#以下是以上市公司“中国重汽”为例的深圳证券交易所年报爬取代码
import re
import requests
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
browser.get('http://www.szse.cn/disclosure/listed/fixed/index.html')
element = browser.find_element(By.ID, 'input_code') # ID定位到搜索框
element.send_keys('中国重汽' + Keys.RETURN)
#模拟键盘输入上市公司名称,手动更换上市公司名称
baogao=browser.find_element(By.CSS_SELECTOR,'#select_gonggao > div > div > a > span.c-selectex-btn-text')
#定位到报告类型选择
nianbao=browser.find_element(By.CSS_SELECTOR,'#c-selectex-menus-3 > li:nth-child(1) > a')#定位到年报选择
baogao.click()#点击报告类型
nianbao.click()#点击选择年报
begin=browser.find_element(By.CSS_SELECTOR,'#query > div.mainquery-container > div:nth-child(5)
> div > div > input.input-left')#定位到开始时间框
end=browser.find_element(By.CSS_SELECTOR,'#query > div.mainquery-container > div:nth-child(5) > div
> div > input.input-right')#定位到结束时间框
begin.send_keys('2013-01-11'+Keys.RETURN)#模拟键盘输入开始时间
end.send_keys('2022-12-11'+Keys.RETURN)#模拟键盘输入结束时间
time.sleep(2)
def element_exist(driver,element): #判断企业年报数量是否存在下一页
flag = True
try:
driver.find_element(By.PARTIAL_LINK_TEXT,element)
return flag
except:
flag = False
return flag
trs=[]
for r in range(5): #这里的最大页数范围我不知道怎么确定,默认爬取五页
time.sleep(2) #这里要加等待时间,不然定位不到下一页的元素
element = browser.find_element(By.ID, 'disclosure-table') # ID定位到年报表格
innerHTML = element.get_attribute('innerHTML') # 获取年报标签下的源代码
f = open('innerHTML.html','w',encoding='utf-8') # 将源代码写入本地文件
f.write(innerHTML)
f.close()
f = open('innerHTML.html',encoding='utf-8') # 读取年报源代码文件
html = f.read()
f.close()
soup = BeautifulSoup(html,features='lxml') #利用bs进行解析
html_prettified = soup.prettify() #格式标准化代码
p = re.compile('(.*?) ', re.DOTALL) #利用正则表达式 找到所需链接的tr标签
tr = p.findall(html_prettified)
trs.extend(tr) #把每一次爬取到的tr标签添加到trs这个空列表中
flag = element_exist(browser,'下一页') #通过写好的函数判断是否有下一页,如果有则循环爬取
if flag:
nextpage = browser.find_element(By.PARTIAL_LINK_TEXT,'下一页') #通过部分文本定位到下一页
nextpage.click() #点击下一页
wait = WebDriverWait(browser, 2)
else: #如果没有下一页,终止爬取
break
prefix = 'https://disc.szse.cn/download' #为后面提取的链接设定好下载前缀网址
prefix_href = 'http://www.szse.cn' #为后面提取的链接设定好查看前缀网址
p2 = re.compile('(.*?)', re.DOTALL) #在tr标签下进一步提取td标签下的内容
tds = [p2.findall(tr) for tr in trs[1:]] #循环搜索提取trs里的所有项目
#注:此处因为前面翻页时,tds列表存在空列表,下面td[0]会报错,要把空列表过滤。
tds = list(filter(None,tds))
p_code = re.compile('(.*?)', re.DOTALL) #在td标签下爬取企业代码,注:tds里的每一个项目都是一个列表
codes = [p_code.search(td[0]).group(1).strip() for td in tds]
p_shortname = p_code #在td标签下爬取企业名字
short_names = [p_shortname.search(td[1]).group(1).strip() for td in tds]
p_link_ftitle = re.compile('(.*?)',
re.DOTALL)
link_ftitles = [p_link_ftitle.findall(td[2])[0] for td in tds] #在td标签下精确提取所需链接
p_pub_time = re.compile('(.*?)', re.DOTALL) #在td标签下爬取年报时间
p_times = [p_pub_time.search(td[3]).group(1) for td in tds]
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [lf[2].strip() for lf in link_ftitles],
'attachpath': [prefix+lf[0].strip() for lf in link_ftitles],
'href': [prefix_href+lf[1].strip() for lf in link_ftitles],
'公告时间': [t.strip() for t in p_times]
}) #将数据导入至dataframe
df.to_csv('data.csv') #将数据写入本地文件
browser.quit() #关闭浏览器
title=[lf[2].strip() for lf in link_ftitles#获取年报时间标题
url= [prefix+lf[0].strip() for lf in link_ftitles]#获取年报下载网址
#以下通过循环下载上市公司年报
for i in range(0,20):
href = url[i]
r = requests.get(href, allow_redirects=True)
f = open('中国重汽'+title[i]+'.pdf', 'wb')#不同上市公司的名称需要自行手动更改
f.write(r.content)
f.close()
r.close()
time.sleep(2)
#以下为爬取上海证券交易所上市公司2016-2018年年报的代码
import re
import requests
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
browser.get('http://www.sse.com.cn/disclosure/listedinfo/announcement/')
element = browser.find_element(By.ID, 'inputCode') # ID定位到搜索框
time.sleep(2)
element.send_keys('600166' + Keys.RETURN)
#模拟键盘输入证券代码,手动更换证券代码即可,‘600741’‘600104’‘601633’‘601238’‘600166’
time.sleep(2)
baogao=browser.find_element(By.CSS_SELECTOR,'body > div.announcement_con > div.container.sse_content > div
> div.col-lg-3.col-xxl-2 > div.search_inputCol > div.sse_outerItem.js_keyWords > div.sse_searchInput > input')
#定位到报告类型选择栏
baogao.send_keys('年度报告'+Keys.RETURN)#模拟键盘输入“年度报告”
time.sleep(2)
nianbao=browser.find_element(By.CSS_SELECTOR,'body > div.announcement_con > div.container.sse_content > div >
div.col-lg-3.col-xxl-2 > div.search_inputCol > div.js_typeListUl > div.announceTypeList > div.announceDiv.
announce-child > ul > li:nth-child(1)')#定位到年报
nianbao.click()#点击年报
time.sleep(1)#浏览器休息1秒
#以下为选择年报时间范围操作
browser.find_element(By.CSS_SELECTOR, ".range_date").click()#定位到时间范围框
browser.find_element(By.CSS_SELECTOR, ".laydate-main-list-0 span:nth-child(1)").click()#选择开始年份
browser.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(5)").click()#选择开始日期
browser.find_element(By.CSS_SELECTOR, ".laydate-main-list-1 span:nth-child(1)").click()#选择结束年份
browser.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(5)").click()#选择结束日期
browser.find_element(By.CSS_SELECTOR, ".laydate-btns-confirm").click()#查询
time.sleep(2)
element = browser.find_element(By.CSS_SELECTOR,'body > div.announcement_con > div.container.sse_content > div >
div.col-lg-9.col-xxl-10 > div.list_tableCol > div > div.table-responsive > table' ) # ID定位到年报表格
innerHTML = element.get_attribute('innerHTML') # 获取年报标签下的源代码
f = open('innerHTML.html','w',encoding='utf-8') # 将源代码写入本地文件
f.write(innerHTML)
f.close()
f = open('innerHTML.html',encoding='utf-8') # 读取年报源代码文件
html = f.read()
f.close()
trs=[]
soup = BeautifulSoup(html,features='lxml') #利用bs进行解析
html_prettified = soup.prettify() #格式标准化代码
p = re.compile('(.*?)', re.DOTALL) #利用正则表达式 找到所需链接的tr标签
tr = p.findall(html_prettified)
trs.extend(tr) #把每一次爬取到的tr标签添加到trs这个空列表中
prefix = 'https:' #为后面提取的链接设定好下载前缀网址
p2 = re.compile('(.*?)', re.DOTALL) #在tr标签下进一步提取td标签下的内容
tds = [p2.findall(tr) for tr in trs[1:]] #循环搜索提取trs里的所有项目
#注:此处因为前面翻页时,tds列表存在空列表,下面td[0]会报错,要把空列表过滤。
tds = list(filter(None,tds))
p_link = re.compile('(.*?)', re.DOTALL) #在td标签下爬取企业代码,注:tds里的每一个项目都是一个列表
title=[p_link.search(td[2]).group(2).strip() for td in tds]
link_ftitles = [p_link.search(td[2]).group(1).strip() for td in tds] #在td标签下精确提取所需链接
codes=tds[0][0]
name=tds[0][1].strip()
#在td标签下爬取年报时间
p_times = [td[4] for td in tds]
df = pd.DataFrame({'证券代码': codes,
'简称': name,
'公告标题': [t for t in title],
'attachpath': [prefix+lf for lf in link_ftitles],
'公告时间': [t.strip() for t in p_times]
}) #将数据导入至dataframe
df.to_csv('data.csv')
#以下为年报下载过程
attachpath= [prefix+lf for lf in link_ftitles]
biaoti=[t for t in title]
for i in range(0,8):#数字可以相应调整
href = attachpath[i]
r = requests.get(href, allow_redirects=True)
f = open(biaoti[i]+'.pdf', 'wb')
f.write(r.content)
f.close()
r.close()
time.sleep(2)
#以下为爬取上海证券交易所上市公司2019-2021年年报的代码
import re
import requests
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
browser.get('http://www.sse.com.cn/disclosure/listedinfo/announcement/')
element = browser.find_element(By.ID, 'inputCode')# ID定位到搜索框
time.sleep(2)
element.send_keys('600166' + Keys.RETURN)
#模拟键盘输入证券代码,手动更换证券代码即可,‘600741’‘600104’‘601633’‘601238’‘600166’
time.sleep(2)
baogao=browser.find_element(By.CSS_SELECTOR,'body > div.announcement_con > div.container.sse_content >
div > div.col-lg-3.col-xxl-2 > div.search_inputCol > div.sse_outerItem.js_keyWords > div.sse_searchInput > input')
#定位到报告类型选择栏
baogao.send_keys('年度报告'+Keys.RETURN)#模拟键盘输入“年度报告”
time.sleep(2)#浏览器休息2秒
nianbao=browser.find_element(By.CSS_SELECTOR,'body > div.announcement_con > div.container.sse_content > div
> div.col-lg-3.col-xxl-2 > div.search_inputCol > div.js_typeListUl > div.announceTypeList > div.announceDiv.
announce-child > ul > li:nth-child(1)')#定位到年报
nianbao.click()#点击年报
time.sleep(1)
#以下为年报时间选择,此时上交所会默认2019-2021年的年报,故无需复杂处理
shijian=browser.find_element(By.CSS_SELECTOR,'body > div.announcement_con > div:nth-child(1) > div >
div.announce_condition > div.announce_todayCon.d-flex.align-items-center.justify-content-between >
div.today_leftDate > span.range_date.js_laydateSearch').click()
time.sleep(1)
button=browser.find_element_by_css_selector('#layui-laydate1 > div.layui-laydate-footer > div > span').click()
#点击查询按钮
time.sleep(2)
element = browser.find_element(By.CSS_SELECTOR,'body > div.announcement_con > div.container.sse_content > div >
div.col-lg-9.col-xxl-10 > div.list_tableCol > div > div.table-responsive > table' ) # ID定位到年报表格
innerHTML = element.get_attribute('innerHTML') # 获取年报标签下的源代码
f = open('innerHTML.html','w',encoding='utf-8') # 将源代码写入本地文件
f.write(innerHTML)
f.close()
f = open('innerHTML.html',encoding='utf-8') # 读取年报源代码文件
html = f.read()
f.close()
trs=[]
soup = BeautifulSoup(html,features='lxml') #利用bs进行解析
html_prettified = soup.prettify() #格式标准化代码
p = re.compile('(.*?)', re.DOTALL) #利用正则表达式 找到所需链接的tr标签
tr = p.findall(html_prettified)
trs.extend(tr) #把每一次爬取到的tr标签添加到trs这个空列表中
prefix = 'https:' #为后面提取的链接设定好下载前缀网址
p2 = re.compile('(.*?)', re.DOTALL) #在tr标签下进一步提取td标签下的内容
tds = [p2.findall(tr) for tr in trs[1:]] #循环搜索提取trs里的所有项目
#注:此处因为前面翻页时,tds列表存在空列表,下面td[0]会报错,要把空列表过滤。
tds = list(filter(None,tds))
p_link = re.compile('(.*?)', re.DOTALL)
#在td标签下爬取企业代码,注:tds里的每一个项目都是一个列表
title=[p_link.search(td[2]).group(2).strip() for td in tds]
link_ftitles = [p_link.search(td[2]).group(1).strip() for td in tds] #在td标签下精确提取所需链接
codes=tds[0][0]
name=tds[0][1].strip()
#在td标签下爬取年报时间
p_times = [td[4] for td in tds]
df = pd.DataFrame({'证券代码': codes,
'简称': name,
'公告标题': [t for t in title],
'attachpath': [prefix+lf for lf in link_ftitles],
'公告时间': [t.strip() for t in p_times]
}) #将数据导入至dataframe
df.to_csv('data.csv')
time.sleep(1)
#以下为年报下载过程
attachpath= [prefix+lf for lf in link_ftitles]
biaoti=[t for t in title]
for i in range(0,6):
href = attachpath[i]
r = requests.get(href, allow_redirects=True)
f = open(biaoti[i]+'.pdf', 'wb')
f.write(r.content)
f.close()
r.close()
time.sleep(2)
#比亚迪年报解析
import fitz
import re
import pandas as pd
shouru=[]
shouyi=[]
name=['比亚迪2012年年度报告.pdf','比亚迪2013年年度报告.pdf','比亚迪2014年年度报告.pdf',
'比亚迪2015年年度报告.pdf','比亚迪2016年年度报告.pdf','比亚迪2017年年度报告.pdf',
'比亚迪2018年年度报告.pdf','比亚迪2019年年度报告.pdf','比亚迪2020年年度报告.pdf',
'比亚迪2021年年度报告.pdf']
#以下为定位财务数据页码过程
class NB():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
doc = fitz.open(name[9])#数字手动更改0-9
sf2021 = NB(name[9])
p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东的净利润)",re.DOTALL)
x1=doc[5].get_text()
x2=doc[6].get_text()
x3=doc[7].get_text()
t=x1+x2+x3
r=p1.findall(t)
a=r[0].split('\n')
# c=a[1].split('.00')
# c[0]=c[0]+'.00' 处理比亚迪2019年年报所做调整
p2=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n加权平均净资产收益率)",re.DOTALL)
r2=p2.findall(t)
while r2==[]:
try:
p3=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n稀释每股收益(元/股))",re.DOTALL)
r2=p3.findall(t)
except Exception:
pass
b=r2[0].split('\n')
shouru.append(a[1])
# s=shouru[7].split('.00')2019年数据稍作处理
# shouru[7]=s[0]+'.00'
shouyi.append(b[1])
p4=re.compile(r"\n股票简称 \n(.*?)股票代码(.*?)\n股票上市证券交易所.*?办公地址(.*?)\n办公地址的邮政编码 .*?
公司网址(.*?)\n电子信箱",re.DOTALL)#提取上市公司信息
info=p4.findall(t)
#将提取数据转成DataFrame形式
d=pd.DataFrame({'股票简称':[t[0] for t in info],
'股票代码':[t[1] for t in info],
'办公地址':[t[2] for t in info],
'公司网址':[t[3] for t in info]})
df=pd.DataFrame({'营业收入':[t for t in shouru],
'基本每股收益':[s for s in shouyi]},index=['2012年','2013年','2014年','2015年',
'2016年','2017年','2018年','2019年','2020年','2021年'])
#将提取的数据存入csv文件
df.to_csv('比亚迪数据.csv')
d.to_csv('比亚迪信息.csv')
#潍柴动力年报解析
import fitz
import re
import pandas as pd
shouru=[]
shouyi=[]
name=['潍柴动力2012年年度报告.pdf','潍柴动力2013年年度报告.pdf','潍柴动力2014年年度报告.pdf',
'潍柴动力2015年年度报告.pdf','潍柴动力2016年年度报告.pdf','潍柴动力2017年年度报告.pdf',
'潍柴动力2018年年度报告.pdf','潍柴动力2019年年度报告.pdf','潍柴动力2020年年度报告.pdf',
'潍柴动力2021年年度报告.pdf']
#以下为定位财务数据页码过程
class NB():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
doc = fitz.open(name[9])#数字手动更改0-9
sf2021 = NB(name[9])
p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n3.17%)",re.DOTALL)
# p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东的净利润)",re.DOTALL)
# p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东的净利\n润)",re.DOTALL)处理2016年年报做的处理
# p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东的\n净利润)",re.DOTALL)处理2014、2017年年报做的处理
x1=doc[5].get_text()
x2=doc[6].get_text()
x3=doc[7].get_text()
x4=doc[8].get_text()
t=x1+x2+x3+x4
r=p1.findall(t)
a=r[0].split('\n')
# h=a[1].split('\n') 处理2014、2015、2016、2018、2021年年报做的处理
# h1=re.compile(r"([\d,.]*).*?58",re.DOTALL) 处理2014年年报做的处理
# h2=h1.findall(h[0])处理2014、2015、2016、2018、2021年年报做的处理
# h1=re.compile(r"([\d,.]*).*?79",re.DOTALL) 处理2015年年报做的处理
# h1=re.compile(r"([\d,.]*).*?73",re.DOTALL)处理2016年年报做的处理
# h1=re.compile(r"([\d,.]*).*?15",re.DOTALL)处理2018年年报做的处理
# h1=re.compile(r"([\d,.]*).*?19",re.DOTALL)处理2021年年报做的处理
p2=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n加权平均净资产收益率)",re.DOTALL)
r2=p2.findall(t)
while r2==[]:
try:
p3=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n稀释每股收益(元/股))",re.DOTALL)
r2=p3.findall(t)
except Exception:
pass
b=r2[0].split('\n')
shouru.append(a[1])
# shouru.append(h2[0])处理2014、2015、2016、2018、2021年年报做的处理
shouyi.append(b[1])
p4=re.compile(r"\nA 股股票简称 \n(.*?)\nA 股股票代码(.*?)\nH 股股票简称.*?办公地址(.*?)\n办公地址的邮政编码 .*?
公司网址(.*?)\n电子信箱",re.DOTALL)#提取上市公司信息
info=p4.findall(t)
# del shouru[9] #便于删去错误的数据
# del shouyi[9]
#将提取数据转成DataFrame形式
d=pd.DataFrame({'股票简称':[t[0] for t in info],
'股票代码':[t[1] for t in info],
'办公地址':[t[2] for t in info],
'公司网址':[t[3] for t in info]})
df=pd.DataFrame({'营业收入':[t for t in shouru],
'基本每股收益':[s for s in shouyi]},index=['2012年','2013年','2014年','2015年',
'2016年','2017年','2018年','2019年','2020年','2021年'])
#将提取到的数据存入csv文件
df.to_csv('潍柴动力数据.csv')
d.to_csv('潍柴动力信息.csv')
#长安汽车年报解析
import fitz
import re
import pandas as pd
shouru=[]
shouyi=[]
name=['长安汽车2012年年度报告.pdf.PDF','长安汽车2013年年度报告(更新后).pdf','长安汽车2014年年度报告.pdf',
'长安汽车2015年年度报告.pdf','长安汽车2016年年度报告.pdf','长安汽车2017年年度报告.pdf',
'长安汽车2018年年度报告.pdf','长安汽车2019年年度报告.pdf','长安汽车2020年年度报告.pdf',
'长安汽车2021年年度报告.pdf']
#以下为定位财务数据页码过程
class NB():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
doc = fitz.open(name[9])#数字手动更改0-9
sf2021 = NB(name[9])
# p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东的净\n利润(元))",re.DOTALL)2019年年报处理
# p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东的净\n利润(元))",re.DOTALL)2018年年报处理
# p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东\n的净利润(元) )",re.DOTALL)2017、2021年年报处理
p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东的净利润)",re.DOTALL)
# p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东\n的净利润(元))",re.DOTALL)2016、2020年年报处理
# p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股\n东的净利润(元))",re.DOTALL)2014年年报处理
# p1=re.compile(r"(?<=\n)(调整后 \n营业收入(元).*?)(?=\n归属于上市公\n司股东的净利\n润(元))",re.DOTALL)2015年年报处理
x1=doc[5].get_text()
x2=doc[6].get_text()
x3=doc[7].get_text()
x4=doc[4].get_text()
t=x1+x2+x3+x4
r=p1.findall(t)
a=r[0].split('\n')
# h=a[1].split('\n') 2014年年报处理
# h1=re.compile(r"([\d,.]*).*?38",re.DOTALL)
# h2=h1.findall(h[0])
# p2=re.compile(r"(?<=\n)(基本每股收益(元/\n股).*?)(?=\n加权平均净资产收\n益率)",re.DOTALL) 2014年年报处理
# p2=re.compile(r"(?<=\n)(基本每股收益\n(元/股).*?)(?=\n稀释每股收益\n(元/股))",re.DOTALL)2015年年报处理
# p2=re.compile(r"(?<=\n)(基本每股收益(元/\n股).*?)(?=\n稀释每股收益(元/\n股))",re.DOTALL)2016、2021年年报处理
p2=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n加权平均净资产收益率)",re.DOTALL)
# p2=re.compile(r"(?<=\n)(基本每股收益(元/\n股).*?)(?=\n稀释每股收益(元/\n股))",re.DOTALL)
# p2=re.compile(r"(?<=\n)(基本每股收益(元/\n股).*?)(?=\n稀释每股收益(元/\n股))",re.DOTALL)2017年年报处理
r2=p2.findall(t)
while r2==[]:
try:
p3=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n稀释每股收益(元/股))",re.DOTALL)
r2=p3.findall(t)
except Exception:
pass
b=r2[0].split('\n')
# # del shouru[3] 方便处理数据
# # del shouyi[9]
shouru.append(a[1])
shouyi.append(b[1])
# shouru.append(a[3]) 2015年年报处理
# shouru.append(h2[0]) 2014年年报处理
# shouyi.append(b[2].strip())2016、2017、2021年年报处理
# shouyi.append(b[2]) 2015年年报处理
# shouyi.append(b[2]) 2014年年报处理
p4=re.compile(r"\n股票简称 \n(.*?)\n股票代码(.*?)\n股票上市证券交易所.*?办公地址(.*?)\n办公地址的邮政编码 .*?
公司网址(.*?)\n电子信箱",re.DOTALL#提取上市公司信息
info=p4.findall(t)
#将提取数据转成DataFrame形式
d=pd.DataFrame({'股票简称':[t[0] for t in info],
'股票代码':[t[1] for t in info],
'办公地址':[t[2] for t in info],
'公司网址':[t[3] for t in info]})
df=pd.DataFrame({'营业收入':[t for t in shouru],
'基本每股收益':[s for s in shouyi]},index=['2012年','2013年','2014年','2015年','2016年',
'2017年','2018年','2019年','2020年','2021年'])
#将提取的数据存入csv文件
df.to_csv('长安汽车数据.csv')
d.to_csv('长安汽车信息.csv')
#一汽解放年报解析
import fitz
import re
import pandas as pd
shouru=[]
shouyi=[]
name=['一汽解放2012年年度报告.pdf.PDF','一汽解放2013年年度报告.pdf.PDF','一汽解放2014年年度报告.pdf.PDF',
'一汽解放2015年年度报告.pdf.PDF','一汽解放2016年年度报告.pdf.PDF','一汽解放2017年年度报告.pdf.PDF',
'一汽解放2018年年度报告.pdf.PDF','一汽解放2019年年度报告.pdf.PDF','一汽解放2020年年度报告.pdf',
'一汽解放2021年年度报告.pdf']
#以下为定位财务数据页码过程
class NB():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
doc = fitz.open(name[9])#数字手动更改0-9
sf2021 = NB(name[9])
p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东的净利润)",re.DOTALL)
# p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东的净\n利润(元) )",re.DOTALL) 处理2013年年报
#p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司\n股东的净利润\n(元))",re.DOTALL) 处理2014年年报
#p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东的净利润(元))",re.DOTALL)处理2015、2019年年报
#p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东的净利\n润(元))",re.DOTALL) 处理2016、2018年年报
#p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东的\n净利润(元) )",re.DOTALL) 处理2020年年报
#p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东的净利\n润(元) )",re.DOTALL)处理2021年年报
x1=doc[5].get_text()
x2=doc[6].get_text()
x3=doc[7].get_text()
t=x1+x2+x3
r=p1.findall(t)
a=r[0].split('\n')
h=a[1].split('\n')
# h1=re.compile(r"([\d,.]*).*?32",re.DOTALL) 处理2012年年报
# h1=re.compile(r"([\d,.]*).*?23",re.DOTALL) 处理2013年年报
#h1=re.compile(r"营业收入(元) ([\d,.]*).*?29",re.DOTALL) 处理2014年年报
#h1=re.compile(r"([\d,.]*).*?33",re.DOTALL) 处理2015年年报
#h1=re.compile(r"([\d,.]*).*?26",re.DOTALL) 处理2016年年报
#h1=re.compile(r"([\d,.]*).*?22",re.DOTALL) 处理2017年年报
#h1=re.compile(r"([\d,.]*).*?27",re.DOTALL) 处理2018年年报
#h1=re.compile(r"([\d,.]*).*?26",re.DOTALL) 处理2019年年报
#h1=re.compile(r"([\d,.]*).*?27",re.DOTALL) 处理2020年年报
h1=re.compile(r"([\d,.]*).*?113",re.DOTALL)#处理2021年年报
h2=h1.findall(h[0])
p2=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n加权平均净资产收益率)",re.DOTALL)
#p2=re.compile(r"(?<=\n)(基本每股收益(元\n/股).*?)(?=\n稀释每股收益(元\n/股))",re.DOTALL) #处理2014年年报
r2=p2.findall(t)
while r2==[]:
try:
p3=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n稀释每股收益(元/股))",re.DOTALL)
r2=p3.findall(t)
except Exception:
pass
b=r2[0].split('\n')
#del shouru[3]
#del shouyi[4]
#shouru.append(a[1])
shouru.append(h2[0]) # 处理2012、2013、2014、2015、2016、2017、2018、2019、2020、2021年年报
shouyi.append(b[1])
#shouyi.append(b[2])处理2014年年报
p4=re.compile(r"\n股票简称 \n(.*?)股票代码(.*?)\n股票上市证券交易所.*?办公地址(.*?)\n办公地址的邮政编码 .*?
公司网址(.*?)\n电子信箱",re.DOTALL)#提取上市公司信息
info=p4.findall(t)
#将提取数据转成DataFrame形式
d=pd.DataFrame({'股票简称':[t[0] for t in info],
'股票代码':[t[1] for t in info],
'办公地址':[t[2] for t in info],
'公司网址':[t[3] for t in info]})
df=pd.DataFrame({'营业收入':[t for t in shouru],
'基本每股收益':[s for s in shouyi]},index=['2012年','2013年','2014年','2015年','2016年',
'2017年','2018年','2019年','2020年','2021年'])
#将提取的数据存入csv文件
df.to_csv('一汽解放数据.csv')
d.to_csv('一汽解放信息.csv')
#中国重汽年报解析
import fitz
import re
import pandas as pd
shouru=[]
shouyi=[]
name=['中国重汽2012年年度报告.pdf.PDF','中国重汽2013年年度报告.pdf','中国重汽2014年年度报告.pdf',
'中国重汽2015年年度报告.pdf','中国重汽2016年年度报告.pdf','中国重汽2017年年度报告(更新后).pdf',
'中国重汽2018年年度报告.pdf','中国重汽2019年年度报告.pdf','中国重汽2020年年度报告.pdf',
'中国重汽2021年年度报告.pdf']
#以下为定位财务数据页码过程
class NB():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
doc = fitz.open(name[9])#数字手动更改0-9
sf2021 = NB(name[9])
p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东的净利润)",re.DOTALL)
# p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股\n东的净利润(元))",re.DOTALL) #2018年年报处理
x1=doc[5].get_text()
x2=doc[6].get_text()
x3=doc[7].get_text()
x4=doc[8].get_text()
x5=doc[9].get_text()
t=x1+x2+x3+x4+x5
r=p1.findall(t)
a=r[0].split('\n')
p2=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n加权平均净资产收益率)",re.DOTALL)
# p2=re.compile(r"(?<=\n)(基本每股收益(元/\n股).*?)(?=\n稀释每股收益(元/\n股))",re.DOTALL)#2018年年报处理
r2=p2.findall(t)
while r2==[]:
try:
p3=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n稀释每股收益(元/股))",re.DOTALL)
r2=p3.findall(t)
except Exception:
pass
b=r2[0].split('\n')
# del shouru[6] #方便处理数据,删除错误数据
# del shouyi[6]
#h1=re.compile(r"([\d,.]*).*?21",re.DOTALL) #2017年年报处理
# h1=re.compile(r"([\d,.]*).*?37",re.DOTALL) #2018年年报处理
# h2=h1.findall(a[1])
# shouru.append(h2[0])
shouru.append(a[1])
shouyi.append(b[1])
# shouyi.append(b[2]) 2018年年报处理
p4=re.compile(r"\n股票简称 \n(.*?)股票代码(.*?)\n股票上市证券交易所.*?办公地址(.*?)\n办公地址的邮政编码 .*?
公司网址(.*?)\n电子信箱",re.DOTALL)
info=p4.findall(t)
#将提取数据转成DataFrame形式
d=pd.DataFrame({'股票简称':[t[0] for t in info],
'股票代码':[t[1] for t in info],
'办公地址':[t[2] for t in info],
'公司网址':[t[3] for t in info]})
df=pd.DataFrame({'营业收入':[t for t in shouru],
'基本每股收益':[s for s in shouyi]},index=['2012年','2013年','2014年','2015年','2016年',
'2017年','2018年','2019年','2020年','2021年'])
#将提取的数据存入csv文件
df.to_csv('中国重汽数据.csv')
d.to_csv('中国重汽信息.csv')
#福田汽车年报解析
import fitz
import re
import pandas as pd
shouru=[]
shouyi=[]
name=['福田汽车2016年年度报告.pdf','福田汽车2017年年度报告.pdf', '福田汽车2018年年度报告.pdf',
'福田汽车2019年年度报告(修订版).pdf','福田汽车2020年度报告全文.pdf', '福田汽车2021年度报告全文.pdf']
#以下为定位财务数据页码过程
class NB():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
doc = fitz.open(name[5])#数字手动更改0-5
sf2021 = NB(name[5])
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司股东的\n净利润 )",re.DOTALL) 2016年年报处理
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司\n股东的净利润 )",re.DOTALL) 2017、2018年年报处理
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司股\n东的净利润)",re.DOTALL) 2019年年报处理
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n扣除与主营业务无关\n的业务收入和不具备\n商业实质的收入后的
\n营业收入 )",re.DOTALL) 2020年年报处理
p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n扣除与主营业\n务无关的业务\n收入和不具备\n商业实质的收\n入后的
营业收\n入)",re.DOTALL) #2020年年报处理
x1=doc[2].get_text()#这个部分不同年报不一样需具体分析筛选
x2=doc[3].get_text()
x3=doc[4].get_text()
x4=doc[5].get_text()
# x5=doc[8].get_text()
# x6=doc[9].get_text()
# x7=doc[10].get_text()
# x8=doc[11].get_text()
# x9=doc[12].get_text()
t=x1+x2+x3+x4
r=p1.findall(t)
a=r[0].split('\n')
# a=r[0].split('\n51') #2018年年报处理
p2=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n加权平均净资产收益率)",re.DOTALL)
r2=p2.findall(t)
while r2==[]:
try:
p3=re.compile(r"(?<=\n)(基本每股收益(元/股) .*?)(?=\n稀释每股收益(元/股))",re.DOTALL)
r2=p3.findall(t)
except Exception:
pass
b=r2[0].split('\n')
# shouru.append(a[1])
# h1=re.compile(r"([\d,.]*).*?33,9",re.DOTALL) #2016年年报处理
# h1=re.compile(r"([\d,.]*).*?46,5",re.DOTALL) #2017年年报处理
# h1=re.compile(r"\n([\d,]*\n.\d+)",re.DOTALL) #2018年年报处理
# h1=re.compile(r"\n([\d,.]*).*?41,0",re.DOTALL) #2019年年报处理
# h1=re.compile(r"([\d,.]*).*?46,9",re.DOTALL) #2020年年报处理
h1=re.compile(r"([\d,.]*).*?57,7",re.DOTALL)#2021年年报处理
h2=h1.findall(a[1])
# h2=h1.findall(a[0]) 2018、2019年年报处理
# h2[0]=h2[0].replace('\n','')2018年年报处理
shouru.append(h2[0])
# del shouru[3] #方便数据处理
# del shouyi[4]
shouyi.append(b[1])
p4=re.compile(r"公司办公地址(.*?)\n公司办公地址的邮政编码 .*?公司网址(.*?)\n电子信箱.*?\n
上海证券交易所 \n(.*?)(\n.*?)\n福田股份 ",re.DOTALL)
info=p4.findall(t)
#将提取数据转成DataFrame形式
d=pd.DataFrame({'股票简称':[t[2] for t in info],
'股票代码':[t[3] for t in info],
'办公地址':[t[0] for t in info],
'公司网址':[t[1] for t in info]})
df=pd.DataFrame({'营业收入':[t.strip() for t in shouru],
'基本每股收益':[s for s in shouyi]},index=['2016年','2017年','2018年',
'2019年','2020年','2021年'])
#将提取的数据存入csv文件
df.to_csv('福田汽车数据.csv')
d.to_csv('福田汽车信息.csv')
#华域汽车年报解析
import fitz
import re
import pandas as pd
shouru=[]
shouyi=[]
name=['华域汽车2015年度报告.pdf','华域汽车2016年年度报告.pdf','华域汽车2017年年度报告.pdf',
'华域汽车2018年年度报告.pdf','华域汽车2019年年度报告.pdf','华域汽车2020年年度报告.pdf',
'华域汽车2021年年度报告.pdf'] #华域汽车在上交所只能下载2015年之后的年报
#以下为定位财务数据页码过程
class NB():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
doc = fitz.open(name[6])#数字手动更改0-6
sf2021 = NB(name[6])
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司股东的净利润)",re.DOTALL) 2015年年报处理
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司股\n东的净利润)",re.DOTALL)2016年年报处理
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司股东的净利\n润)",re.DOTALL) 2017年年报处理
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司股东\n的净利润)",re.DOTALL) 2018、2019年年报处理
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司股\n东的净利润)",re.DOTALL) 2020年年报处理
p1=re.compile(r"(?<=\n)(营业收入.*?)(?= \n归属于上市公司\n股东的净利润)",re.DOTALL)#2021年年报处理
x1=doc[2].get_text()
x2=doc[3].get_text()
x3=doc[4].get_text()
x4=doc[5].get_text()
x5=doc[6].get_text()
x6=doc[7].get_text()
t=x1+x2+x3+x4+x5+x6
r=p1.findall(t)
a=r[0].split('\n')
# p2=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n加权平均净资产收益率)",re.DOTALL)
p2=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n稀释每股收益(元/股))",re.DOTALL)
r2=p2.findall(t)
while r2==[]:
try:
p3=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n稀释每股收益(元/股))",re.DOTALL)
r2=p3.findall(t)
except Exception:
pass
b=r2[0].split('\n')
# shouru.append(a[1]) 2019年年报处理
#del shouru[4]
# h1=re.compile(r"([\d,.]*).*?73",re.DOTALL) #2015年年报处理
#h1=re.compile(r"([\d,.]*).*?105",re.DOTALL) 2016年年报处理
# h1=re.compile(r"([\d,.]*).*?124",re.DOTALL) 2017年年报处理
# h1=re.compile(r"([\d,.]*).*?157",re.DOTALL) 2018年年报处理
h1=re.compile(r"([\d,.]*).*?133",re.DOTALL) #2021年年报处理
h2=h1.findall(a[1])
shouru.append(h2[0])
shouyi.append(b[1])
p4=re.compile(r"\n公司办公地址(.*?)\n公司办公地址的邮政编码 .*?公司网址(.*?)\n电子信箱.*?\n股票简称.*?
\n上海证券交易所 \n(.*?)\n巴士股份�",re.DOTALL)
info=p4.findall(t)
x=info[0][2].split("\n")#将提取的股票简称与股票代码分离
#将提取数据转成DataFrame形式
d=pd.DataFrame({'股票简称':[x[0]],
'股票代码':[x[1]],
'办公地址':[t[0] for t in info],
'公司网址':[t[1] for t in info]})
df=pd.DataFrame({'营业收入':[t for t in shouru],
'基本每股收益':[s for s in shouyi]},index=['2015年','2016年','2017年','2018年',
'2019年','2020年','2021年'])
#将提取的数据存入csv文件
df.to_csv('华域汽车数据.csv')
d.to_csv('华域汽车信息.csv')
#上汽集团年报解析
import fitz
import re
import pandas as pd
shouru=[]
shouyi=[]
name=['上汽集团2016年年度报告.pdf','上汽集团2017年年度报告.pdf', '上汽集团2018年年度报告.pdf',
'上汽集团2019年年度报告.pdf','上汽集团2020年年度报告.pdf', '上汽集团2021年年度报告.pdf']
#以下为定位财务数据页码过程
class NB():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
doc = fitz.open(name[5])#数字手动更改0-5
sf2021 = NB(name[5])
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司股东的净\n利润)",re.DOTALL) 2016年年报处理
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司股\n东的净利润)",re.DOTALL) 2017年年报处理
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司股东的净利润)",re.DOTALL) 2018、2019、2020、2021年年报处理
p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司股东的净利润)",re.DOTALL)
x1=doc[3].get_text()
x2=doc[4].get_text()
x3=doc[5].get_text()
t=x1+x2+x3
r=p1.findall(t)
a=r[0].split('\n')
p2=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n加权平均净资产收益率)",re.DOTALL)
r2=p2.findall(t)
while r2==[]:
try:
p3=re.compile(r"(?<=\n)(基本每股收益(元/股) .*?)(?=\n稀释每股收益(元/股))",re.DOTALL)
r2=p3.findall(t)
except Exception:
pass
b=r2[0].split('\n')
shouru.append(a[1])
shouyi.append(b[1])
p4=re.compile(r"公司办公地址(.*?)\n公司办公地址的邮政编码 .*?公司网址(.*?)\n电子信箱.*?\n
上海证券交易所 (.*?) \n(.*?)上海汽车 ",re.DOTALL)
info=p4.findall(t)
#将提取数据转成DataFrame形式
d=pd.DataFrame({'股票简称':[t[2] for t in info],
'股票代码':[t[3] for t in info],
'办公地址':[t[0] for t in info],
'公司网址':[t[1] for t in info]})
df=pd.DataFrame({'营业收入':[t for t in shouru],
'基本每股收益':[s for s in shouyi]},index=['2016年','2017年','2018年',
'2019年','2020年','2021年'])
#将提取的数据存入csv文件
df.to_csv('上汽集团数据.csv')
d.to_csv('上汽集团信息.csv')
#长城汽车年报解析
import fitz
import re
import pandas as pd
shouru=[]
shouyi=[]
name=['长城汽车2016年年度报告.pdf','长城汽车2017年年度报告.pdf', '长城汽车2018年年度报告.pdf',
'长城汽车2019年年度报告.pdf','长城汽车股份有限公司2020年年度报告.pdf', '长城汽车股份有限公司2021年年度报告.pdf']
#以下为定位财务数据页码过程
class NB():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
doc = fitz.open(name[5])#数字手动更改0-5
sf2021 = NB(name[5])
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司股东的净利润)",re.DOTALL)
# 2016、2019、2020、2021年年报处理
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市\n公司股东的\n净利润)",re.DOTALL) 2017年年报处理
#p1=re.compile(r"(?<=\n)(营业收\n入.*?)(?=\n归属于\n上市公\n司股东\n的净利\n润)",re.DOTALL)#2018年年报处理
p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司股东的净利润 )",re.DOTALL)
x1=doc[3].get_text()#这个部分不同年报不一样需具体分析筛选
x2=doc[4].get_text()
x3=doc[5].get_text()
x4=doc[7].get_text()
x5=doc[8].get_text()
x6=doc[9].get_text()
x7=doc[10].get_text()
x8=doc[11].get_text()
x9=doc[12].get_text()
t=x1+x2+x3+x4+x5+x6+x7+x8+x9
r=p1.findall(t)
a=r[0].split('\n')
p2=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n加权平均净资产收益率)",re.DOTALL)
r2=p2.findall(t)
while r2==[]:
try:
p3=re.compile(r"(?<=\n)(基本每股收益(元/股) .*?)(?=\n稀释每股收益(元/股))",re.DOTALL)
r2=p3.findall(t)
except Exception:
pass
b=r2[0].split('\n')
shouru.append(a[1])
# h1=re.compile(r"([\d,.]*).*?10,0",re.DOTALL) #2018年年报处理
# h2=h1.findall(a[2])
# shouru.append(h2[0])
# del shouru[4] 方便数据处理
# del shouyi[4]
# b1=re.compile(r"([\d,.]*).*?0.55",re.DOTALL)#2018年年报处理
# b2=b1.findall(b[1])
# shouyi.append(b2[0])
shouyi.append(b[1])
p4=re.compile(r"公司办公地址(.*?)\n公司办公地址的邮政编码 .*?公司网址(.*?)\n电子信箱.*?\n
上交所 (.*?) \n(.*?)\n— \nH股 ",re.DOTALL)
info=p4.findall(t)
#将提取数据转成DataFrame形式
d=pd.DataFrame({'股票简称':[t[2] for t in info],
'股票代码':[t[3] for t in info],
'办公地址':[t[0] for t in info],
'公司网址':[t[1] for t in info]})
df=pd.DataFrame({'营业收入':[t.strip() for t in shouru],
'基本每股收益':[s for s in shouyi]},index=['2016年','2017年','2018年',
'2019年','2020年','2021年'])
#将提取的数据存入csv文件
df.to_csv('长城汽车数据.csv')
d.to_csv('长城汽车信息.csv')
#广汽集团年报解析
import fitz
import re
import pandas as pd
shouru=[]
shouyi=[]
name=['广汽集团2016年年度报告.pdf','广汽集团2017年年度报告.pdf', '广汽集团2018年年度报告.pdf',
'广汽集团2019年年度报告.pdf','广汽集团2020年年度报告.pdf', '广汽集团2021年年度报告摘要.pdf']
#以下为定位主要财务数据页码过程
class NB():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
doc = fitz.open(name[2])#数字手动更改0-5
sf2021 = NB(name[2])
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司股东的净利润 )",re.DOTALL) 2016、2018、2019 年年报处理
# p1=re.compile(r"(?<=\n)(营业收入.*?)(?=\n归属于上市公司股东\n的净利润)",re.DOTALL) 2017 年年报处理
# p1=re.compile(r"(?<=\n其中:)(营业收入.*?)(?=\n利息收入)",re.DOTALL) 2020年年报处理
p1=re.compile(r"(?<=\n)(营业收入.*?)(?= \n归属于上市公司股东的\n净利润 )",re.DOTALL)
x1=doc[7].get_text()#这个部分不同年报不一样需具体分析筛选 2020年在124、125页,
#2016-2018年大概在6、7、8、9、10页。2021年在3、4、5、6页。
x2=doc[8].get_text()
x3=doc[9].get_text()
x4=doc[10].get_text()
t=x1+x2+x3+x4
r=p1.findall(t)
a=r[0].split('\n')
p2=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n加权平均净资产收益率)",re.DOTALL)
# p2=re.compile(r"(?<=\n七、70)(.*?)(?=\n(二)稀释每股收益(元/股) )",re.DOTALL) 2020年年报处理
r2=p2.findall(t)
while r2==[]:
try:
p3=re.compile(r"(?<=\n)(基本每股收益(元/股) .*?)(?=\n稀释每股收益(元/股))",re.DOTALL)
r2=p3.findall(t)
except Exception:
pass
b=r2[0].split('\n')
shouru.append(a[1])
# shouru.append(a[2]) 2020年年报处理
# h1=re.compile(r"([\d,.]*).*?49",re.DOTALL) #2017年年报处理
# h1=re.compile(r"([\d,.]*).*?62",re.DOTALL)#2021年年报处理
# h2=h1.findall(a[1])
# shouru.append(h2[0])
# del shouru[5]方便数据处理
# del shouyi[4]
shouyi.append(b[1])
# shouyi.append(b[2]) 2020年年报处理
p4=re.compile(r"公司办公地址(.*?)\n公司办公地址的邮政编码 .*?公司网址(.*?)\n电子信箱 .* \n
上海证券交易所 (\n.*?)(\n.*?) \nH股 \n香港联合交易所",re.DOTALL)
info=p4.findall(t)
#将提取数据转成DataFrame形式
d=pd.DataFrame({'股票简称':[t[2] for t in info],
'股票代码':[t[3] for t in info],
'办公地址':[t[0] for t in info],
'公司网址':[t[1] for t in info]})
df=pd.DataFrame({'营业收入':[t.strip() for t in shouru],
'基本每股收益':[s for s in shouyi]},index=['2016年','2017年','2018年',
'2019年','2020年','2021年'])
#将提取的数据存入csv文件
df.to_csv('广汽集团数据.csv')
d.to_csv('广汽集团信息.csv')
#各上市公司营业收入绘图代码
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv('长城汽车数据.csv', header=None)#手动更改文件名
df.head()
x=df[1]#提取营业收入数据
a=x.tolist()#将数据类型series改为list
del a[0]#删去文字‘营业收入’
c=[x.replace(',','') for x in a]#将数据里的逗号去掉
d=[float(i) for i in c]#将数据类型由字符串改为浮点数
# sign=['2012','2013','2014','2015','2016','2017','2018','2019','2020','2021']
#由于有些公司年报是从2015、2016年开始的,故有三个sign进行转化
sign=['2016','2017','2018','2019','2020','2021']
#sign=['2015','2016','2017','2018','2019','2020','2021']
plt.xlabel('年份')
plt.ylabel('营业收入/元')
plt.rcParams['font.sans-serif']=['SimHei']#设置正常显示中文,字体为黑体
plt.title("长城汽车2016-2021年营业收入")#手动变化标题
plt.bar(x=sign,height=d)
plt.savefig('长城汽车2016-2021年营业收入.png')#保存图片
plt.show()
#各上市公司基本每股收益绘图代码
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv('长城汽车数据.csv', header=None)#手动更改文件名
df.head()
x=df[2]#提取基本每股收益数据
a=x.tolist()#将数据类型series改为list
del a[0]#删去文字‘基本每股收益’
c=[x.replace(',','') for x in a]#将数据里的逗号去掉
d=[float(i) for i in c]#将数据类型由字符串改为浮点数
# sign=['2012','2013','2014','2015','2016','2017','2018','2019','2020','2021']
#由于有些公司年报是从2015、2016年开始的,故有三个sign进行转化
sign=['2016','2017','2018','2019','2020','2021']
#sign=['2015','2016','2017','2018','2019','2020','2021']
plt.xlabel('年份')
plt.ylabel('基本每股收益/元')
plt.rcParams['font.sans-serif']=['SimHei']#设置正常显示中文,字体为黑体
plt.rcParams['axes.unicode_minus']=False#正确显示负号
plt.title("长城汽车2016-2021年基本每股收益")#手动变化标题
plt.bar(x=sign,height=d)
plt.savefig('长城汽车2016-2021年基本每股收益.png')#保存图片
plt.show()
#各上市公司营业收入比较绘图代码
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
name=['比亚迪','潍柴动力','一汽解放','长安汽车','中国重汽']
name1='华域汽车'
name2=['福田汽车','广汽集团','上汽集团','长城汽车']
name3=['比亚迪','潍柴动力','一汽解放','长安汽车','中国重汽','华域汽车']
name4=['比亚迪','潍柴动力','一汽解放','长安汽车','中国重汽','华域汽车','福田汽车',
'广汽集团','上汽集团','长城汽车']
shouru=[]
for i in name:
df = pd.read_csv(i+'数据.csv', header=None)
df.head()
x=df[1]#提取营业收入数据
a=x.tolist()#将数据类型series改为list
del a[0]#删去文字‘营业收入’
c=[x.replace(',','') for x in a]#将数据里的逗号去掉
d=[float(i) for i in c]#将数据类型由字符串改为浮点数
#shouru.append(d[0])#添加不同公司2012年的营业收入数据
#shouru.append(d[1])#添加不同公司2013年的营业收入数据
#shouru.append(d[2])#添加不同公司2014年的营业收入数据
#shouru.append(d[3])#添加不同公司2015年的营业收入数据
#shouru.append(d[4])#添加不同公司2016年的营业收入数据
#shouru.append(d[5])#添加不同公司2017年的营业收入数据
#shouru.append(d[6])#添加不同公司2018年的营业收入数据
#shouru.append(d[7])#添加不同公司2019年的营业收入数据
#shouru.append(d[8])#添加不同公司2020年的营业收入数据
shouru.append(d[9])#添加不同公司2021年的营业收入数据
df1= pd.read_csv(name1+'数据.csv', header=None)
df1.head()
x1=df1[1]#提取营业收入数据
a1=x1.tolist()#将数据类型series改为list
del a1[0]#删去文字‘营业收入’
c1=[x.replace(',','') for x in a1]#将数据里的逗号去掉
d1=[float(i) for i in c1]
#shouru.append(d1[0])#加入华域汽车2015年数据
#shouru.append(d1[1])#加入华域汽车2016年数据
#shouru.append(d1[2])#加入华域汽车2017年数据
#shouru.append(d1[3])#加入华域汽车2018年数据
#shouru.append(d1[4])#加入华域汽车2019年数据
#shouru.append(d1[5])#加入华域汽车2020年数据
shouru.append(d1[6])#加入华域汽车2021年数据
for i in name2:
df2 = pd.read_csv(i+'数据.csv', header=None)
df2.head()
x2=df2[1]#提取营业收入数据
a2=x2.tolist()#将数据类型series改为list
del a2[0]#删去文字‘营业收入’
c2=[x.replace(',','') for x in a2]#将数据里的逗号去掉
d2=[float(i) for i in c2]#将数据类型由字符串改为浮点数
#shouru.append(d2[0])#添加不同公司2016年的营业收入数据
#shouru.append(d2[1])#添加不同公司2017年的营业收入数据
#shouru.append(d2[2])#添加不同公司2018年的营业收入数据
#shouru.append(d2[3])#添加不同公司2019年的营业收入数据
#shouru.append(d2[4])#添加不同公司2020年的营业收入数据
shouru.append(d2[5])#添加不同公司2021年的营业收入数据
plt.rcParams['font.sans-serif']=['SimHei']#设置正常显示中文,字体为黑体
plt.figure(dpi=100)#设置清晰度
plt.xticks(rotation=-20)#将x轴下各公司名称旋转一定角度避免重叠
plt.xlabel('上市公司名称')
plt.ylabel('营业收入/元')
plt.title("2021年上市公司营业收入比较")#手动变化标题
#plt.bar(x=name,height=shouru) 2012-2014年数据
#plt.bar(x=name3,height=shouru) 2015年数据
plt.bar(x=name4,height=shouru)
plt.savefig('2021年上市公司营业收入比较.png')#保存图片,手动变化文件名
plt.show()
#各上市公司基本每股收益比较绘图代码
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
name=['比亚迪','潍柴动力','一汽解放','长安汽车','中国重汽']
name1='华域汽车'
name2=['福田汽车','广汽集团','上汽集团','长城汽车']
name3=['比亚迪','潍柴动力','一汽解放','长安汽车','中国重汽','华域汽车']
name4=['比亚迪','潍柴动力','一汽解放','长安汽车','中国重汽','华域汽车',
'福田汽车','广汽集团','上汽集团','长城汽车']
shouyi=[]
for i in name:
df = pd.read_csv(i+'数据.csv', header=None)
df.head()
x=df[2]#提取基本每股收益数据
a=x.tolist()#将数据类型series改为list
del a[0]#删去文字‘基本每股收益’
c=[x.replace(',','') for x in a]#将数据里的逗号去掉
d=[float(i) for i in c]#将数据类型由字符串改为浮点数
#shouyi.append(d[0])#添加不同公司2012年的基本每股收益数据
#shouyi.append(d[1])#添加不同公司2013年的基本每股收益数据
#shouyi.append(d[2])#添加不同公司2014年的基本每股收益数据
#shouyi.append(d[3])#添加不同公司2015年的基本每股收益数据
#shouyi.append(d[4])#添加不同公司2016年的基本每股收益数据
#shouyi.append(d[5])#添加不同公司2017年的基本每股收益数据
#shouyi.append(d[6])#添加不同公司2018年的基本每股收益数据
#shouyi.append(d[7])#添加不同公司2019年的基本每股收益数据
#shouyi.append(d[8])#添加不同公司2020年的基本每股收益数据
shouyi.append(d[9])#添加不同公司2021年的基本每股收益数据
df1= pd.read_csv(name1+'数据.csv', header=None)
df1.head()
x1=df1[2]#基本每股收益数据
a1=x1.tolist()#将数据类型series改为list
del a1[0]#删去文字‘基本每股收益’
c1=[x.replace(',','') for x in a1]#将数据里的逗号去掉
d1=[float(i) for i in c1]
#shouyi.append(d1[0])#加入华域汽车2015年数据
#shouyi.append(d1[1])#加入华域汽车2016年数据
#shouyi.append(d1[2])#加入华域汽车2017年数据
#shouyi.append(d1[3])#加入华域汽车2018年数据
#shouyi.append(d1[4])#加入华域汽车2019年数据
#shouyi.append(d1[5])#加入华域汽车2020年数据
shouyi.append(d1[6])#加入华域汽车2021年数据
for i in name2:
df2 = pd.read_csv(i+'数据.csv', header=None)
df2.head()
x2=df2[2]#提取基本每股收益数据
a2=x2.tolist()#将数据类型series改为list
del a2[0]#删去文字‘基本每股收益’
c2=[x.replace(',','') for x in a2]#将数据里的逗号去掉
d2=[float(i) for i in c2]#将数据类型由字符串改为浮点数
#shouyi.append(d2[0])#添加不同公司2016年的基本每股收益数据
#shouyi.append(d2[1])#添加不同公司2017年的基本每股收益数据
#shouyi.append(d2[2])#添加不同公司2018年的基本每股收益数据
#shouyi.append(d2[3])#添加不同公司2019年的基本每股收益数据
#shouyi.append(d2[4])#添加不同公司2020年的基本每股收益数据
shouyi.append(d2[5])#添加不同公司2021年的基本每股收益数据
plt.rcParams['font.sans-serif']=['SimHei']#设置正常显示中文,字体为黑体
plt.rcParams['axes.unicode_minus']=False#正确显示负号
plt.figure(dpi=100)#设置清晰度
plt.xticks(rotation=-20)#将x轴下各公司名称旋转一定角度避免重叠
plt.xlabel('上市公司名称')
plt.ylabel('基本每股收益/元')
plt.title("2021年上市公司基本每股收益比较")#手动变化标题
#plt.bar(x=name,height=shouru) 2012-2014年数据
#plt.bar(x=name3,height=shouru) 2015年数据
plt.bar(x=name4,height=shouyi)
plt.savefig('2021年上市公司基本每股收益比较.png')#保存图片,手动变化文件名
plt.show()

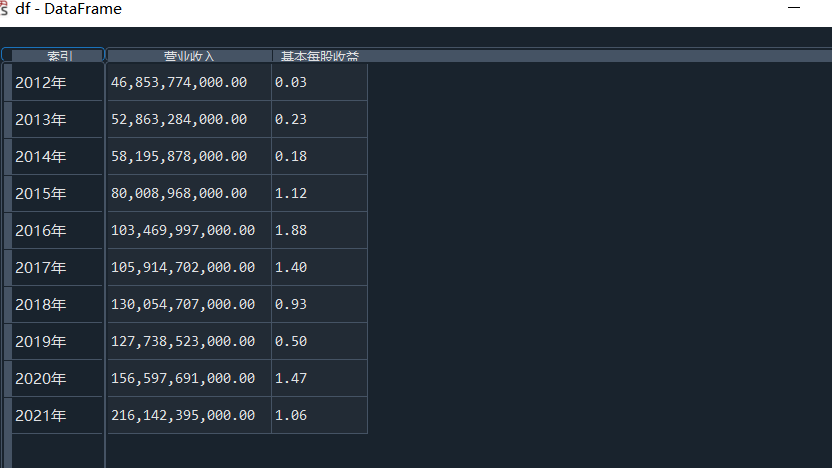

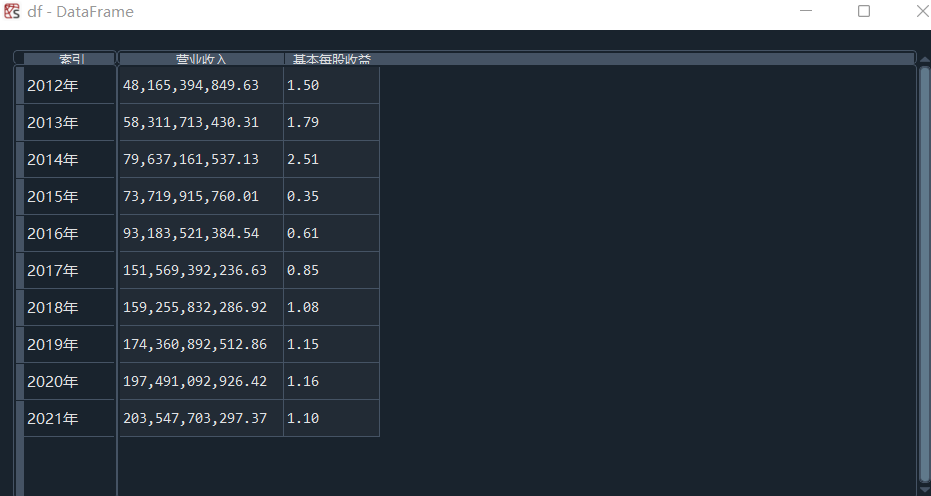
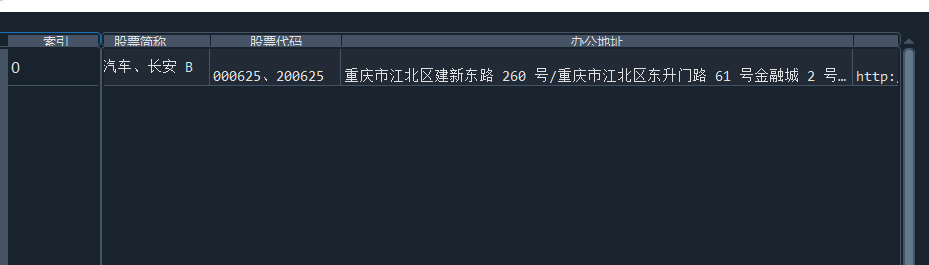
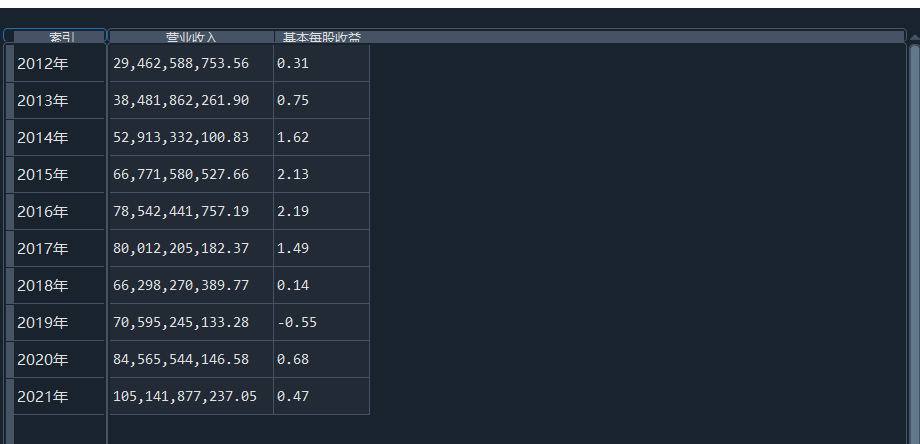

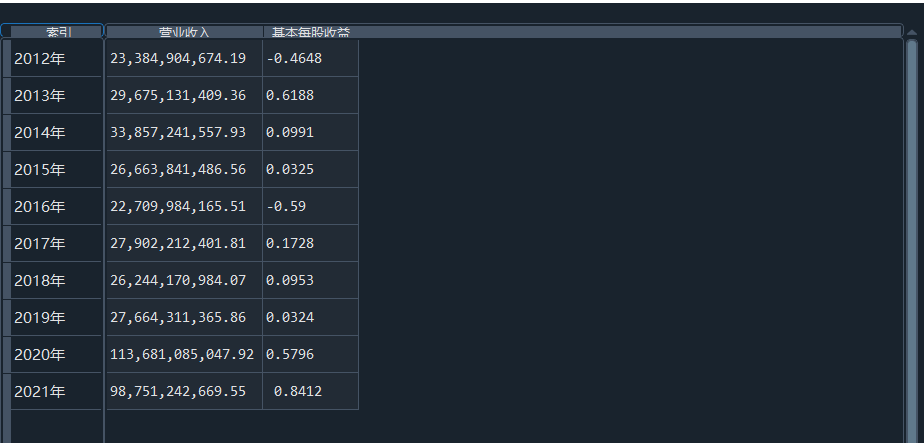

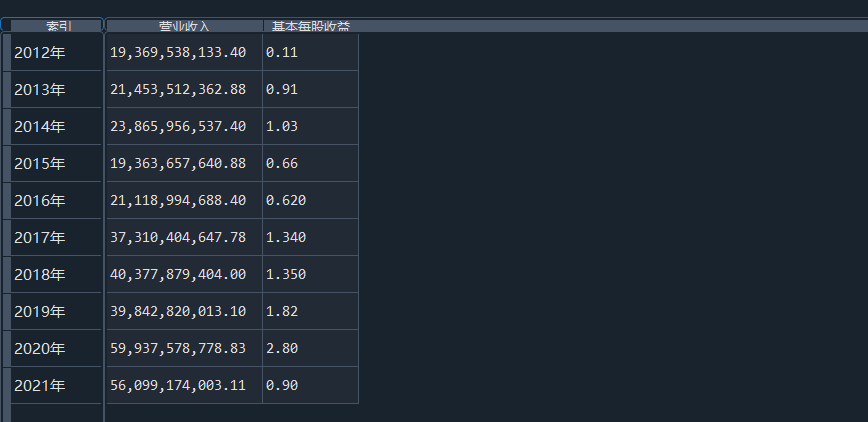

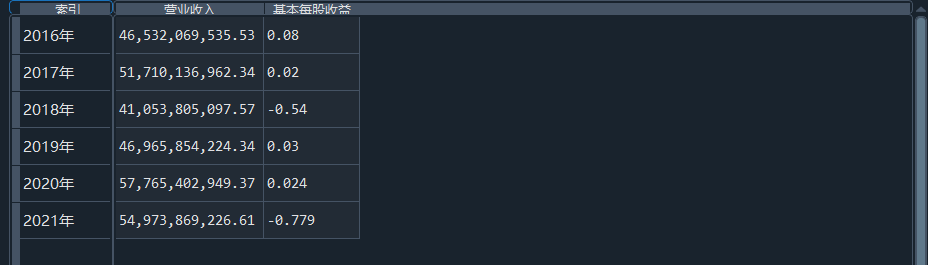

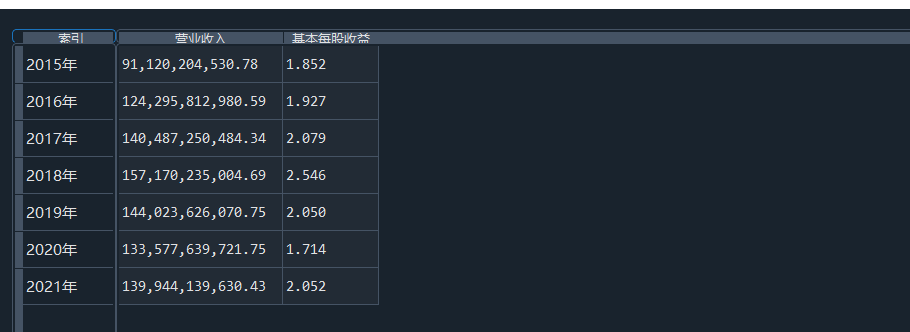

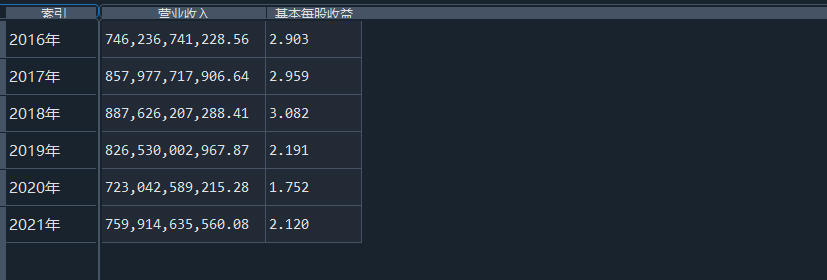

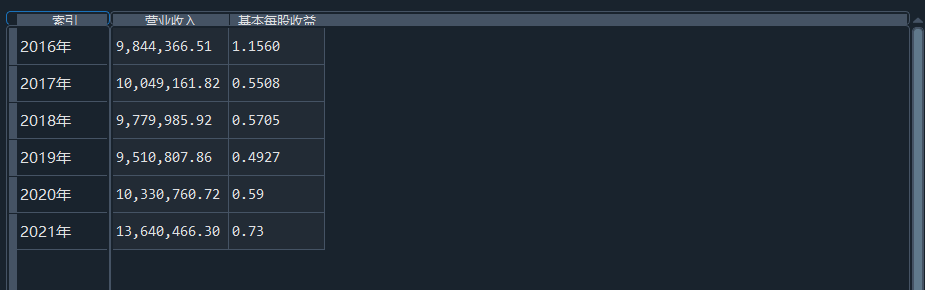

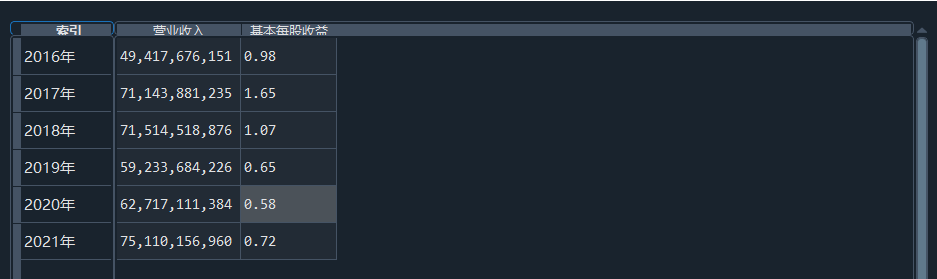
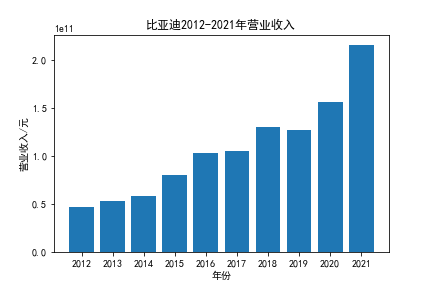
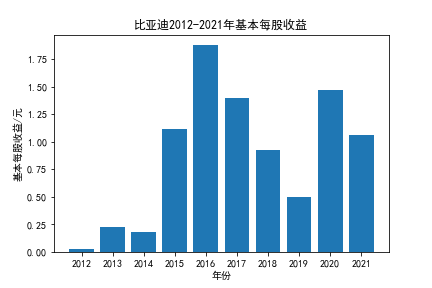
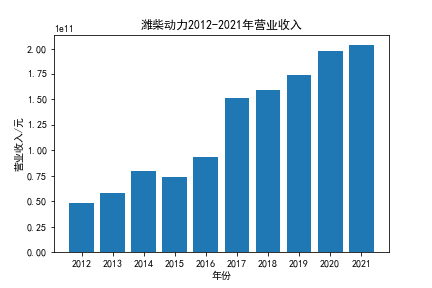
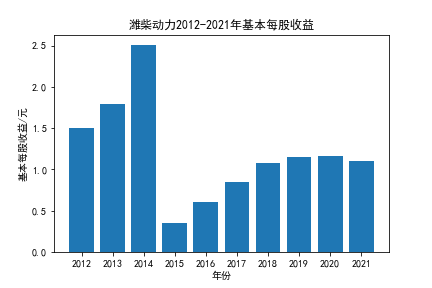
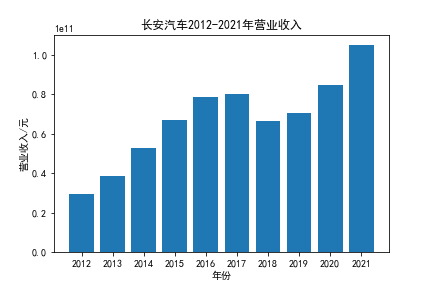
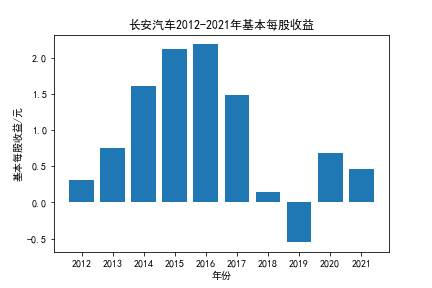
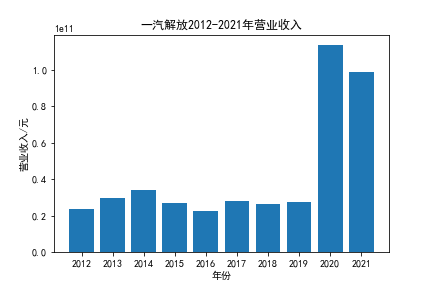
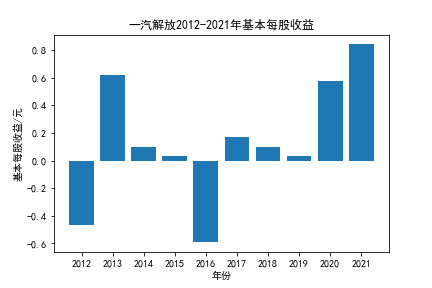
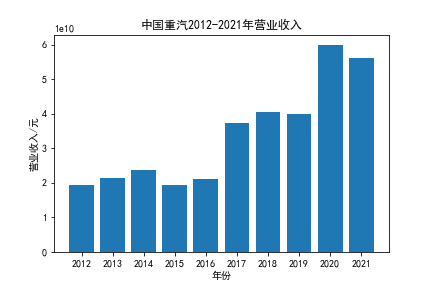
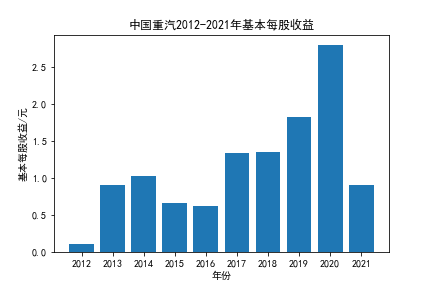
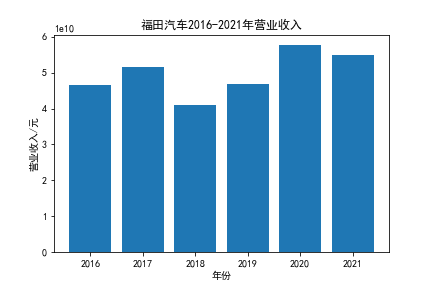
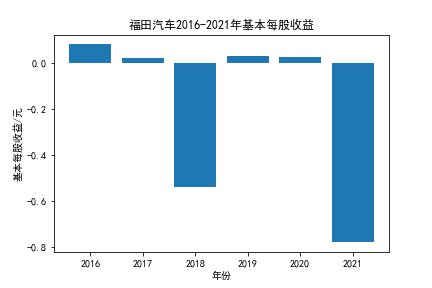
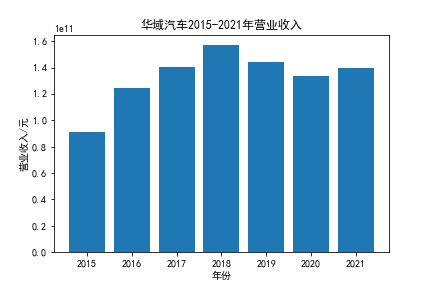
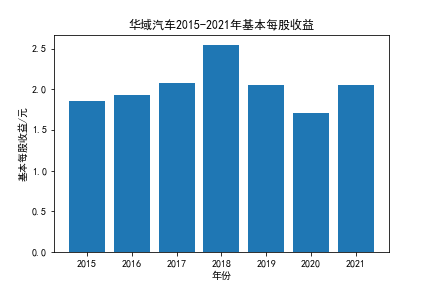
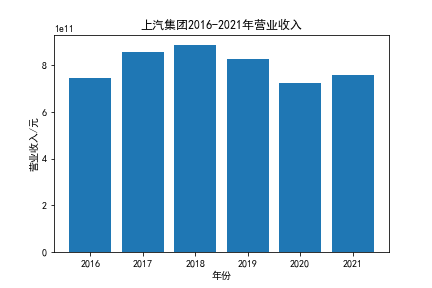
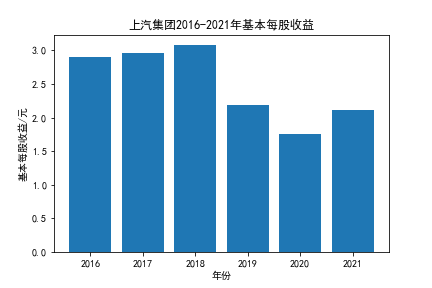
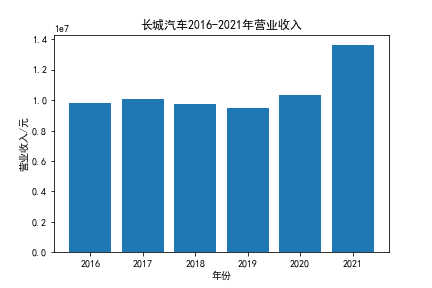
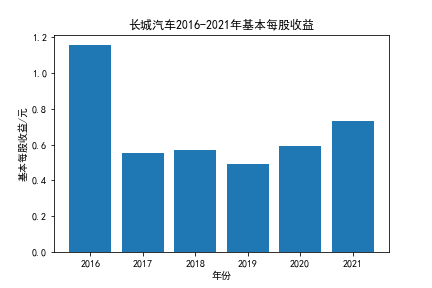
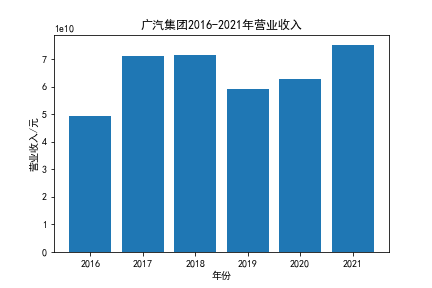
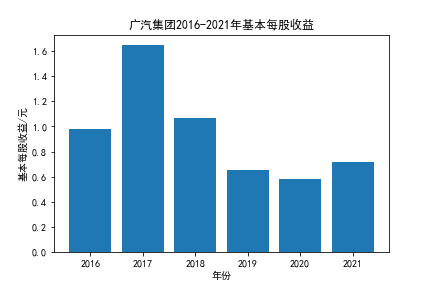

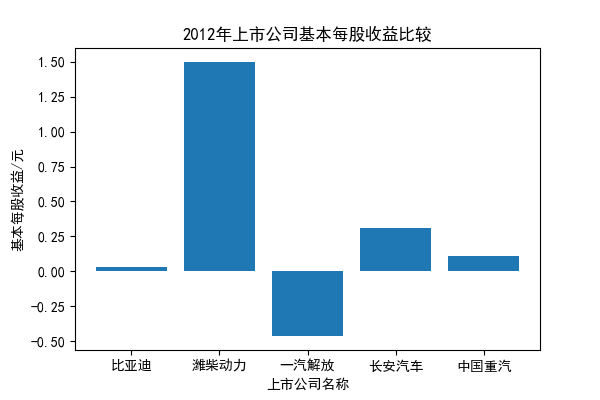
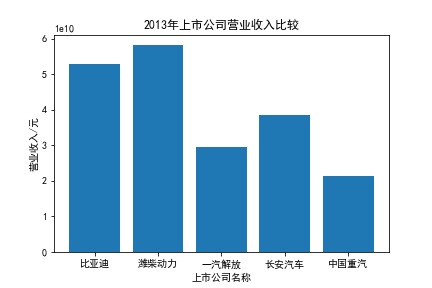
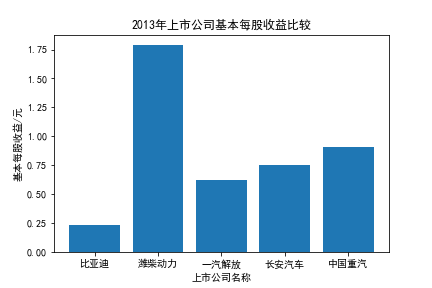
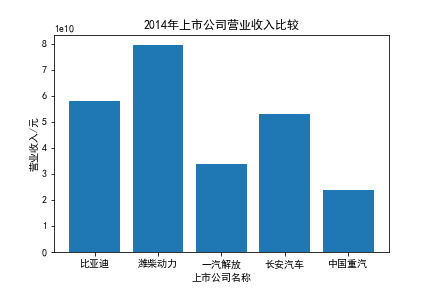
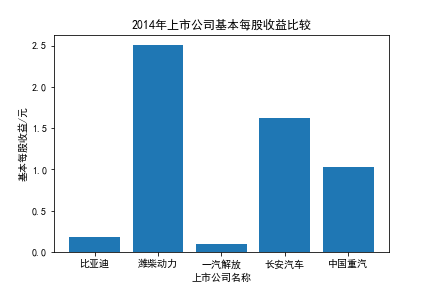

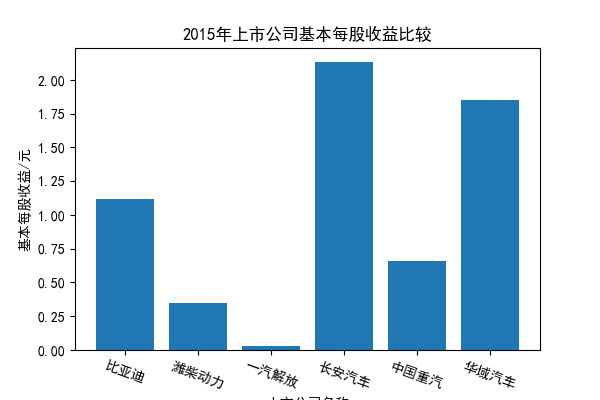
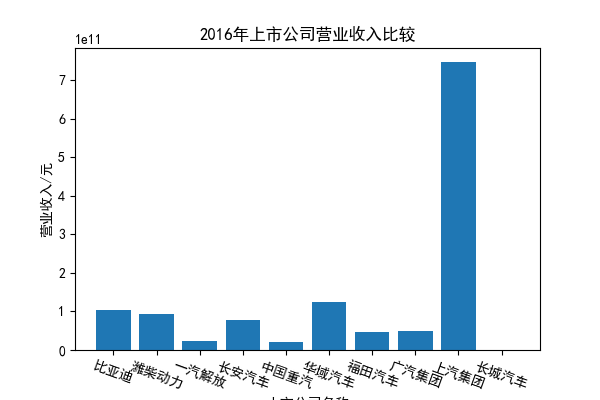
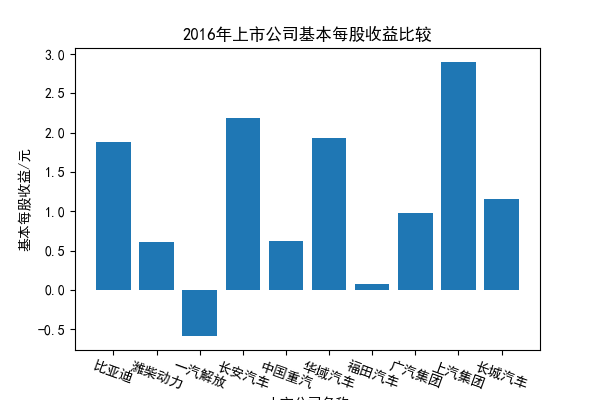
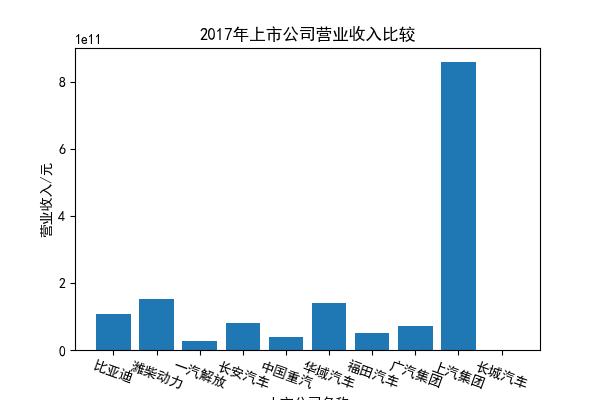
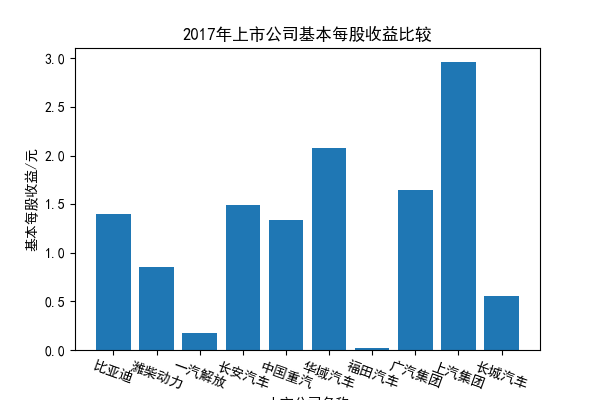
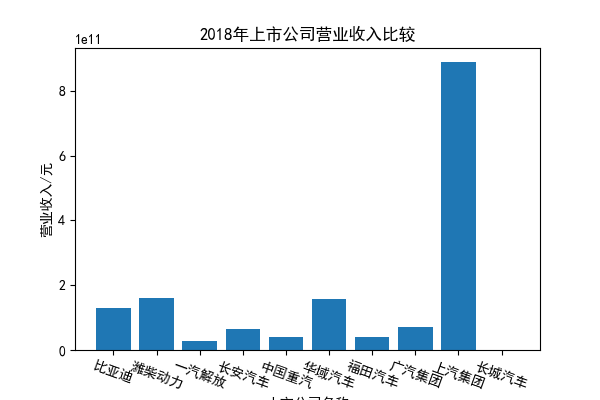
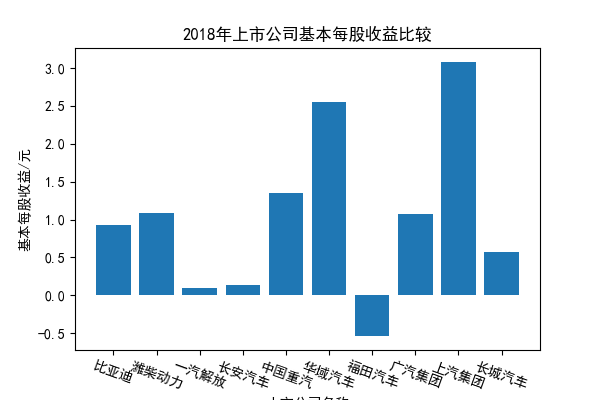
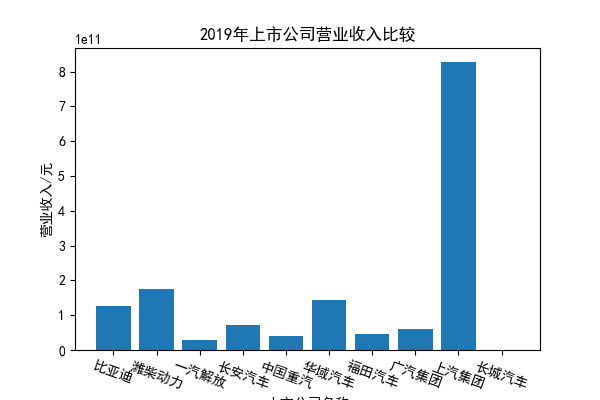
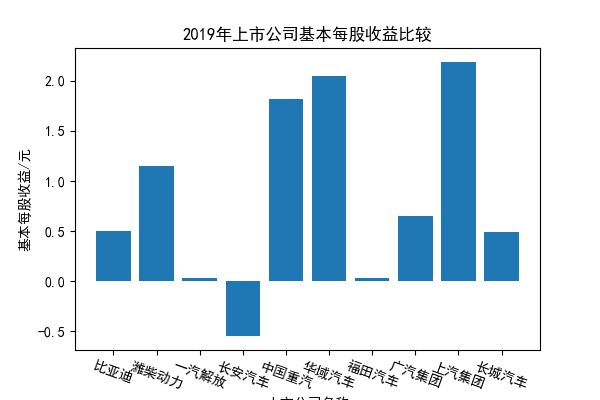
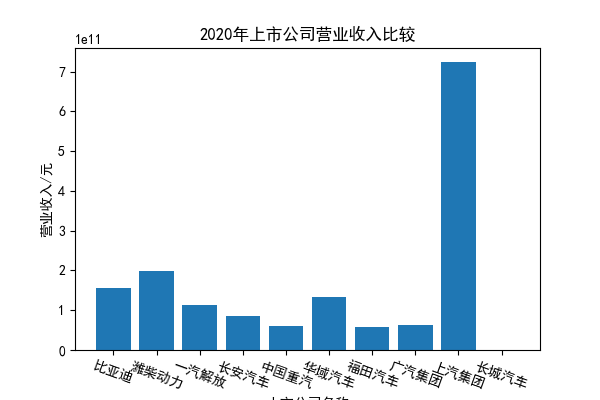
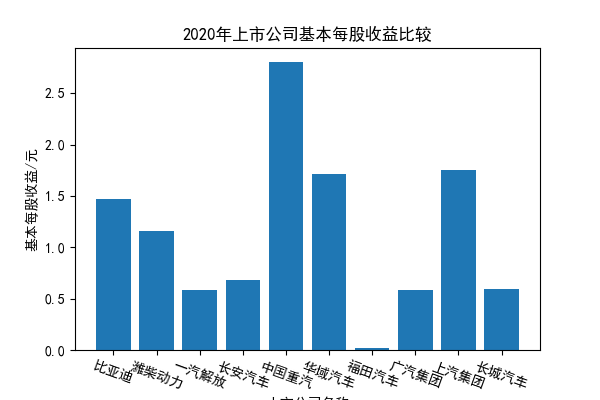
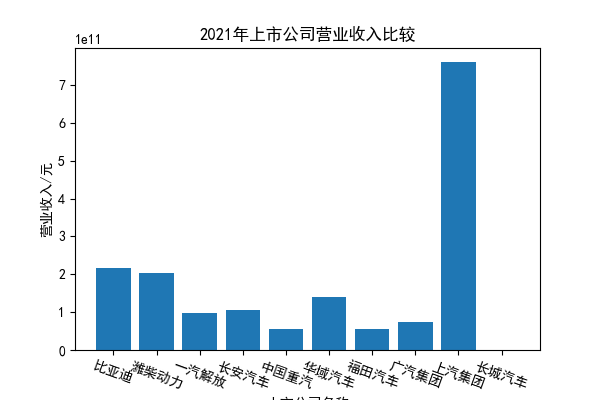
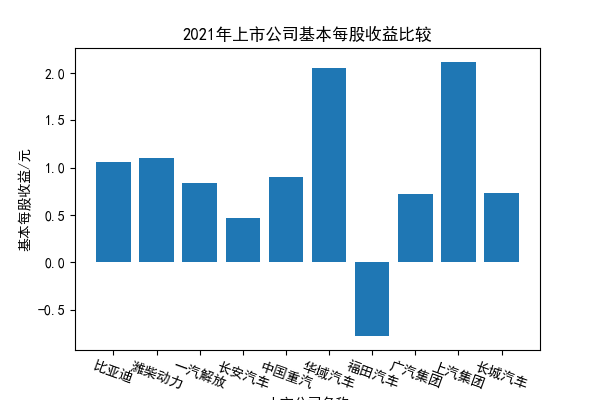
我负责的行业是代码为36的汽车制造业,由于该行业的上市公司数量过多,我就选择了汽车制造业中2021年营业收入 排名前十的十家上市公司进行最后的实验报告编制。它们分别是比亚迪、潍柴动力、长安汽车、一汽解放、中国重汽、福田汽车、 华域汽车、上汽集团、长城汽车与广汽集团。其对应的证券代码分别是002594、000338、000625、000800、000951、 600166、600741、600104、601633、601238。前五家公司在深交所上市,后五家在上交所上市。实验报告内容大致可分为三大部分: 爬取年报、解析年报、总结绘图。爬取年报又分为在深圳证券交易所和上海证券交易所爬取。详细代码内容见前文,特别注意的是上 海证券交易所一次性只能查询3年的年报,故如果要下载近10年的年报,需要分多次进行。而本人所选择的在上交所的公司大部分恰好 只有2016年-2021年的年度报表,故我所写的代码只是从2016年开始的。由于本人在爬取年报时是手动输入上市公司名称或证券代码的, 故所上传代码只是以“中国重汽”和“福田汽车”为例的。在爬取年报结果处的截图也只上传了“中国重汽”和“福田汽车”的图片。解析年报详细代 码见前文,需要注意的是每家公司的报表都是有一些差异的,而且同一家公司不同年份的年度报表也会有差异,故这部分需要特别细心。 总结绘图详细代码见前文,这个部分主要需要注意数据的导入,由于不同公司年报开始的年份是不同的,故在制作各年度对比图时,一定 要关注数据是否配准确。同时要注意中文字体与负号在绘图的正确显示问题。此外,在营业收入的绘图结果处需要说明的是1e11表示1*10的 11次方,1e10表示1*10的10次方,1e8、1e7等同理。由于不同公司的营业收入的数量级有差异,故在绘制对比图时,数量级较小的上市公司 在图像上不好表现甚至出现没有图像的结果,如长城汽车,这是正常的。