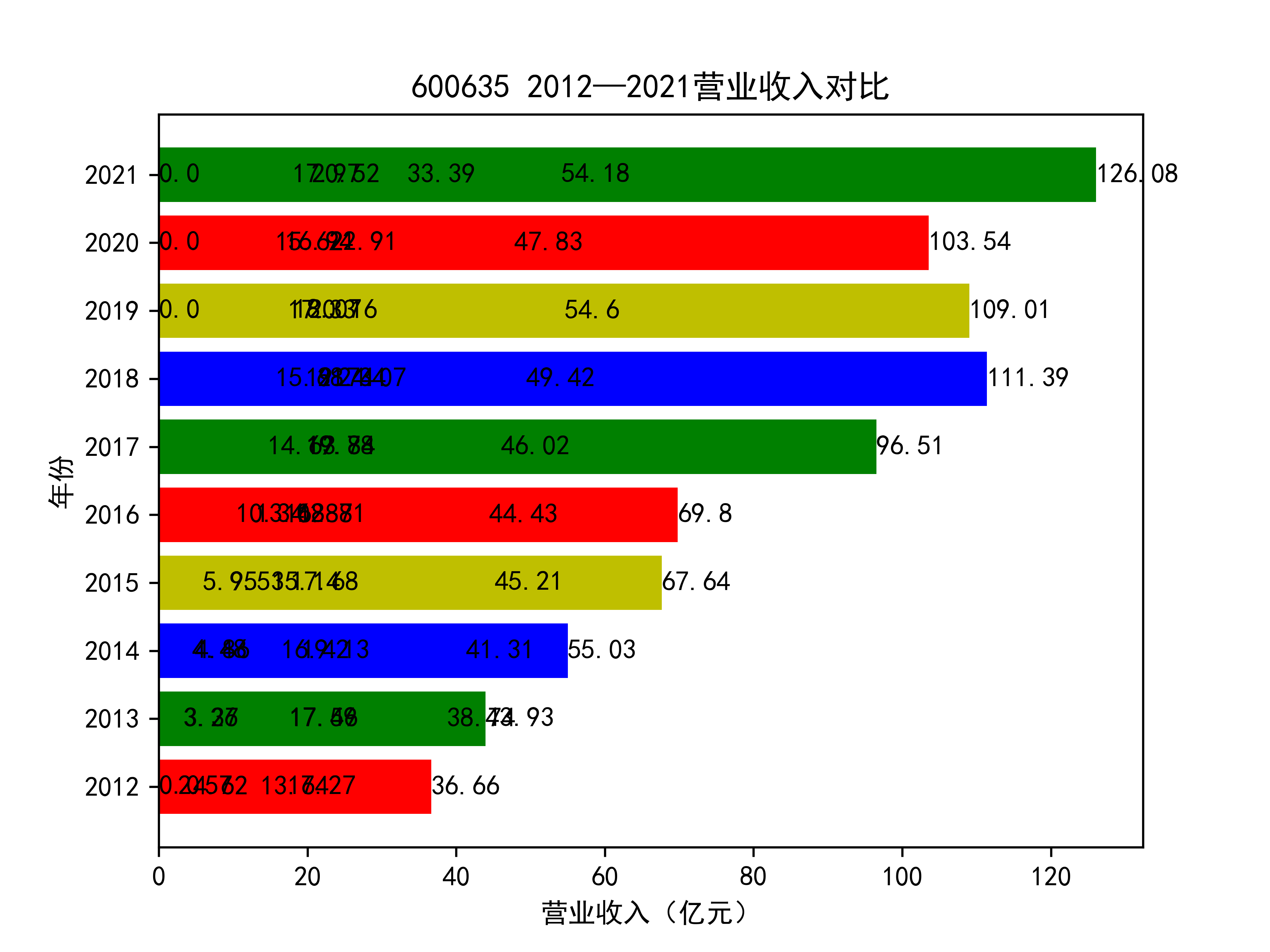
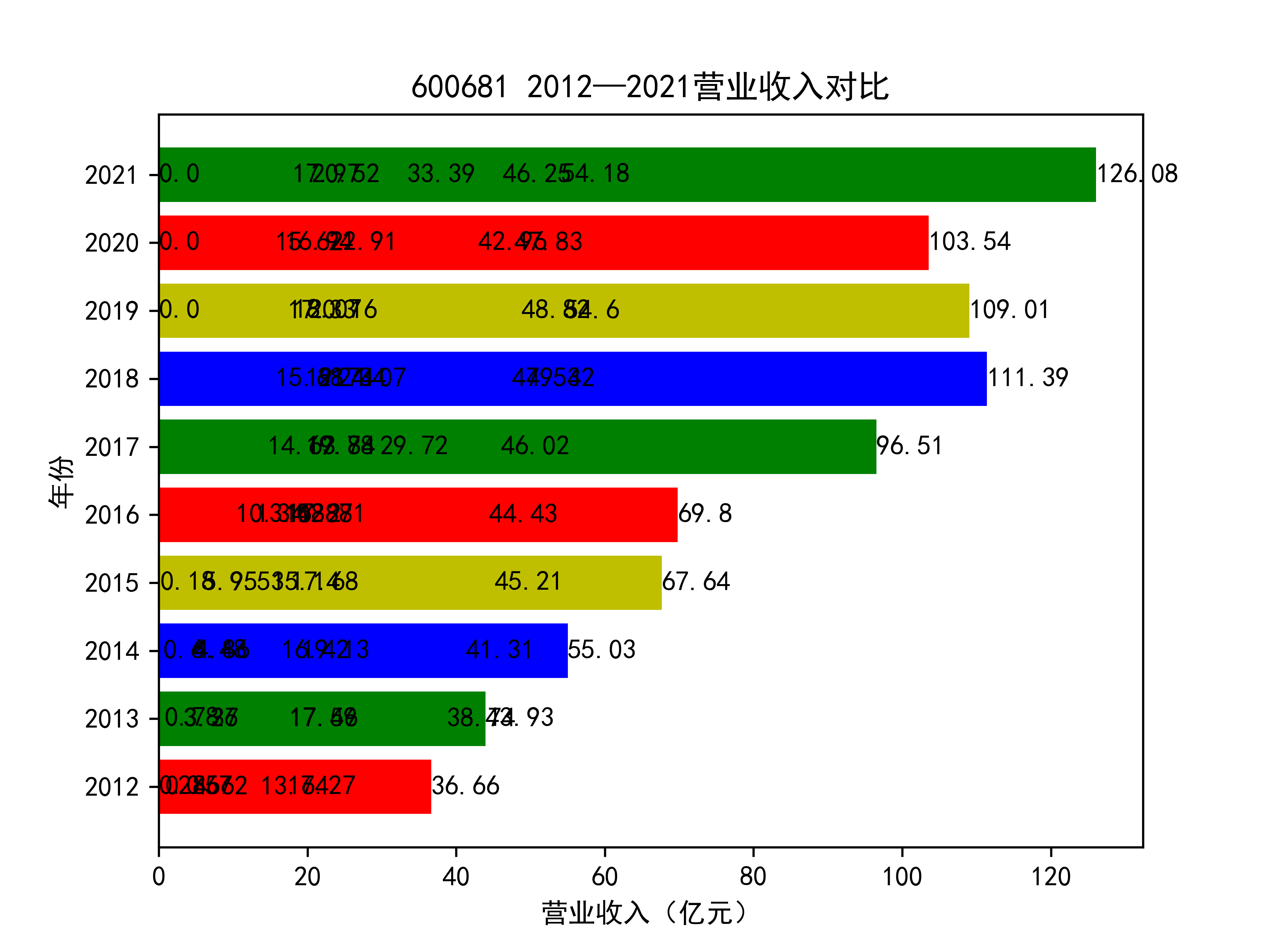
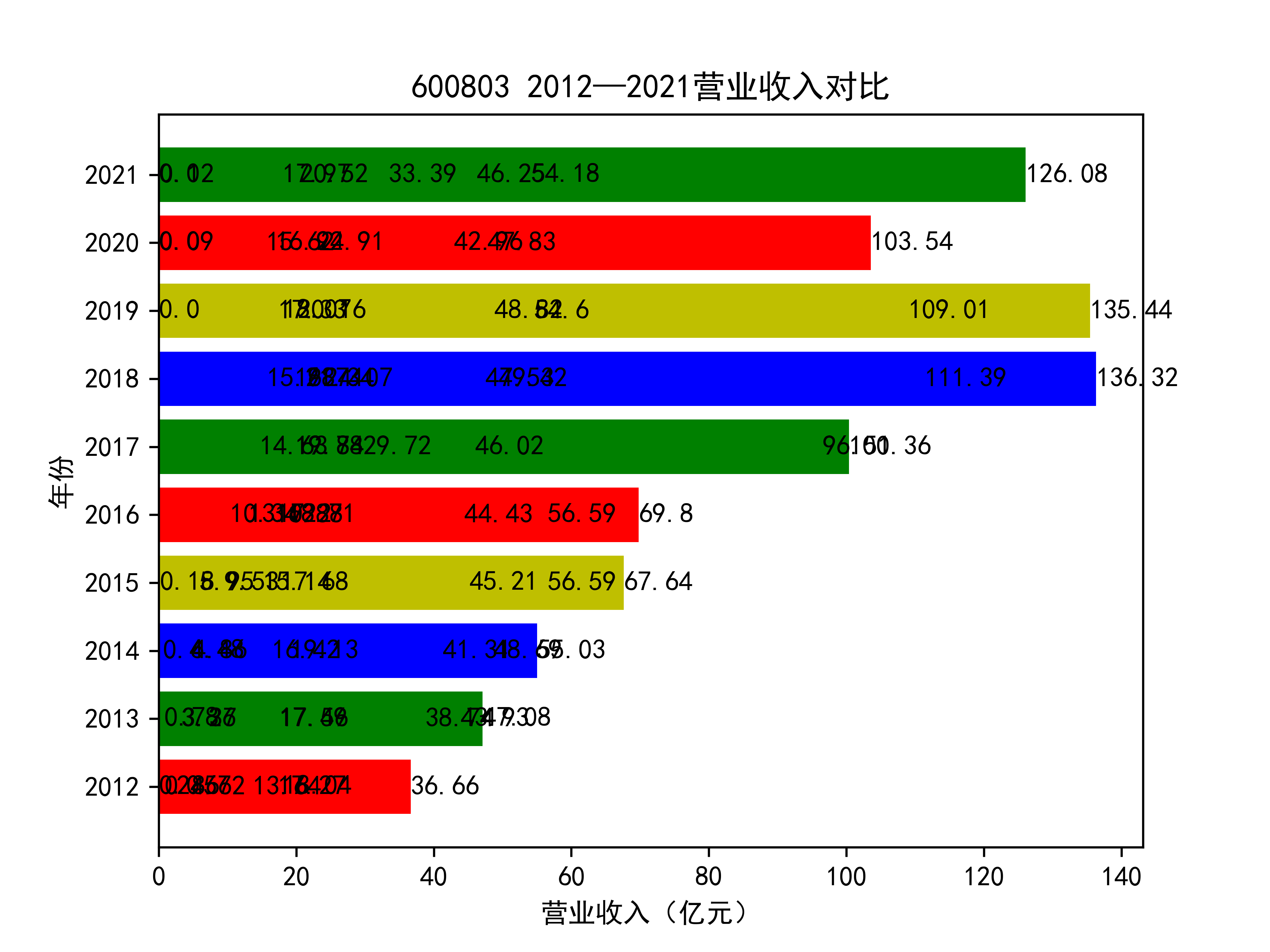
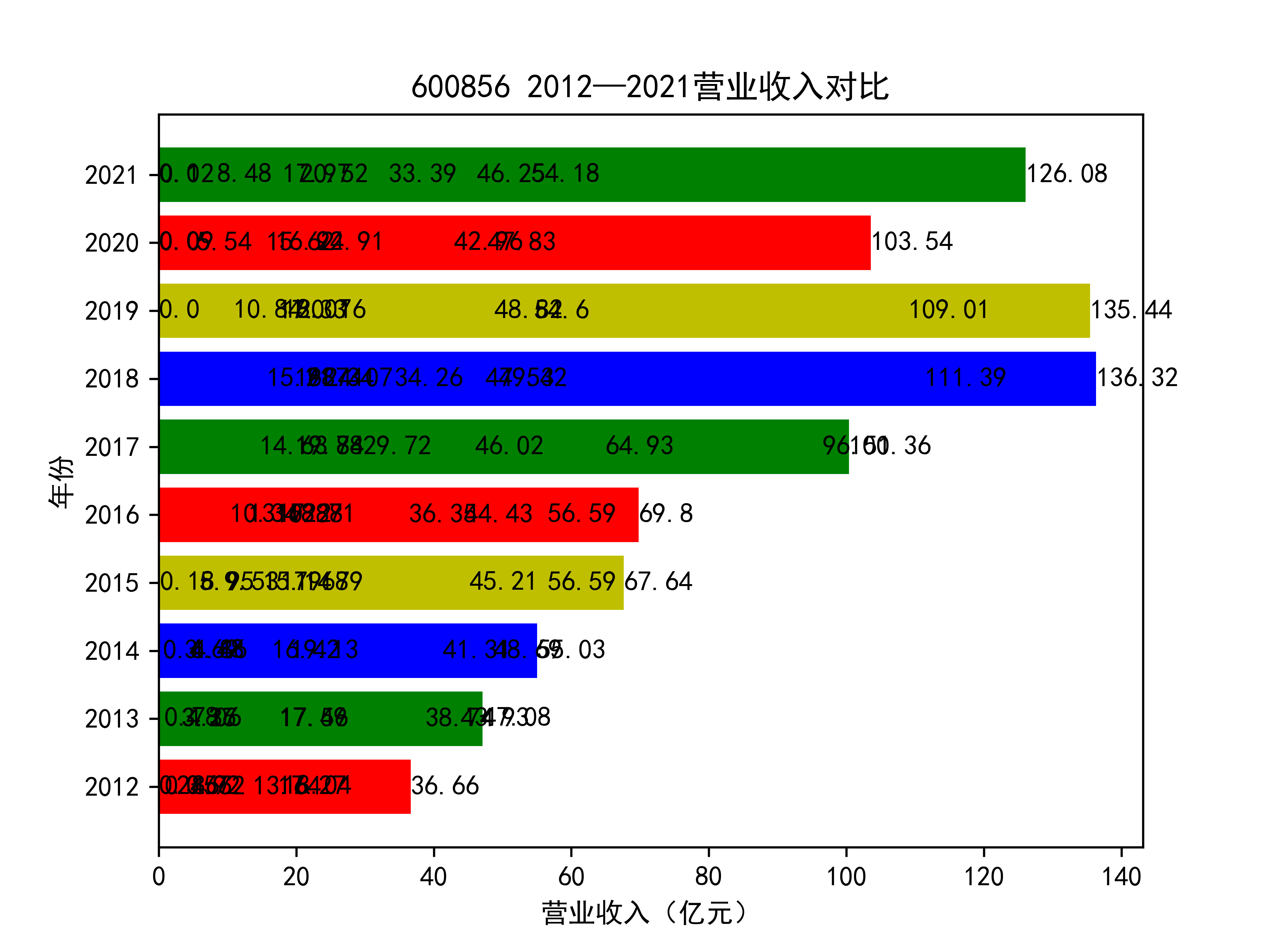
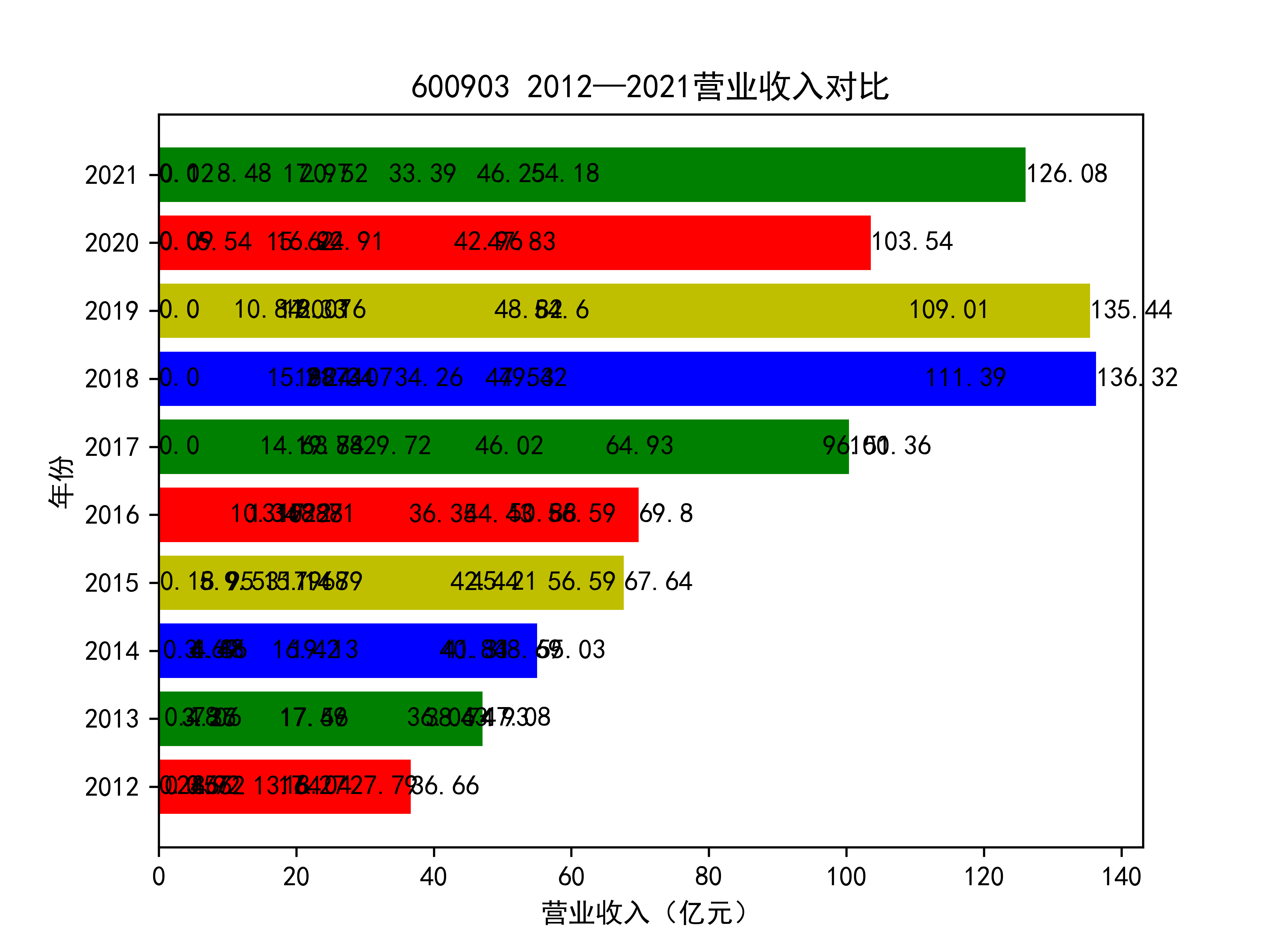
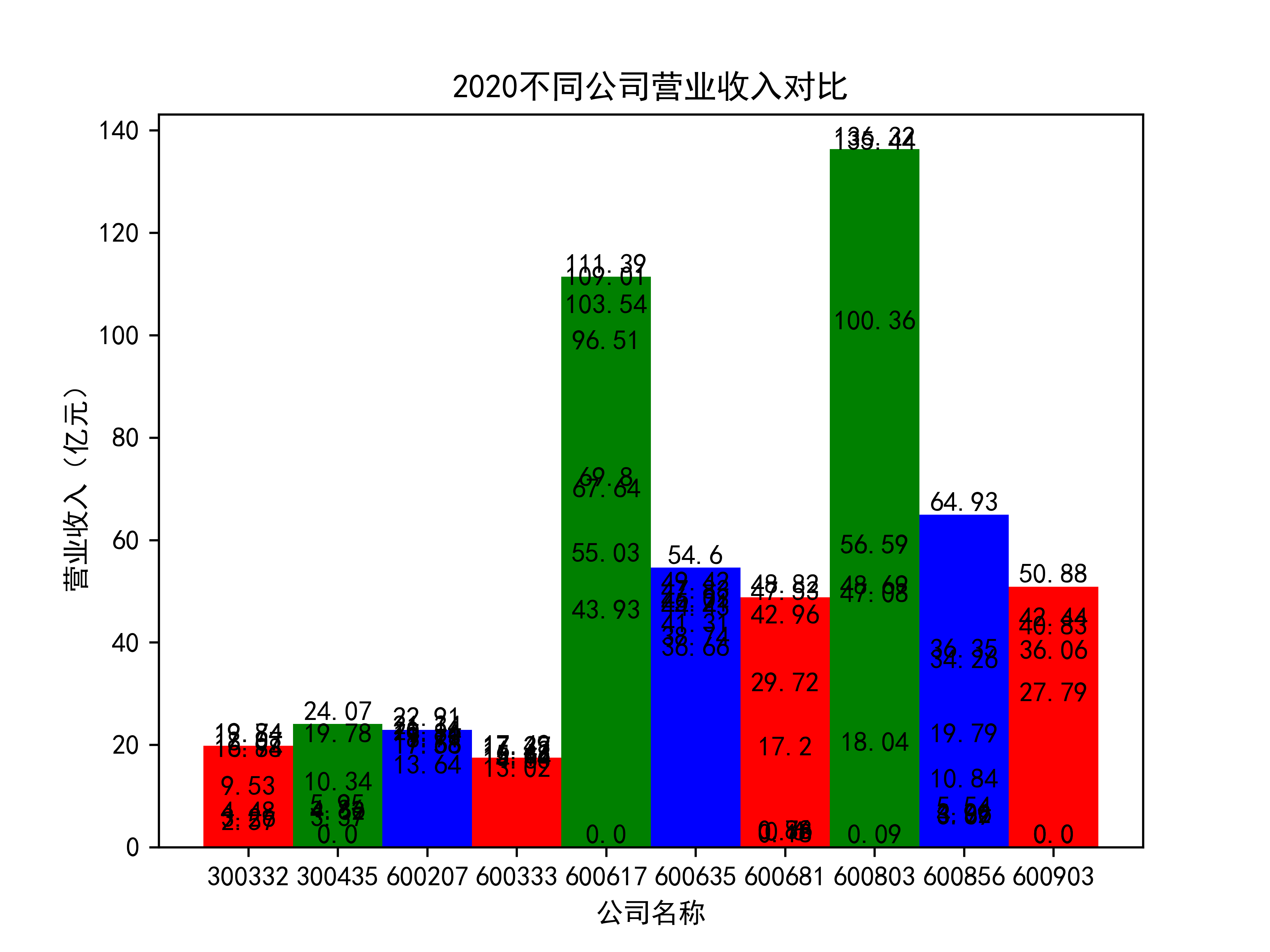
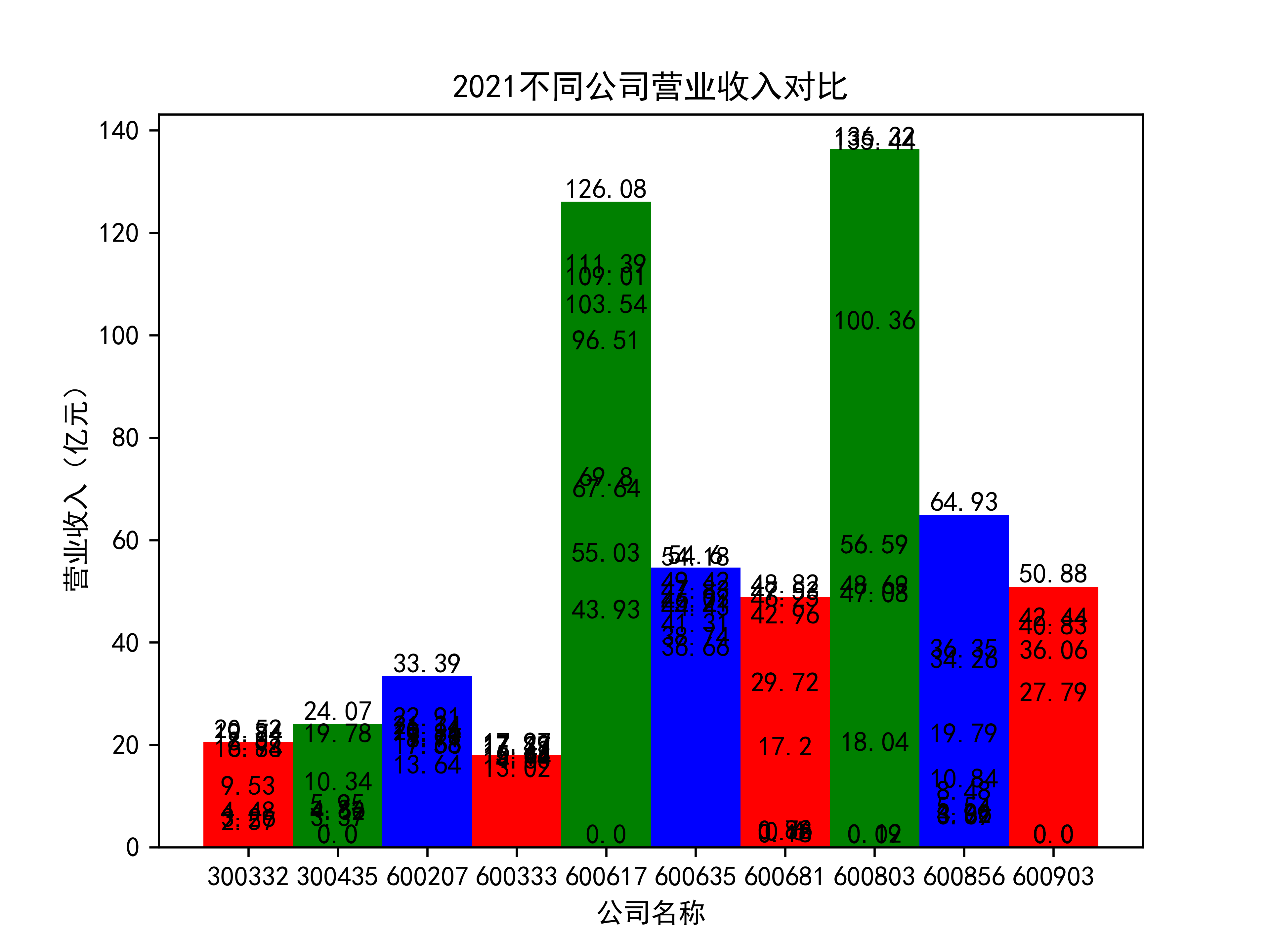
以下绘制营业收入的对比图:
def x_ticks(list_columns,name_list):
num_list = list_columns
rects = plt.bar(range(len(list_columns)),num_list,color="rgb",width = 1,tick_label=list_name_1)
plt.title(name_list+"不同公司营业收入对比")
plt.xlabel("营业收入(亿元)")
plt.ylabel("公司名称")
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), size=10, ha="center", va="bottom")
plt.savefig(name_list +".png",dpi = 600)
plt.show()
for i in range(len(list_columns)):
x_ticks(list_columns_1[i], name_list[i])
营业收入对比图如下所示:
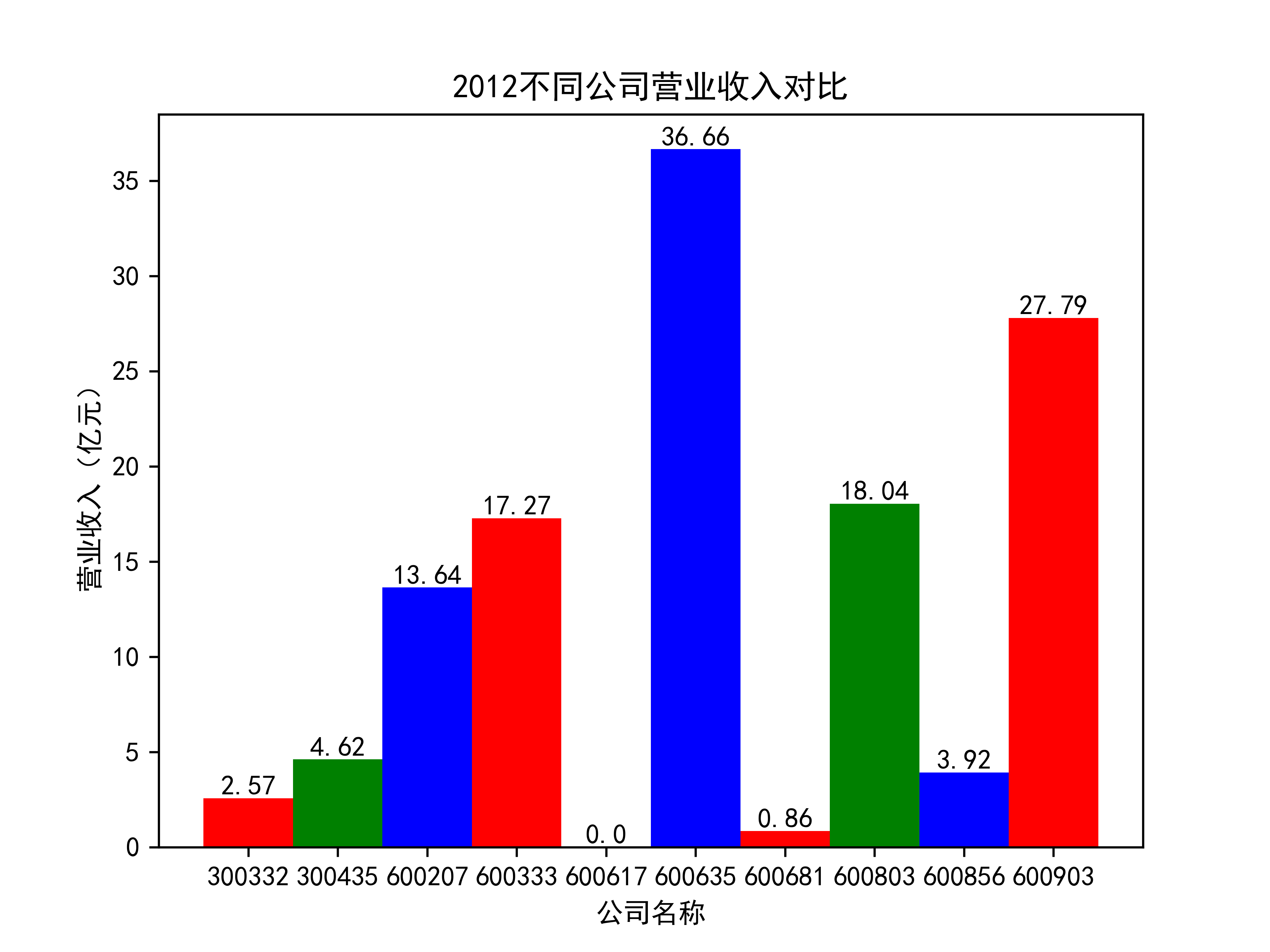
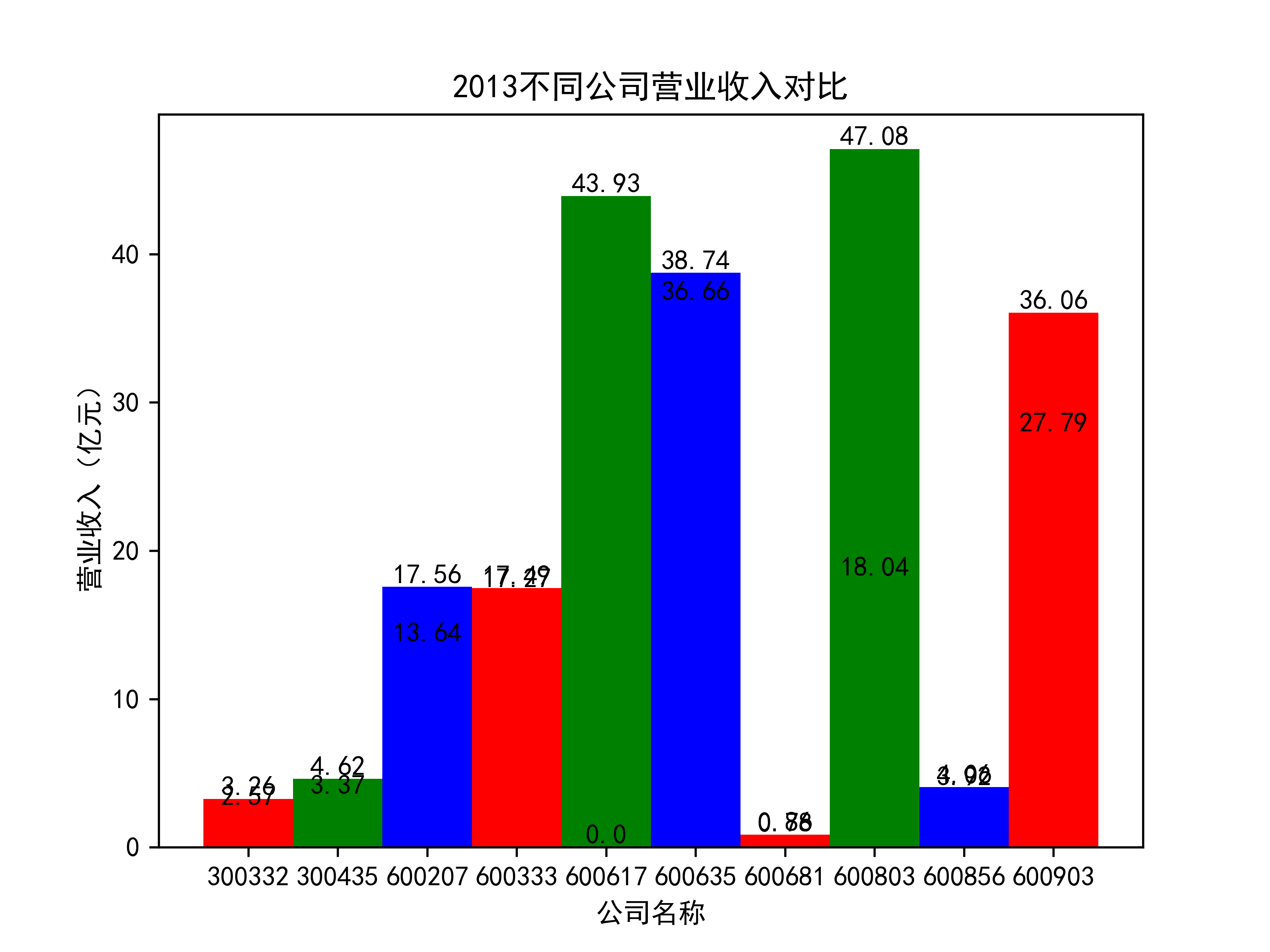
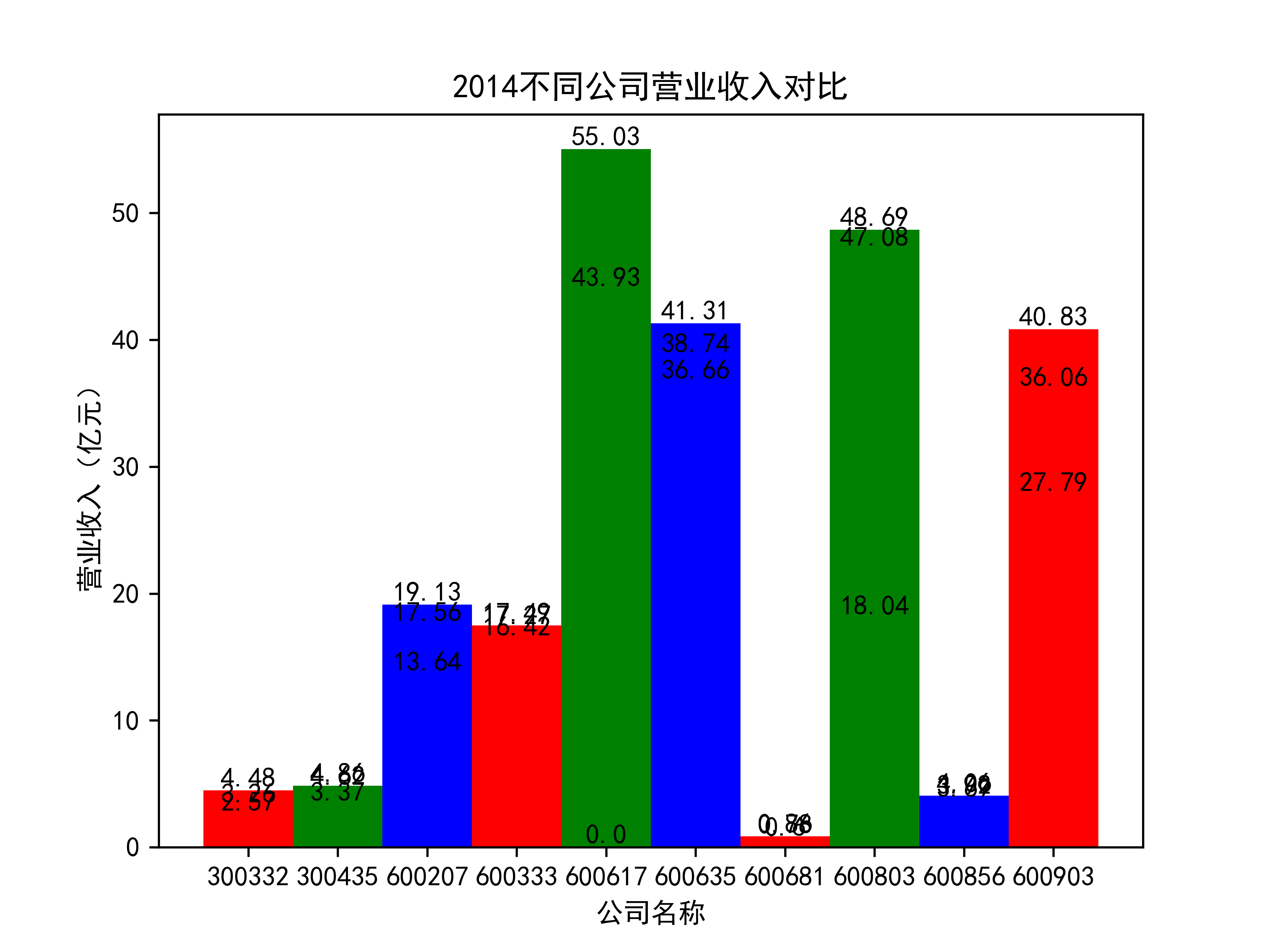

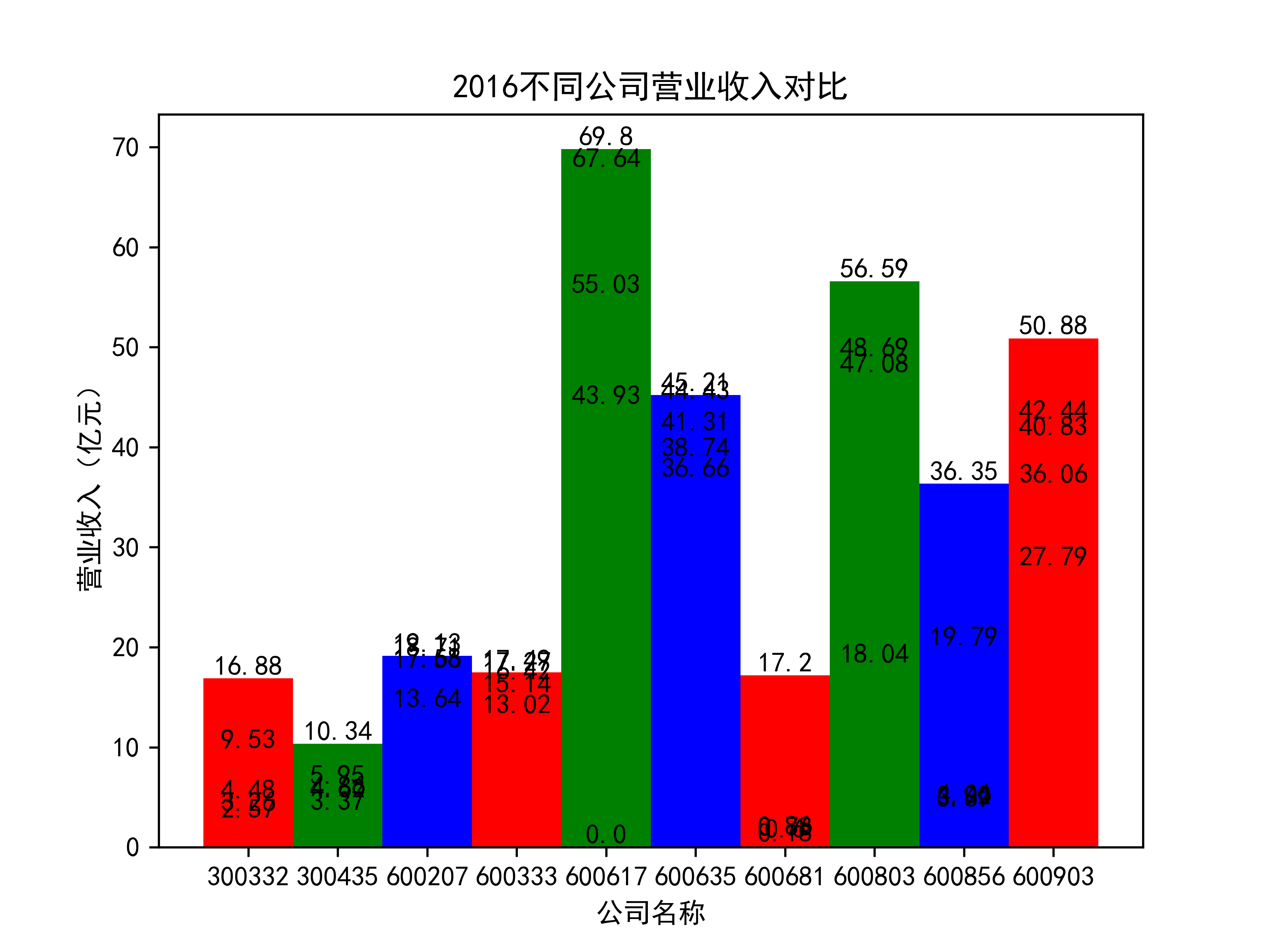
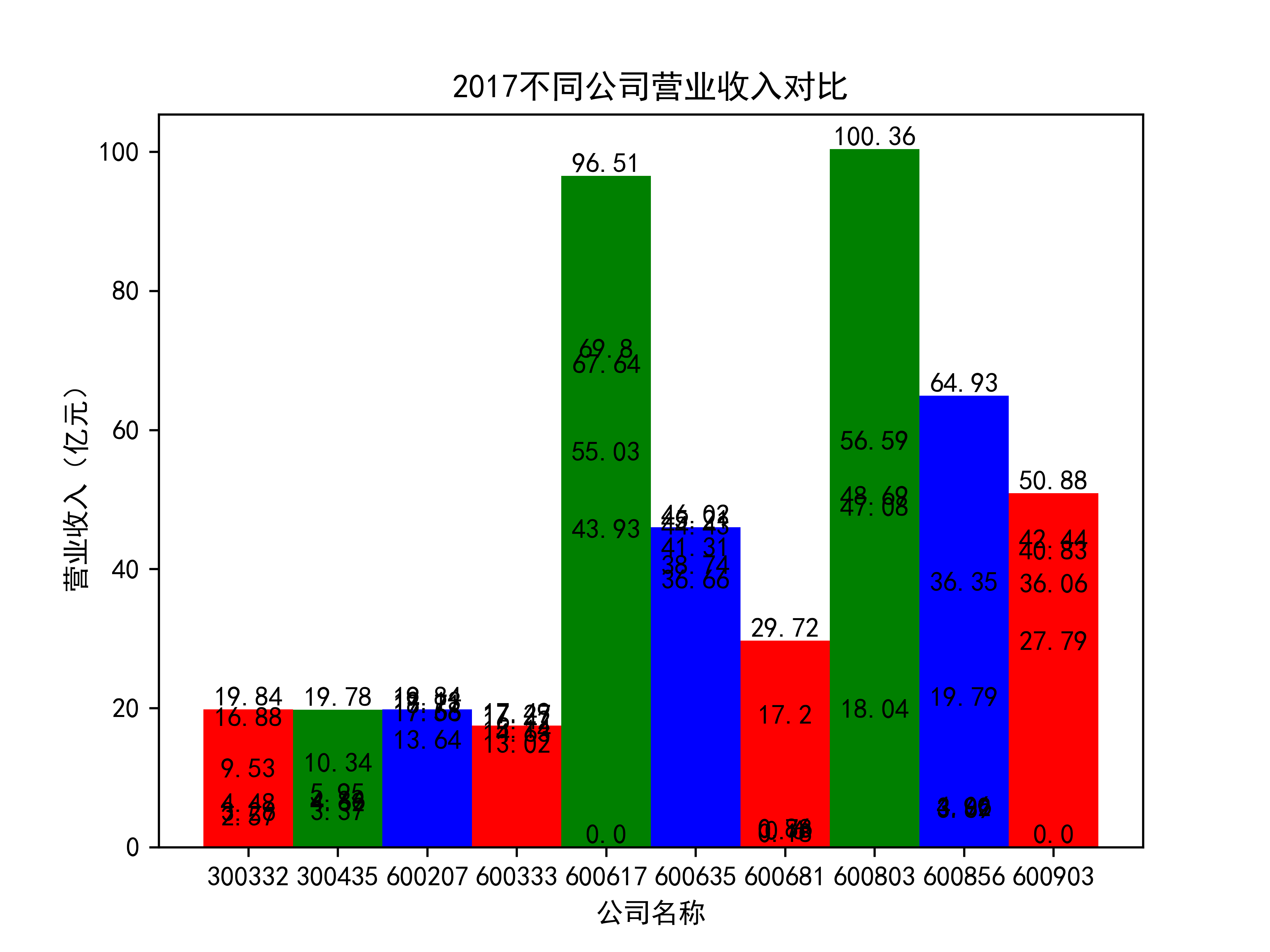

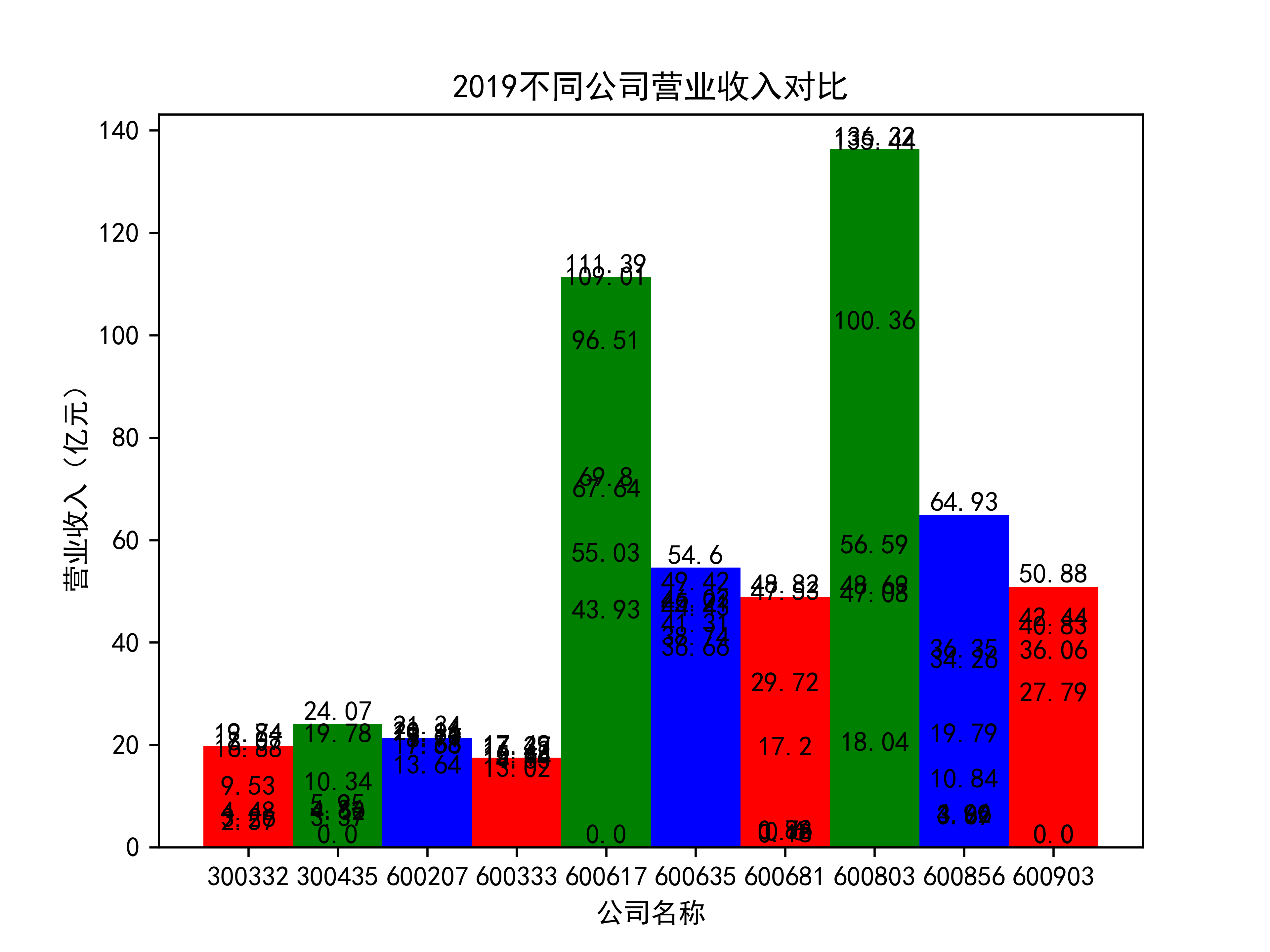
以下为绘制基本每股收益随时间的变化趋势图及绘制对比图
os.chdir('..\\')#为了后续将图片保存在父文件夹中
sj_data2 = pd.read_csv("C:\\Users\\24078\\pf.csv")
sj_pf1 = pd.DataFrame(sj_data2)
sj_pf_new1 = sj_pf1.iloc[8:18,1:]#得到包含前十家公司不同年份每股收益的表格
sj_pf_new2 = sj_pf1.iloc[8:18,]#含股票代码
sj_pf_new1.reset_index(drop=True)
list_row_pf = sj_pf_new1.values.tolist()#以行为单位取成列表,每个列表是十年同一公司的每股收益
#list_name_pf = sj_pf_new2['股票代码']#取索引
#print(list_name_pf)
columns1 = list(sj_pf_new1)
list_columns_profit = []#以列为单位取的列表,每个都是每一年十家公司的营业收入
for c in columns1:
d = sj_pf_new1[c].values.tolist()
list_columns_profit.append(d)#以列为单位取成列表
name_list = ['2012',"2013","2014","2015","2016","2017","2018","2019",'2020','2021']
list_name_1 = ['300332','300435',"600207","600333",'600617',"600635","600681","600803","600856",'600903']
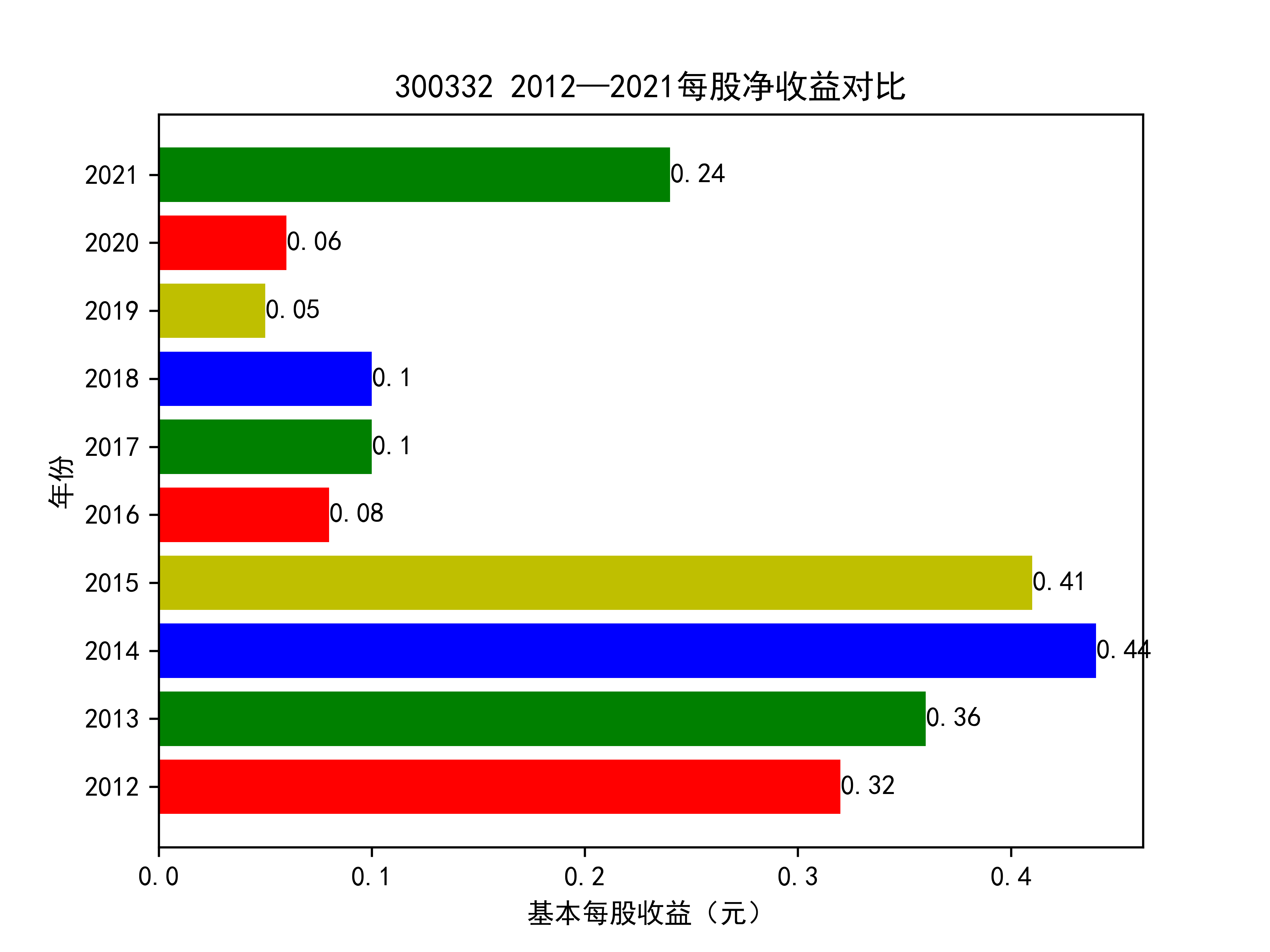
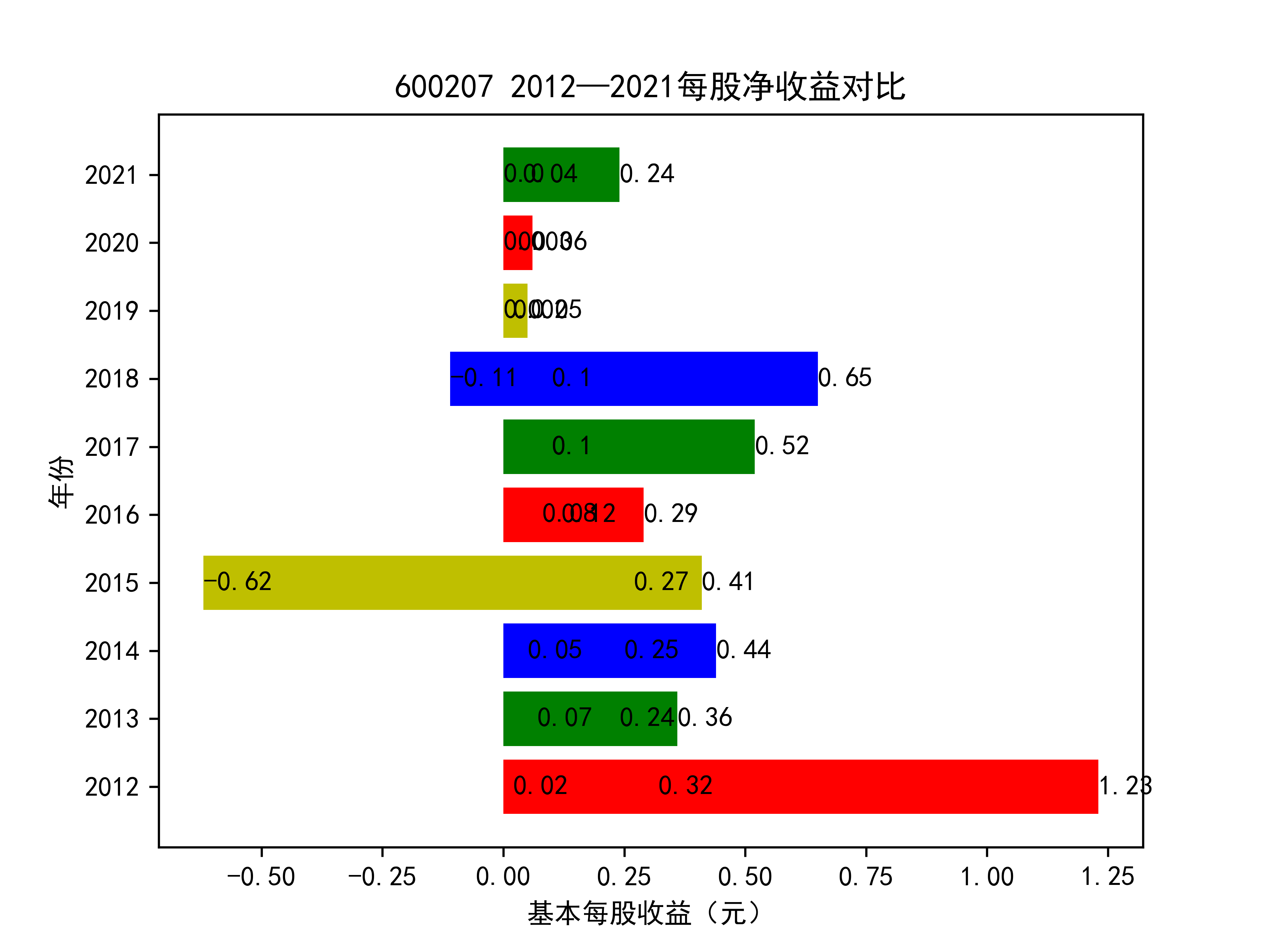
def y_ticks2(list_row_pf,list_name_1):
num_list_1 = list_row_pf
rects = plt.barh(range(len(list_row_pf)),num_list_1,color='rgby')
N = 10
index = np.arange(N)
plt.yticks(index,name_list)
plt.title(list_name_1+" 2012—2021每股净收益对比")
plt.xlabel("基本每股收益(元)")
plt.ylabel("年份")
for rect in rects:
w=rect.get_width()
plt.text(w,rect.get_y()+rect.get_height()/2,w,size =10,ha='left',va='center')
plt.savefig(list_name_1 +"净收益.png",dpi = 600)
plt.show()
for i in range(len(list_row_pf)):
y_ticks2(list_row_pf[i], list_name_1[i])
基本每股收益随时间变化图如下所示

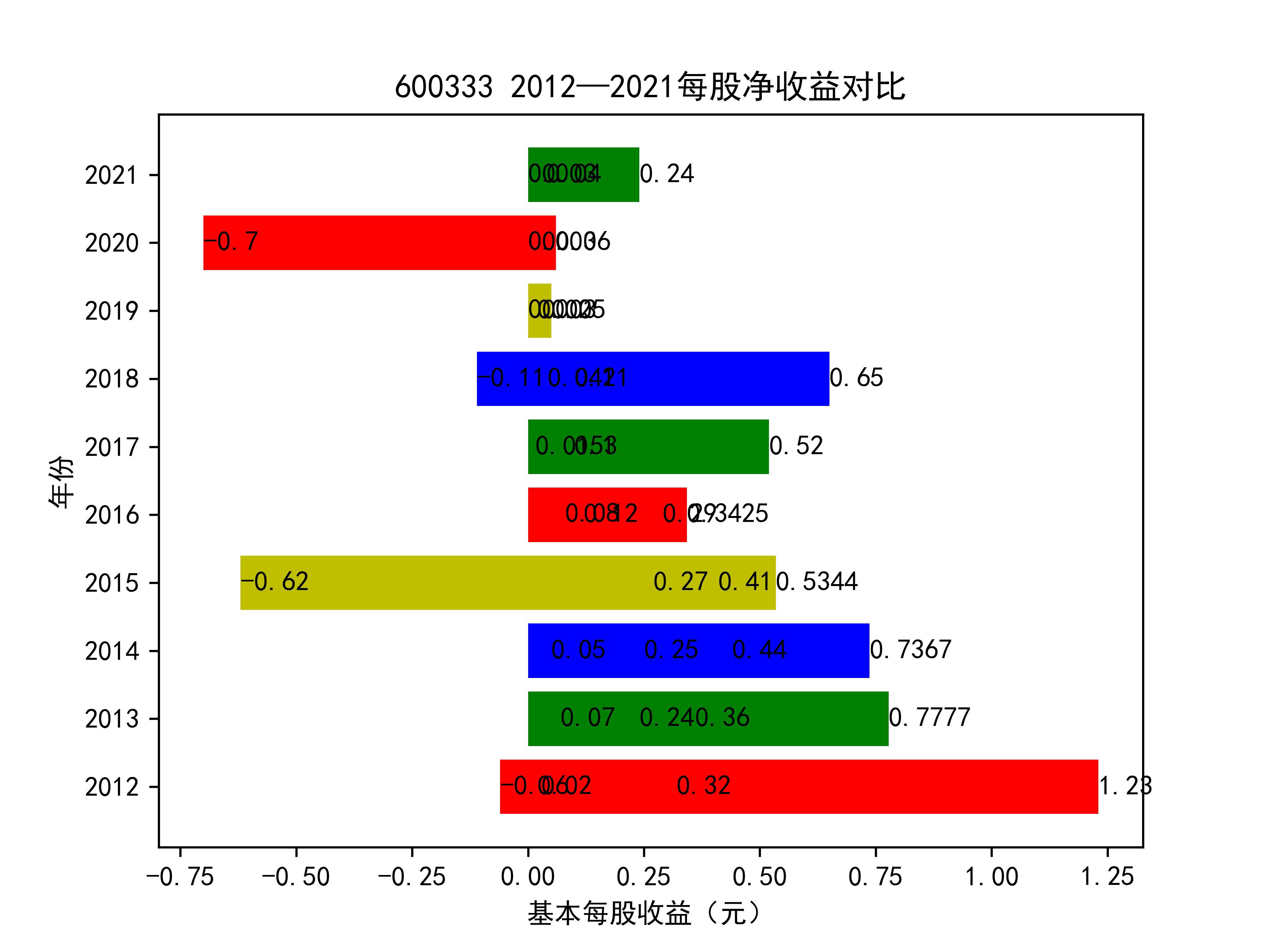
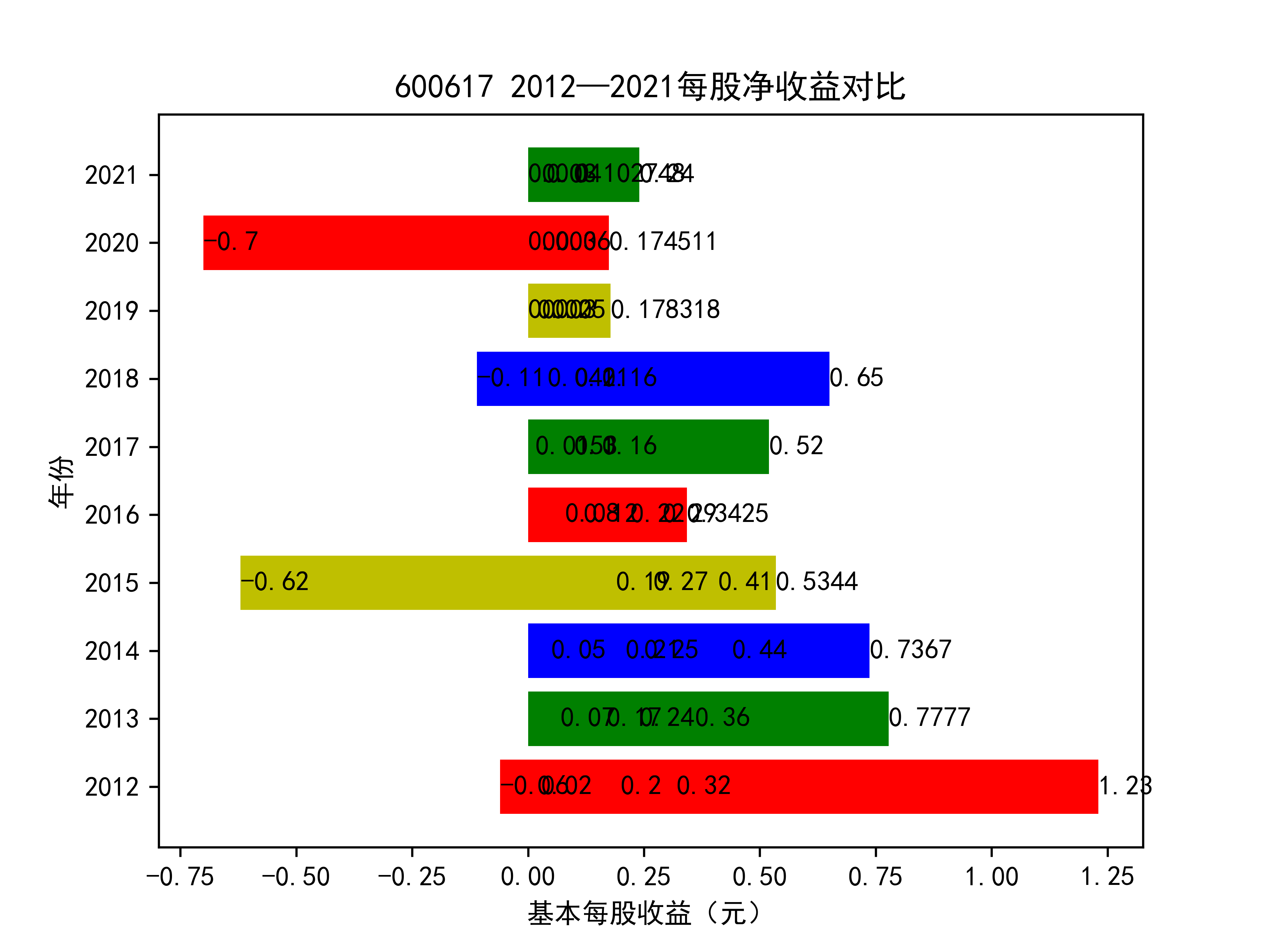
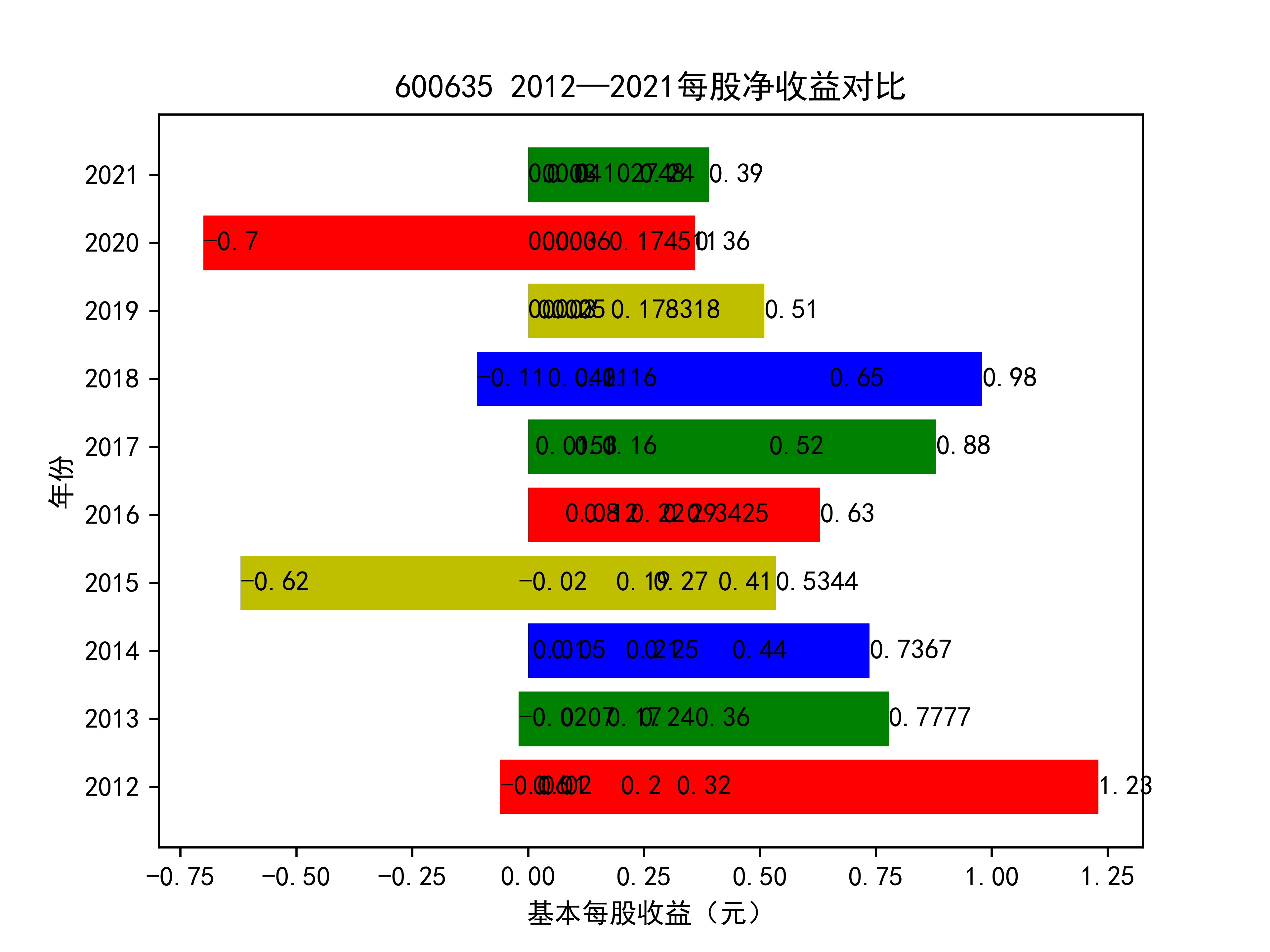
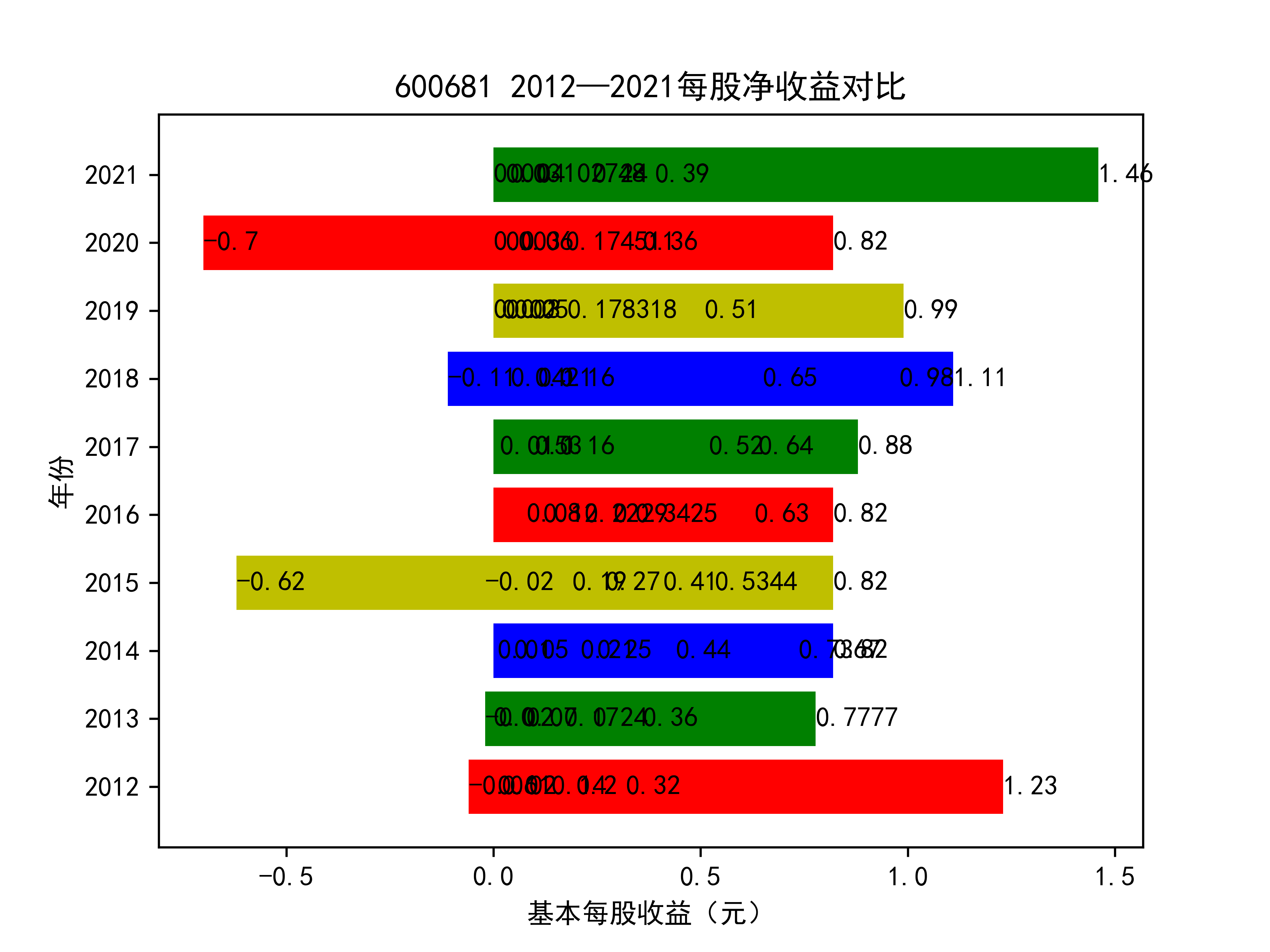
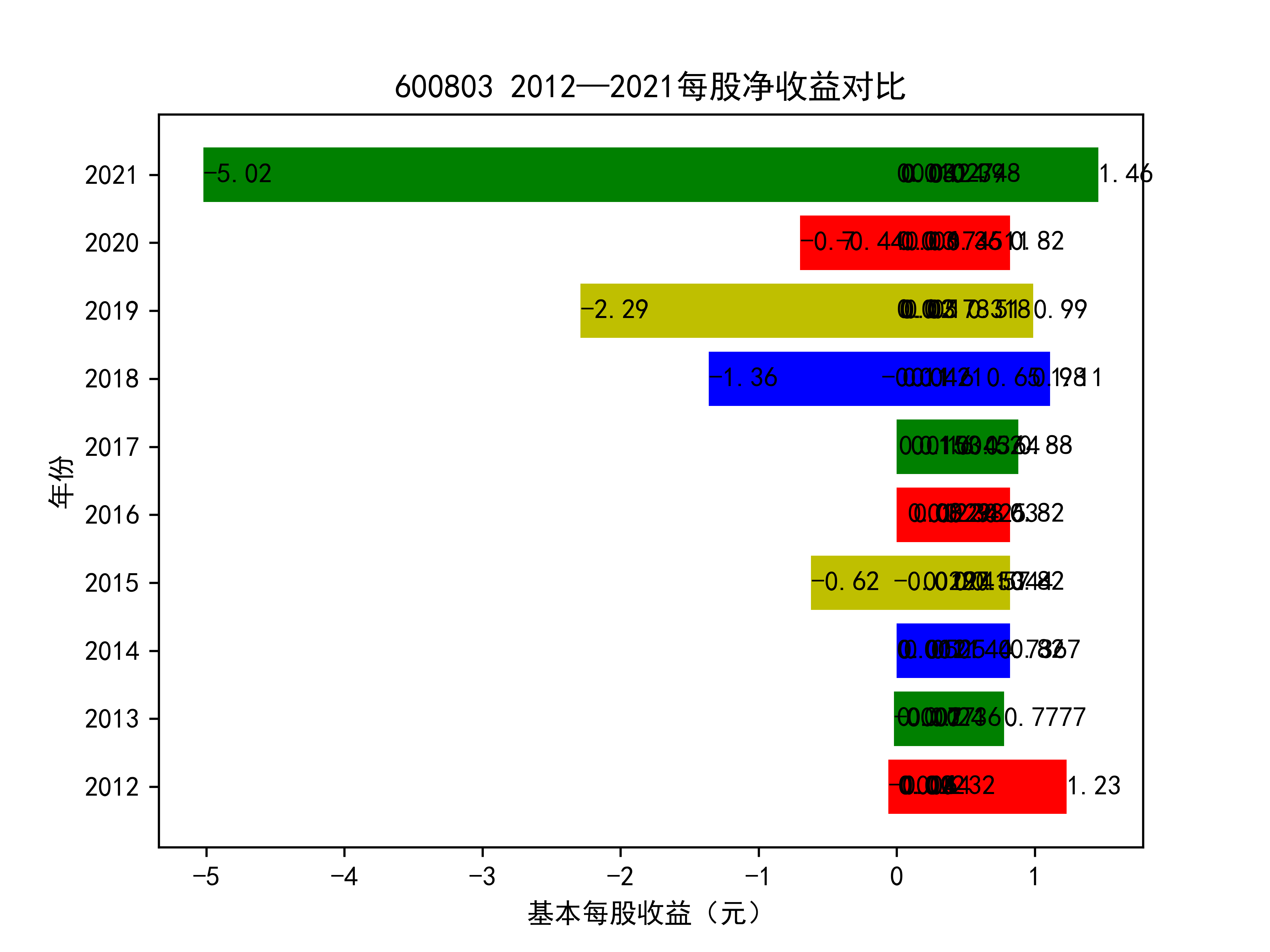
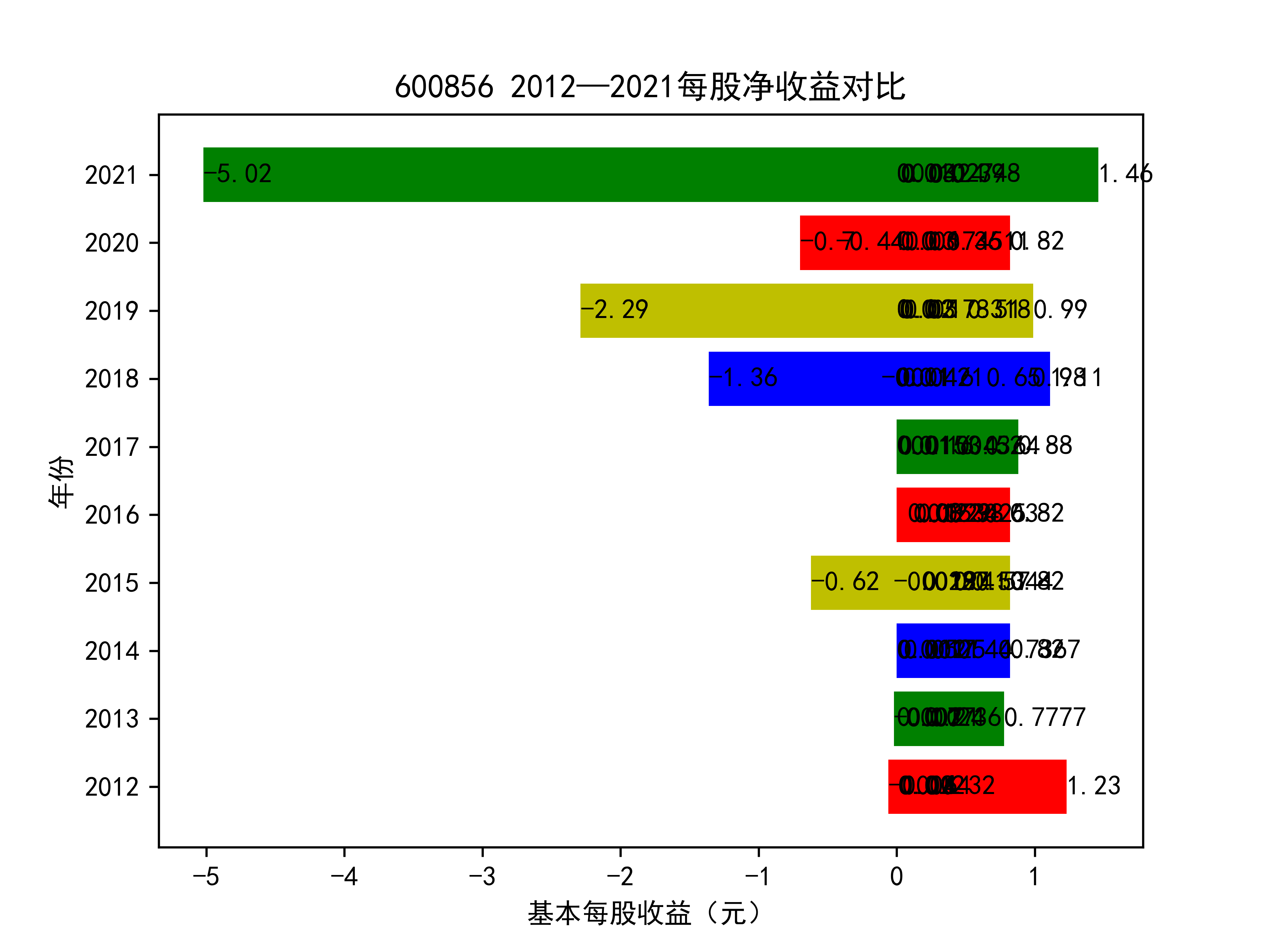
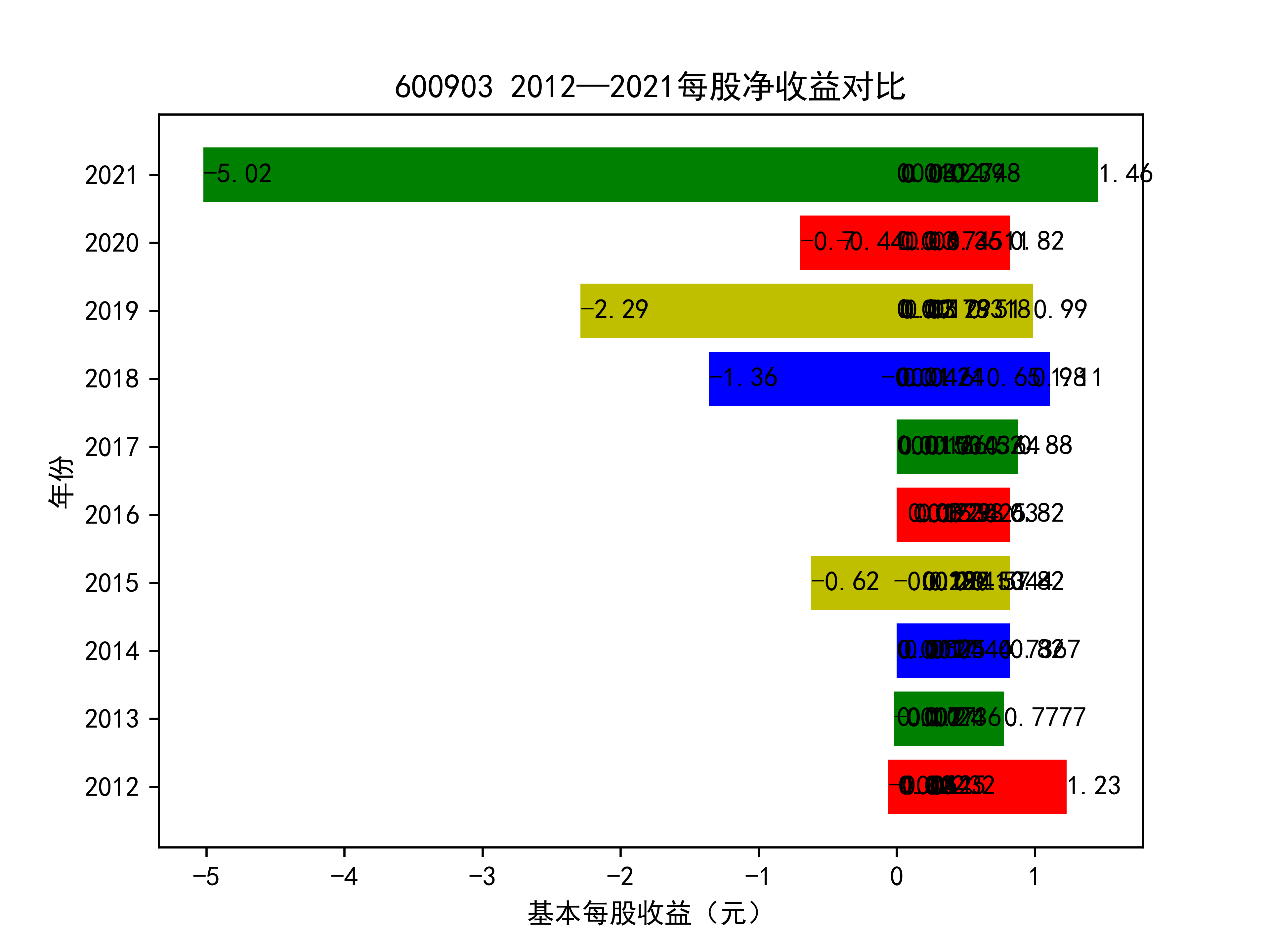
以下绘制基本每股收益的对比图:
def x_ticks2(list_columns_profit,name_list):
num_list = list_columns_profit
rects = plt.bar(range(len(list_columns_profit)),num_list,color="rgb",width = 1,tick_label=list_name_1)
plt.title(name_list+"不同公司每股净收益对比")
plt.xlabel("公司名称")
plt.ylabel("基本每股收益(元)")
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), size=10, ha="center", va="bottom")
plt.savefig(name_list +"净收益.png",dpi = 600)
plt.show()
for i in range(len(list_columns_profit)):
x_ticks2(list_columns_profit[i], name_list[i])
结果
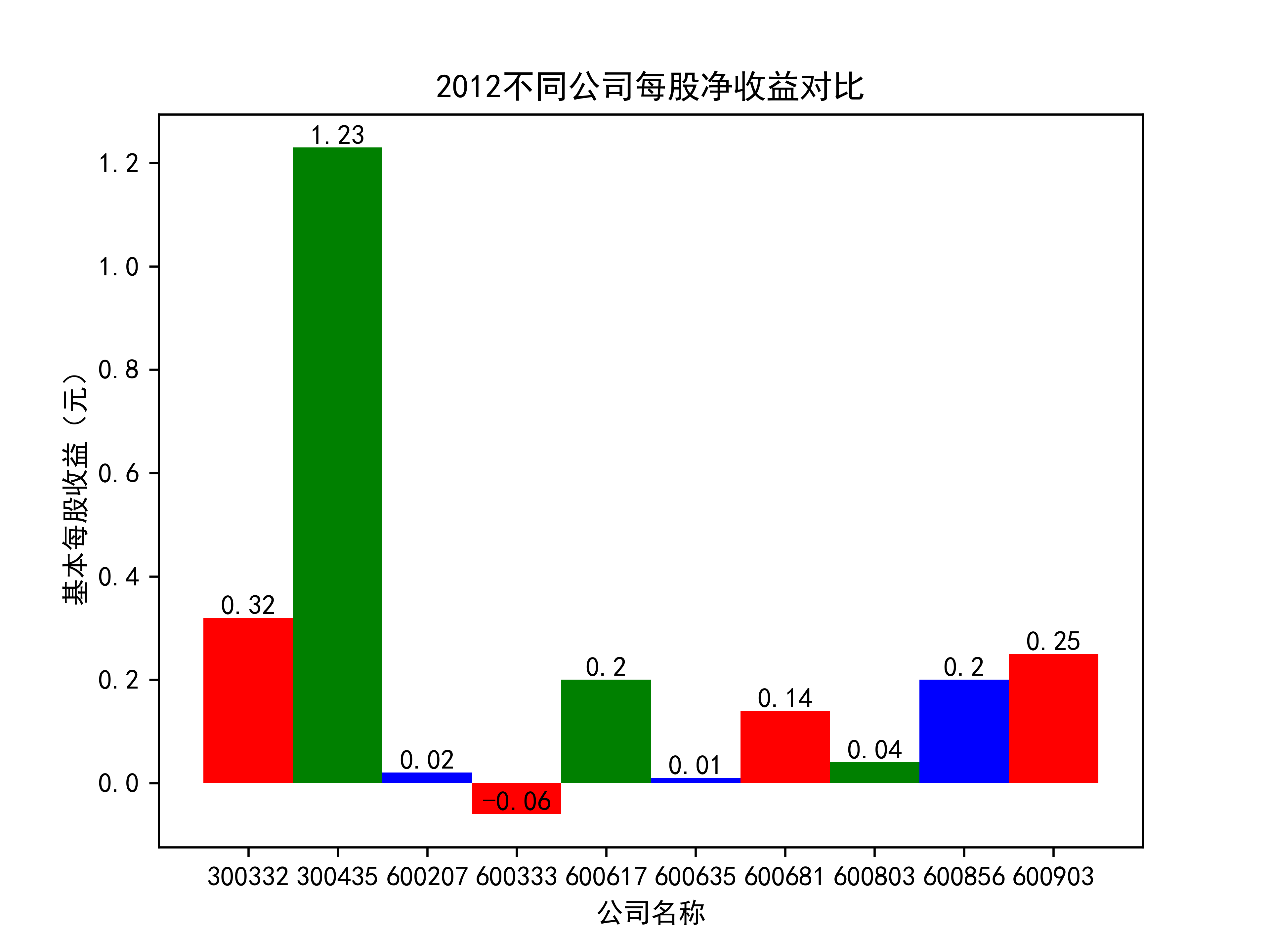
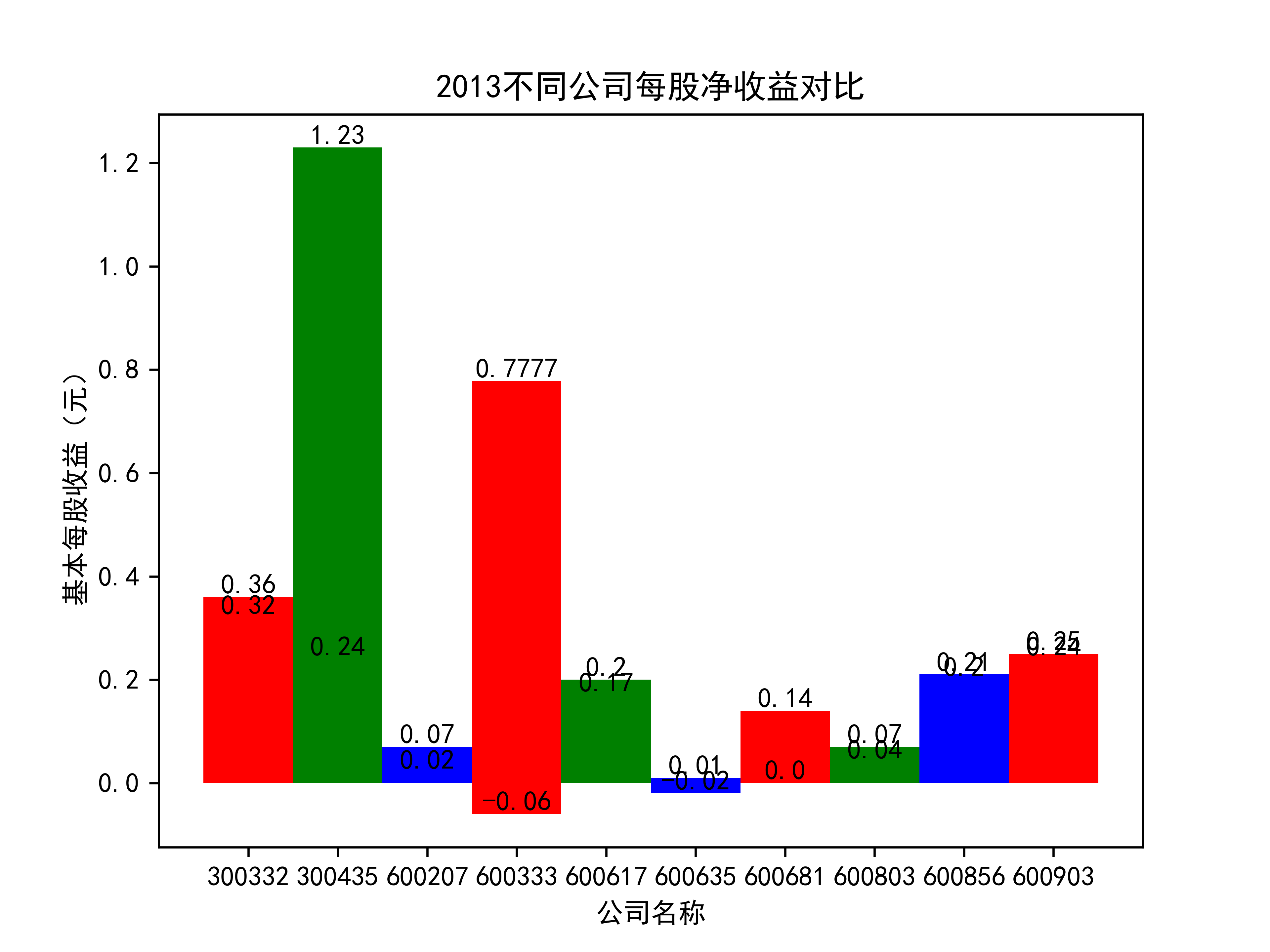
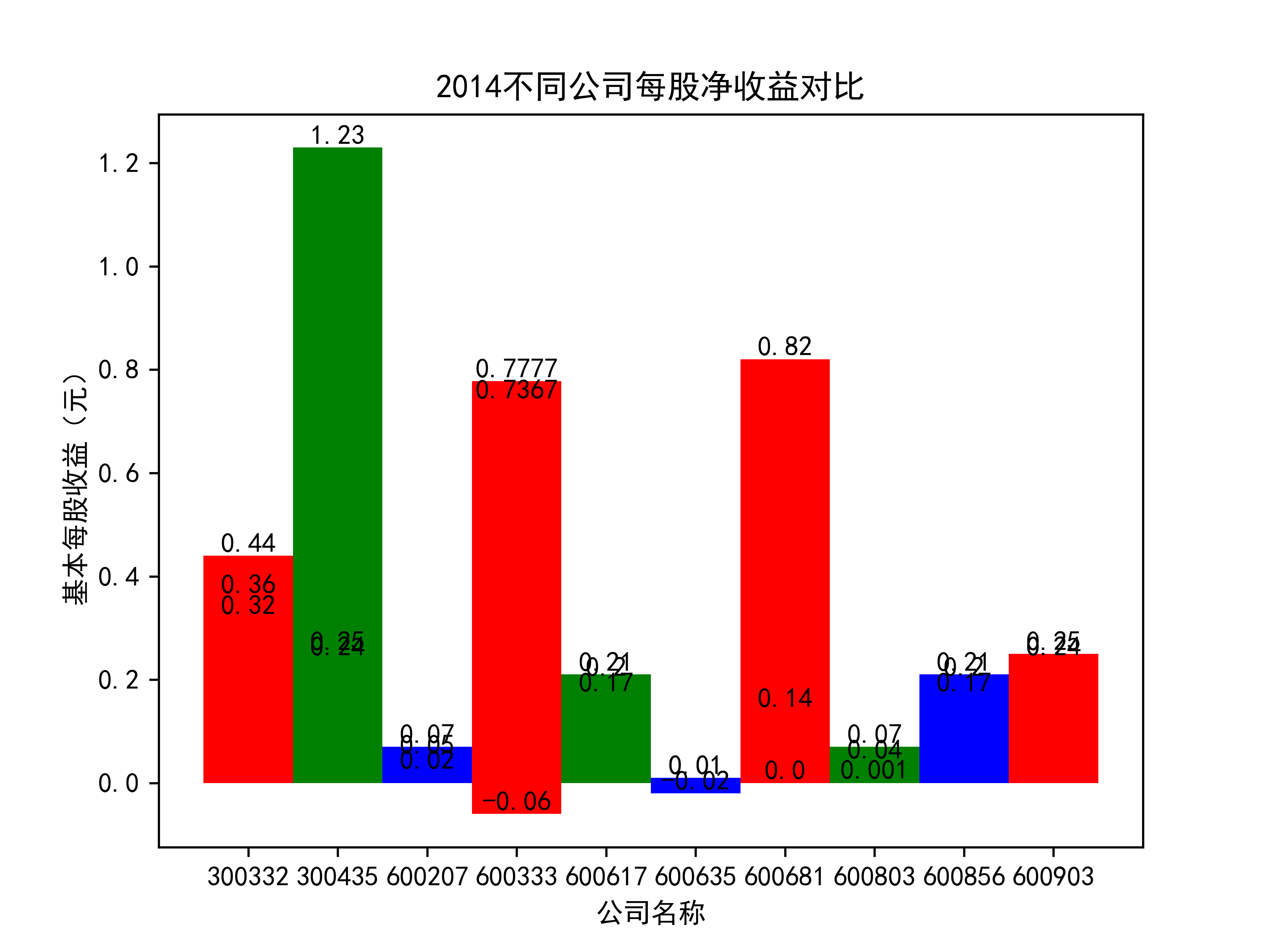
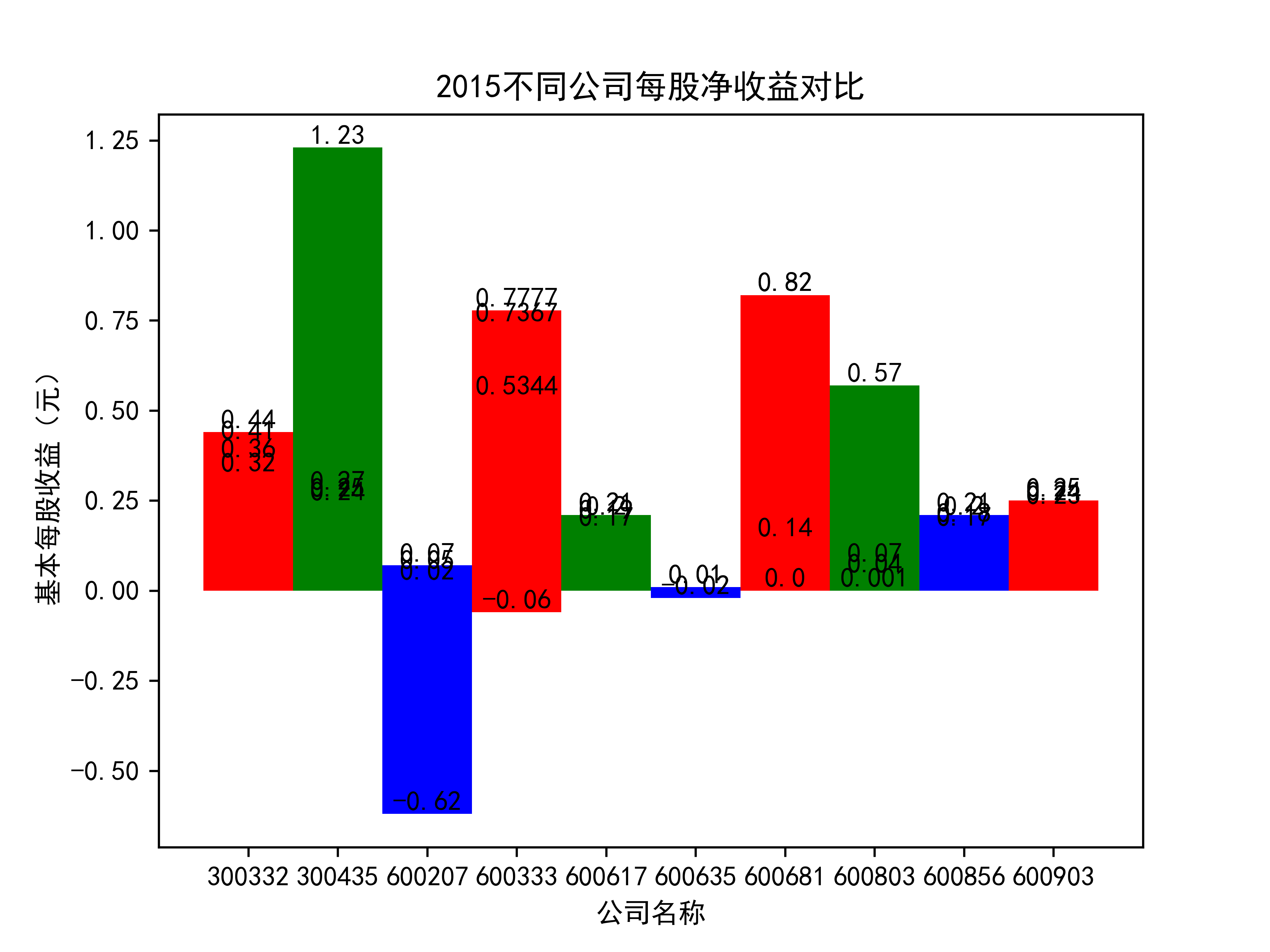
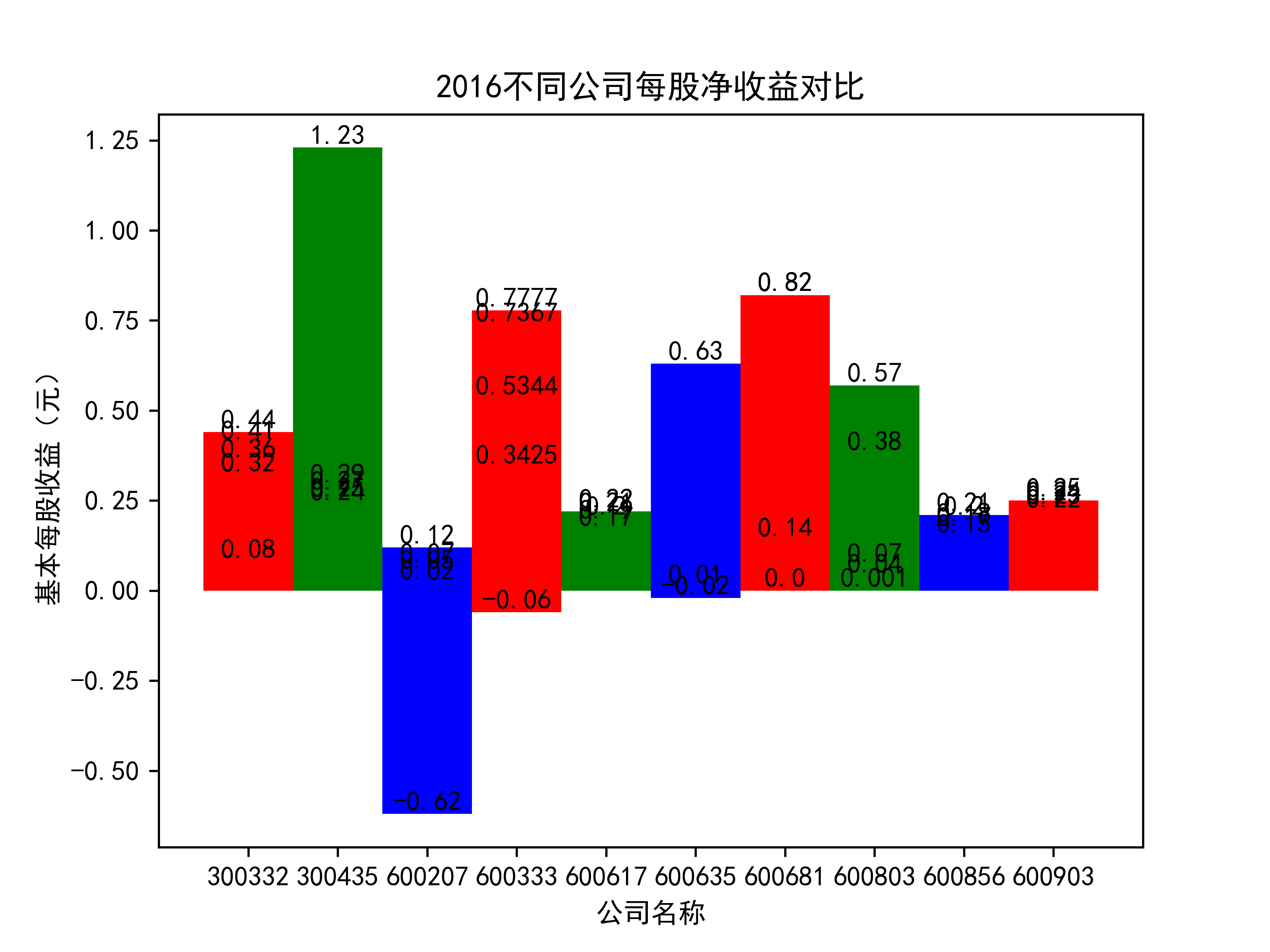

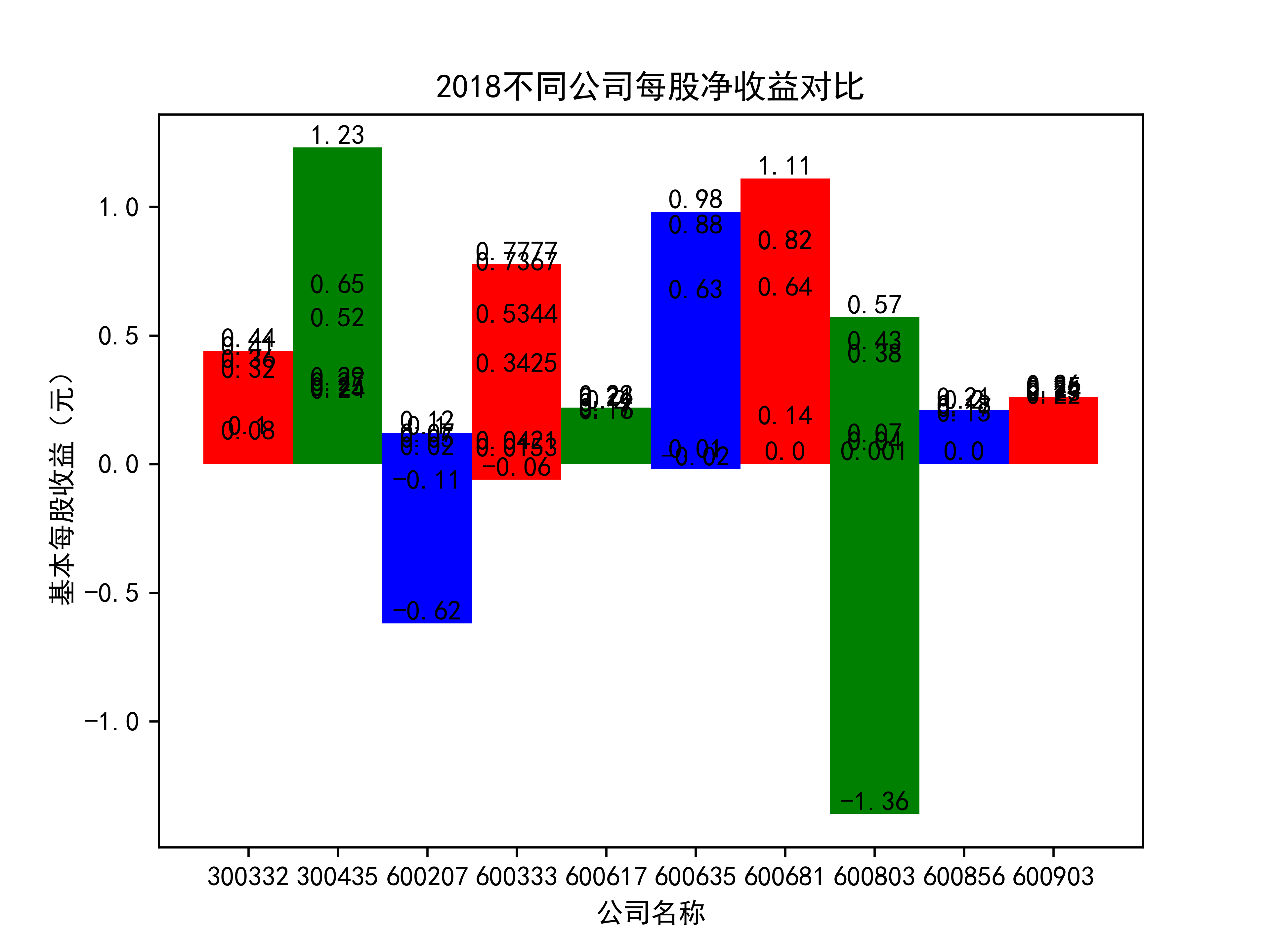
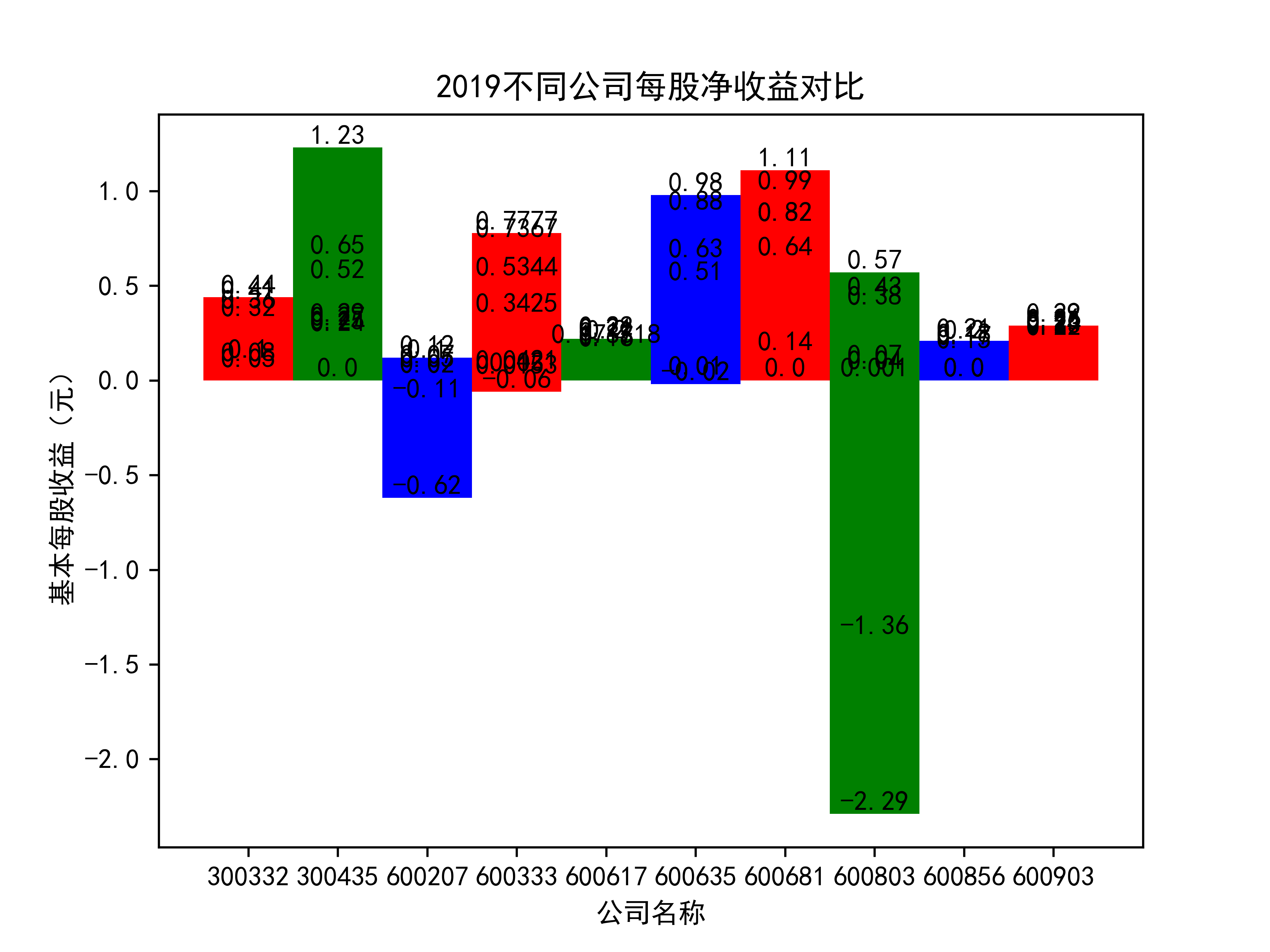
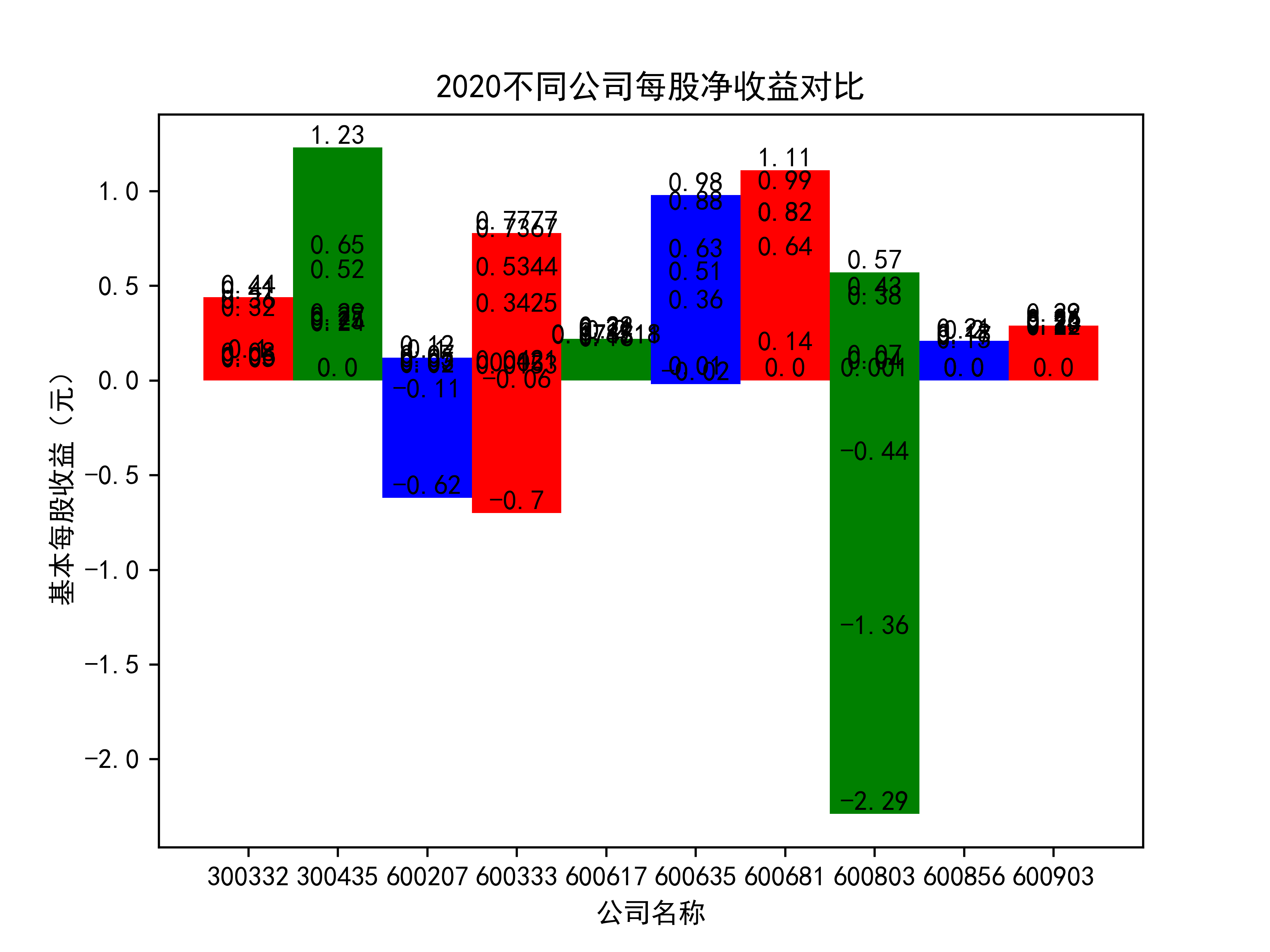
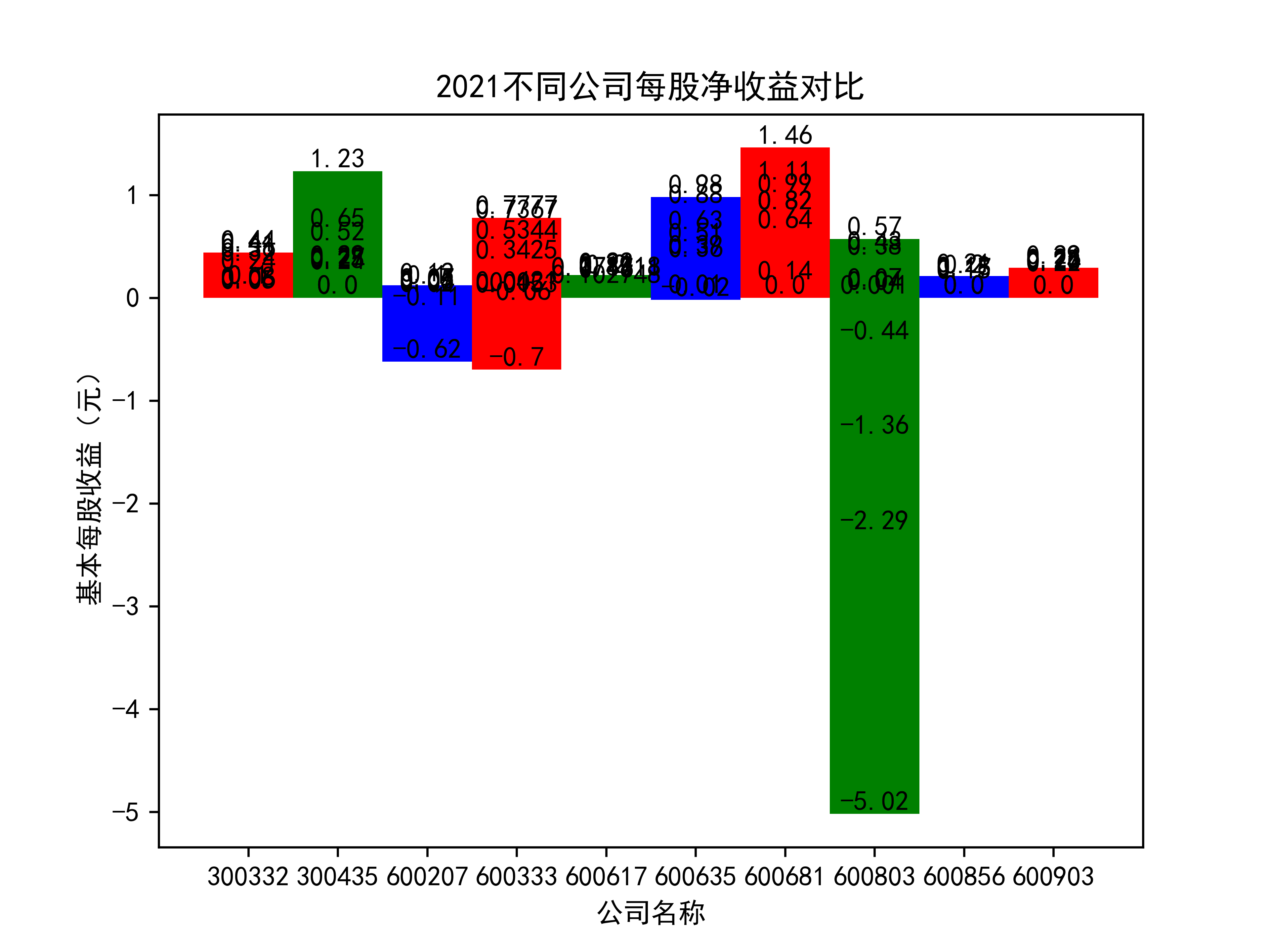
在燃气生产和供应业这个行业 我选取了10家公司并对其过去十年的营业收入及其基本每股收益绘制了其随时间的变化趋势图以及公司对比图。
从营业收入的角度分析:从图中我们大致可以看出,在过去的十年间,燃气生产和供应业行业中的部分公司的营业收入总体是呈逐年递增的态势,当然,也有部分公司逐年会有点上下波动,但大体上这些公司是呈现稳步增长的趋势,从对比图我们可以看出,公司间营业收入还是有差距的,这其中有几家公司的营业收入可以说是处于领先的地位。从营业收入角度我们可以看出燃气生产和供应业还是一个不断增长的,相对来说很有竞争力的行业。总体来看,行业的盈利能力还是比较强的。
从基本每股收益的角度:我们可以了解到在前些年,基本每股收益还处于一个比较稳定的增长阶段,但近几年可能是由于疫情的影响,部分公司的基本每股收益呈现负增长,有些公司的基本每股收益还是负的,但也有部分公司呈现较快的增长趋势,从对比图我们也能看到类似的情况。在疫情以及行业内部竞争激烈的情况下,竞争力强的以及发展强劲的公司势必会击败那些不具备好的竞争力的公司
我们知道,一个行业的发展,离不开行业内公司的发展,而公司之间的相互竞争会淘汰那些阻碍行业发展的公司,从而使行业的发展前景更加欣欣向荣。所以说,我相信,在未来燃气生产和供应业的发展会越来越好的
经过一个学期的学习,课程到这也已经结束了,下面我来说说在学完一个学期的课程以及在这次大报告中我的个人感受。
在课程开始的时候,其实我对这门课的印象一直是觉得应该不是很难,可能是因为老师前期讲的知识点我在以前上其他的课程上或多或少有过了解,所以能比较快的接收到老师讲的一些知识点,但到了课程中期的时候,也可以说是从老师教正则表达式那里,感觉我接受起来就会有点困难,但是,我也尽量的在课上的时候跟着老师的节奏一步一步来,然后课后也花相应的时间去加深对它的认识。这次大作业我是先跟同学一起讨论先把大致的代码确定,然后再根据自己的年报的信息去进行相应的调整,当然这其中也是在网上查询了相应的代码和借鉴了上学期的学生的一些代码来做参考。在这次实验报告中,我可以说是经历了很长时间的一段磨难,从一开始的从深交所上交所爬取我被分配的行业的公司的信息,再到清理数据,下载要的10年的pdf,以及到后面的用正则写循环提取营业收入,基本每股收益,最后到绘图,其实,这当中的每一步我都花了大量的时间去反复的测验,因为经常这其中一步出错了我就要花很多时间去想怎么解决它,但是,经历这次大作业我对用python进行数据爬取,下载公司年报,用正则表达式对年报信息进行提取等等都有了更进一步的认识。这也进一步加深了我对python的了解和认识。
最后,感谢吴老师这一学期的辛勤的教导,吴老师上课积极负责,学生上课有不懂的问题老师都能很好的解答,同时在课后,学生发邮件给吴老师,老师也耐心的回复学生的问题,给予学生很好的回馈。