import pandas as pd
import pdfplumber
import os
#设置一个Dataframe数据库,用于储存行业分类结果中的数据
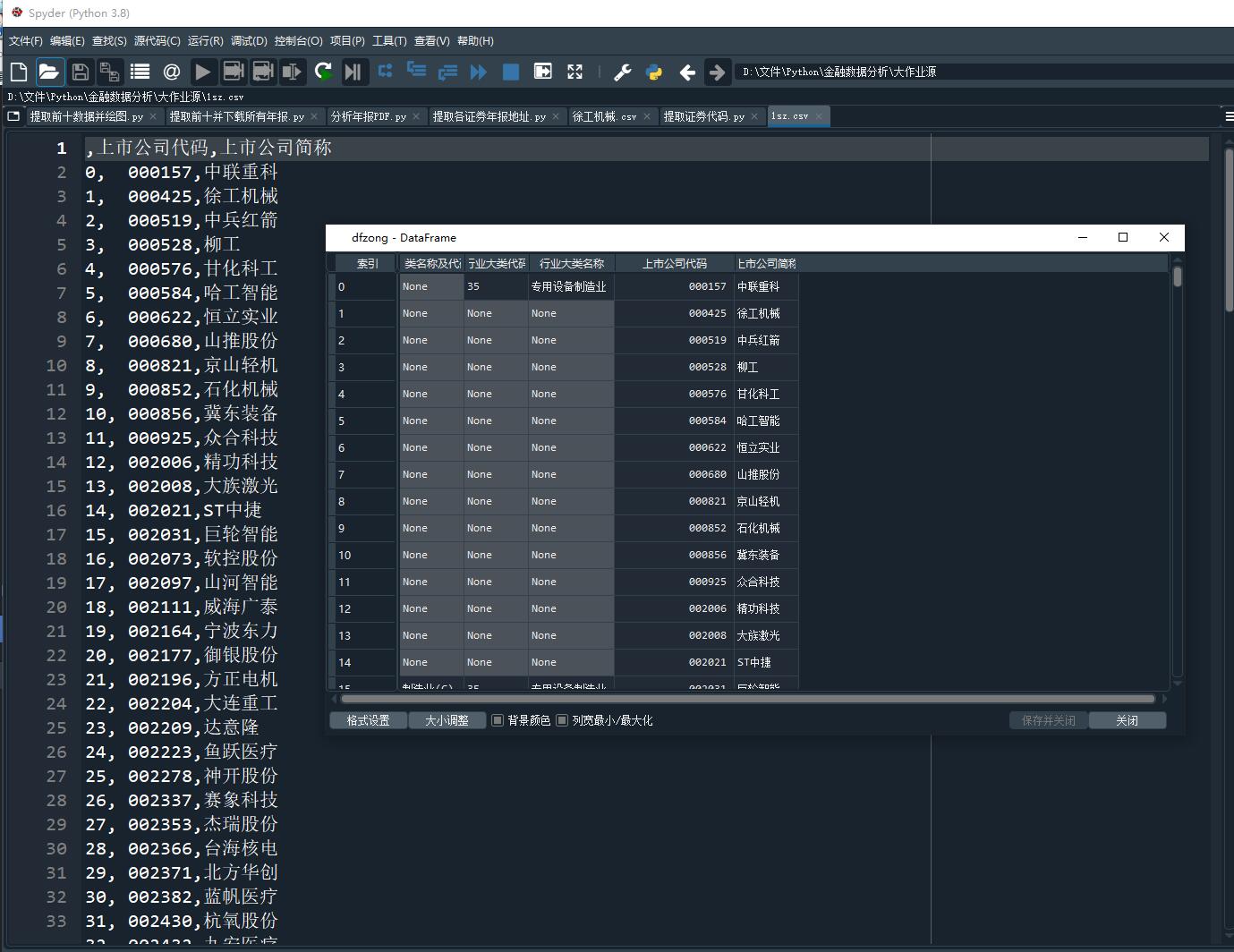
dfzong = pd.DataFrame(columns=('门类名称及代码','行业大类代码','行业大类名称','上市公司代码','上市公司简称'))
with pdfplumber.open('行业分类.pdf') as pdf:
for i in range(39,47):
page = pdf.pages[i] #获取第39到47页自己所分配到的行业35:制造业中的数据
table = page.extract_tables() #循环提取页面中的表格的表格
for t in table:
dfz = pd.DataFrame(t[1:],columns=t[0])
dfzong = dfzong.append(dfz)
dfzong.reset_index(drop=True,inplace=True) #重新设立索引,便于后面调用
#print(df2)
for i in range(0,27): #删除非所分配行业的公司
dfzong = dfzong.drop(index=i)
for i in range(326,336):
dfzong = dfzong.drop(i)
dfzong.reset_index(drop=True,inplace=True)
gongsi = dfzong.iloc[:,3:]
sz = gongsi.iloc[0:160] #将在深交所和上交所上市的公司分隔开
sh = gongsi.iloc[160:]
for i in range(len(sz['上市公司代码'])):
sz.loc[i,'上市公司代码'] = '\t' + sz.loc[i,'上市公司代码']
for i in range(len(sz['上市公司简称'])):
for t in sz['上市公司简称'][i]:
if t == '*' :
sz.loc[i,'上市公司简称'] = sz.loc[i,'上市公司简称'].replace( t ,'')
sz=sz.astype(str)
sz=sz.astype(str)
sz.to_csv('1sz.csv',encoding='utf-8-sig')
sh.to_csv('1sh.csv',encoding='utf-8-sig') #将代码和简称写入本地csv文件,便于调用
import re
import os
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from bs4 import BeautifulSoup
import pdfplumber
import requests
starttime = time.time()
#找到时间输入窗口并输入时间
def InputTime(start,end):
START = browser.find_element(By.CLASS_NAME,'input-left')
END = browser.find_element(By.CLASS_NAME,'input-right')
START.send_keys(start)
END.send_keys(end + Keys.RETURN)
#挑选报告的类别 #为优化爬取效率,此处参考了同学的利用函数定义的方法
def SelectReport(kind):
browser.find_element(By.LINK_TEXT,'请选择公告类别').click()
if kind == 1:
browser.find_element(By.LINK_TEXT,'一季度报告').click()
elif kind == 2:
browser.find_element(By.LINK_TEXT,'半年报告').click()
elif kind == 3:
browser.find_element(By.LINK_TEXT,'三季度报告').click()
elif kind == 4:
browser.find_element(By.LINK_TEXT,'年度报告').click()
#提前预设好部分筛选条件,之前的作业三中这一部分被我写入了for循环,
#导致每次爬取都要重新打开浏览器,爬取速度很慢,此处进行了优化。
browser = webdriver.Chrome()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
time.sleep(1)
End = time.strftime('%Y-%m-%d', time.localtime())
InputTime('2013-01-01',End)
SelectReport(4) # 调用函数,选择“年度报告”
ActionChains(browser).move_by_offset(200, 100).click().perform()
#爬取并下载年报源代码
for i in sz['上市公司简称']:
#chrome_options=Options()
#chrome_options.add_argument('--headless')
#browser = webdriver.Chrome(options=chrome_options)
element = browser.find_element(By.ID, 'input_code') # ID定位到搜索框
element.send_keys( i + Keys.RETURN) # 输入想要查找的企业
time.sleep(2)
element = browser.find_element(By.ID, 'disclosure-table') # ID定位到年报表格
innerHTML = element.get_attribute('innerHTML') # 获取年报标签下的源代码
f = open(i+'.html','w',encoding='utf-8') # 将源代码写入本地文件
f.write(innerHTML)
f.close()
browser.find_elements(By.CLASS_NAME,'icon-remove')[-1].click()
time.sleep(2)
n=0
#解析源代码,提取部分信息,并下载年报
for i in sz['上市公司简称']:
f = open(i+'.html',encoding='utf-8') # 读取年报源代码文件
html = f.read()
f.close()
soup = BeautifulSoup(html,features='lxml') #利用bs进行解析
html_prettified = soup.prettify() #格式标准化代码
p = re.compile('(.*?) ', re.DOTALL) #利用正则表达式 找到所需链接的tr标签
trs = p.findall(html_prettified)
#把每一次爬取到的tr标签添加到trs这个空列表中
p2 = re.compile('(.*?)', re.DOTALL) #在tr标签下进一步提取td标签下的内容
tds = [p2.findall(tr) for tr in trs[1:]] #循环搜索提取trs里的所有项目
#注:此处因为前面翻页时,tds列表存在空列表,下面td[0]会报错,要把空列表过滤。
#因为筛选条件增加,已不需要翻页功能。
#tds = list(filter(None,tds))
p_code = re.compile('(.*?)', re.DOTALL) #在td标签下爬取企业代码,注:tds里的每一个项目都是一个列表
codes = [p_code.search(td[0]).group(1).strip() for td in tds]
p_shortname = p_code #在td标签下爬取企业名字
short_names = [p_shortname.search(td[1]).group(1).strip() for td in tds]
p_link_ftitle = re.compile('(.*?) ',
re.DOTALL)
link_ftitles = [p_link_ftitle.findall(td[2])[0] for td in tds] #在td标签下精确提取所需链接
p_pub_time = re.compile('(.*?)', re.DOTALL) #在td标签下爬取年报时间
p_times = [p_pub_time.search(td[3]).group(1) for td in tds]
prefix = 'https://disc.szse.cn/download' #为后面提取的链接设定好下载前缀网址
prefix_href = 'http://www.szse.cn' #为后面提取的链接设定好查看前缀网址
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [lf[2].strip() for lf in link_ftitles],
'attachpath': [prefix+lf[0].strip() for lf in link_ftitles],
'href': [prefix_href+lf[1].strip() for lf in link_ftitles],
'公告时间': [t.strip() for t in p_times]
}) #将数据导入至dataframe
btlist = []
#过滤不需要的年报
for index, row in df.iterrows():
bt = row[2]
a = re.search('摘要|取消|英文', bt)
if a!= None:
btlist.append(index)
df1 = df.drop(btlist)
df1.reset_index(drop=True,inplace=True)
time.sleep(2)
endtime = time.time()
df1.to_csv(i+'.csv',encoding='utf-8-sig') #将数据写入本地文件,并使用utf-8-sig编码,
#便于直接打开浏览,不出现乱码。
os.makedirs(i,exist_ok=True)
os.chdir(i)
f = requests.get(df1.iat[0,3])
with open (df1.iat[0,2]+".pdf", "wb") as code:
code.write(f.content)
n+=1
print('正在下载第',n,'份',i,'共',len(sz['上市公司简称']),'份')
os.chdir('../')
print('爬取完毕','共耗时',endtime - starttime)
import os
import re
import pandas as pd
import fitz
import pdfplumber
Company = pd.read_csv('1sz.csv',header=None, dtype={0:'str'}).iloc[:,1:] #将数据指定为字符串,否则会丢失证券代码前面的0
company=Company.iloc[1:,1].tolist() #创建一个公司名称的列表,便于访问
n=0
for com in company:
n+=1
com = com.replace('*','')
df = pd.read_csv(com+'.csv',converters={'证券代码':str}) #读取csv文件循环访问pdf年报
#df = df.drop(df.index[0])
df = df.drop(df.columns[0], axis=1)
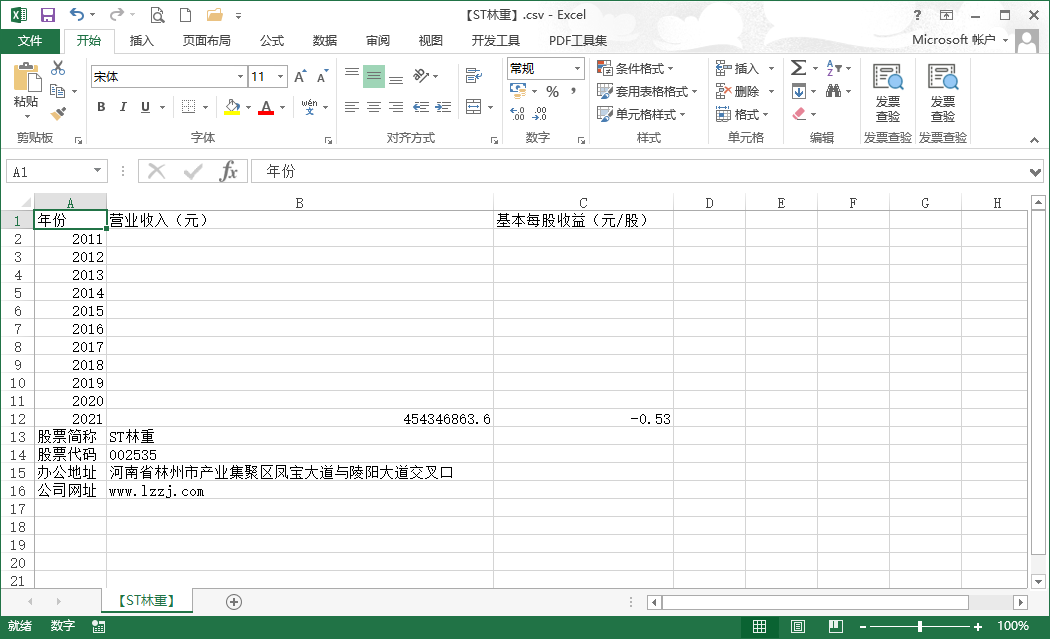
income = pd.DataFrame(index=range(2011,2022),columns=['营业收入(元)','基本每股收益(元/股)']) #创建一个空的dataframe用于后面保存数据
income.index.name='年份'
code = '\t'+str(df.iloc[0,0])
name = df.iloc[0,1].replace(' ','')
title = df.iloc[0,2]
doc = fitz.open('./%s/%s.pdf'%(com,title)) #本来想用type 作为标题类型的参数的,发现type好像是关键字
text=''
for i in range(25):
page = doc[i]
text += page.get_text()
p_year=re.compile('.*?(\d{4}).*?年度报告.*?') #捕获目前在匹配的年报年份
year = int(p_year.findall(text)[0])
#设置需要匹配的四种数据的pattern
p_shouru = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
p_shouyi = re.compile('(?<=\n)基本每股收益(元/?/?\n?股)\s?\n?([-\d+,.]*)\s?\n?')
p_dizhi = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
p_wangzhi =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./:]*)\s?(?=\n)',re.DOTALL)
shouru=float(p_shouru.search(text).group(1).replace(',',''))
shouyi=p_shouyi.search(text).group(1)
income.loc[year,'营业收入(元)']=shouru #把营业收入和每股收益写进最开始创建的dataframe
income.loc[year,'基本每股收益(元/股)']=shouyi
os.chdir(com)
income.to_csv('【%s】.csv' %com,encoding='utf-8-sig') #将各公司数据存储到本地测csv文件
dizhi=p_dizhi.search(text).group(1) #匹配办公地址和网址(由于取最近一年的,所以只要匹配一次不用循环匹配)
wangzhi=p_wangzhi.search(text).group(1)
with open('【%s】.csv'%com,'a',encoding='utf-8-sig') as f: #把股票简称,代码,办公地址和网址写入文件末尾
content='股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name,code,dizhi,wangzhi)
f.write(content)
os.chdir('../')
print(name+'数据已保存完毕'+'(',n,'/',len(company),')')
import os
import re
import pandas as pd
import fitz
import pdfplumber
import matplotlib.pyplot as plt
import requests
os.chdir('../')
Company = pd.read_csv('1sz.csv',header=None, dtype={0:'str'}).iloc[:,1:] #将数据指定为字符串,否则会丢失代码前面的0
company=Company.iloc[1:,1].tolist() #创建一个公司名称的列表,便于访问
dflist=[]
for name in company:
com = name.replace('*','')
os.chdir(com)
data=pd.read_csv('【'+com+'】.csv')
dflist.append(data)
os.chdir('../')
com_number = len(dflist)
for i in range(com_number):
dflist[i]=dflist[i].set_index('年份')
df=pd.DataFrame(columns=('上市公司代码','股票简称','最近一年营业收入(元)'))
for i in range(com_number):
df.loc[i,'上市公司代码']=dflist[i].iloc[12,0]
df.loc[i,'股票简称']=dflist[i].iloc[11,0]
df.loc[i,'最近一年营业收入(元)']=dflist[i].iloc[10,0]
rank=df.sort_values('最近一年营业收入(元)',ascending=False).head(10) #取最近一年营业收入前十的公司
names=list(rank['股票简称'])
codes=list(rank['上市公司代码'])
indexes=[]
for i in rank['上市公司代码']:
indexes.append(i)
rank.to_csv('rank.csv',encoding='utf-8-sig')
os.makedirs('收入前十',exist_ok=True) #收入前十进行排行后,新创建一个文件夹,便于后续年报存取和调用
n=0
#重新调用csv数据,并下载收入前十公司的所有年报
for name in names:
indexes.append(company.index(name))
dfx = pd.read_csv(name+'.csv').iloc[:,1:]
os.chdir('收入前十')
os.makedirs(name,exist_ok=True)
os.chdir(name)
d1={}
for index , row in dfx.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
with open (key+".pdf", "wb") as code:
code.write(f.content)
n+=1
print('正在下载第',n,'份',name,'共',len(dfx),'份')
os.chdir('../../')
os.chdir('收入前十')
n=0
for name in names:
n+=1
name = name.replace('*','')
df = pd.read_csv(name+'.csv',converters={'证券代码':str}) #读取csv文件循环访问pdf年报
#df = df.drop(df.index[0])
df = df.drop(df.columns[0], axis=1)
income = pd.DataFrame(index=range(2011,2022),columns=['营业收入(元)','基本每股收益(元/股)']) #创建一个空的dataframe用于后面保存数据
income.index.name='年份'
code = '\t'+str(df.iloc[0,0])
name10 = df.iloc[0,1].replace(' ','')
os.chdir('收入前十')
for i in range(len(df)): #循环访问每年的年报
title = df.iloc[i,2]
doc = fitz.open('./%s/%s.pdf'%(name,title)) #本来想用type 作为标题类型的参数的,发现type好像是关键字
text=''
for i in range(30):
page = doc[i]
text += page.get_text()
p_year=re.compile('.*?(\d{4}).*?年度报告.*?') #捕获目前在匹配的年报年份
year = int(p_year.findall(text)[0])
#设置需要匹配的四种数据的pattern
p_shouru = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
p_shouyi = re.compile('(?<=\n)基本每股收益(元/?/?\n?股)\s?\n?([-\d+,.]*)\s?\n?')
p_dizhi = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
p_wangzhi =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./:]*)\s?(?=\n)',re.DOTALL)
shouru=float(p_shouru.search(text).group(1).replace(',','')+'0')
shouyi=p_shouyi.search(text).group(1)
income.loc[year,'营业收入(元)']='\t'+str(shouru) #把营业收入和每股收益写进最开始创建的dataframe
#此处把收入转化为文本格式显示,并在前面加上\t可以防止保存csv时数字格式出错
income.loc[year,'基本每股收益(元/股)']=shouyi
income.to_csv('【%s】.csv' %name,encoding='utf-8-sig') #将各公司数据存储到本地测csv文件
dizhi=p_dizhi.search(text).group(1)
wangzhi=p_wangzhi.search(text).group(1)
with open('【%s】.csv'%com,'a',encoding='utf-8-sig') as f: #把股票简称,代码,办公地址和网址写入文件末尾
content='股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name,code,dizhi,wangzhi)
f.write(content)
os.chdir('../')
print(name10+'数据已保存'+'(',n,'/10)')
import os
import re
import pandas as pd
import fitz
import pdfplumber
import matplotlib.pyplot as plt
import requests
from pylab import *
Company=pd.read_csv('rank.csv',header=None, dtype={0:'str'}).iloc[:,1:3]
company=Company.iloc[1:,1].tolist()
dflist=[]
for name in company:
com = name.replace('*','')
data=pd.read_csv('【'+com+'】.csv')
dflist.append(data) #将所有的csv文件保存到一个list里方便后续调用
com_number = len(dflist)
for i in range(com_number):
dflist[i]=dflist[i].set_index('年份')
'''
x=dflist[1].iloc[5:,0]
Number_new=[]
for i in x:
Number_new.append(i)
'''
datalist1=[]
datalist2=[]
for i in range(len(dflist)): #在dflist里选出所需公司的营业收入数据
datalist1.append(pd.DataFrame(dflist[i].iloc[:,0]))
for df in datalist1:
df.index=df.index.astype(int)
df['营业收入(元)']=df['营业收入(元)'].astype(float)/1000000000
for i in range(len(dflist)): #在dflist里选出所需公司的每股收益数据
datalist2.append(pd.DataFrame(dflist[i].iloc[:,1]))
for df in datalist2:
df.index=df.index.astype(int)
df['基本每股收益(元/股)']=df['基本每股收益(元/股)'].astype(float)
shouru=pd.concat(datalist1,axis=1) #将所有公司的df合并成汇总表
meigushouyi=pd.concat(datalist2,axis=1)
shouru.columns=Company.iloc[1:,1]
meigushouyi.columns=Company.iloc[1:,1]
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
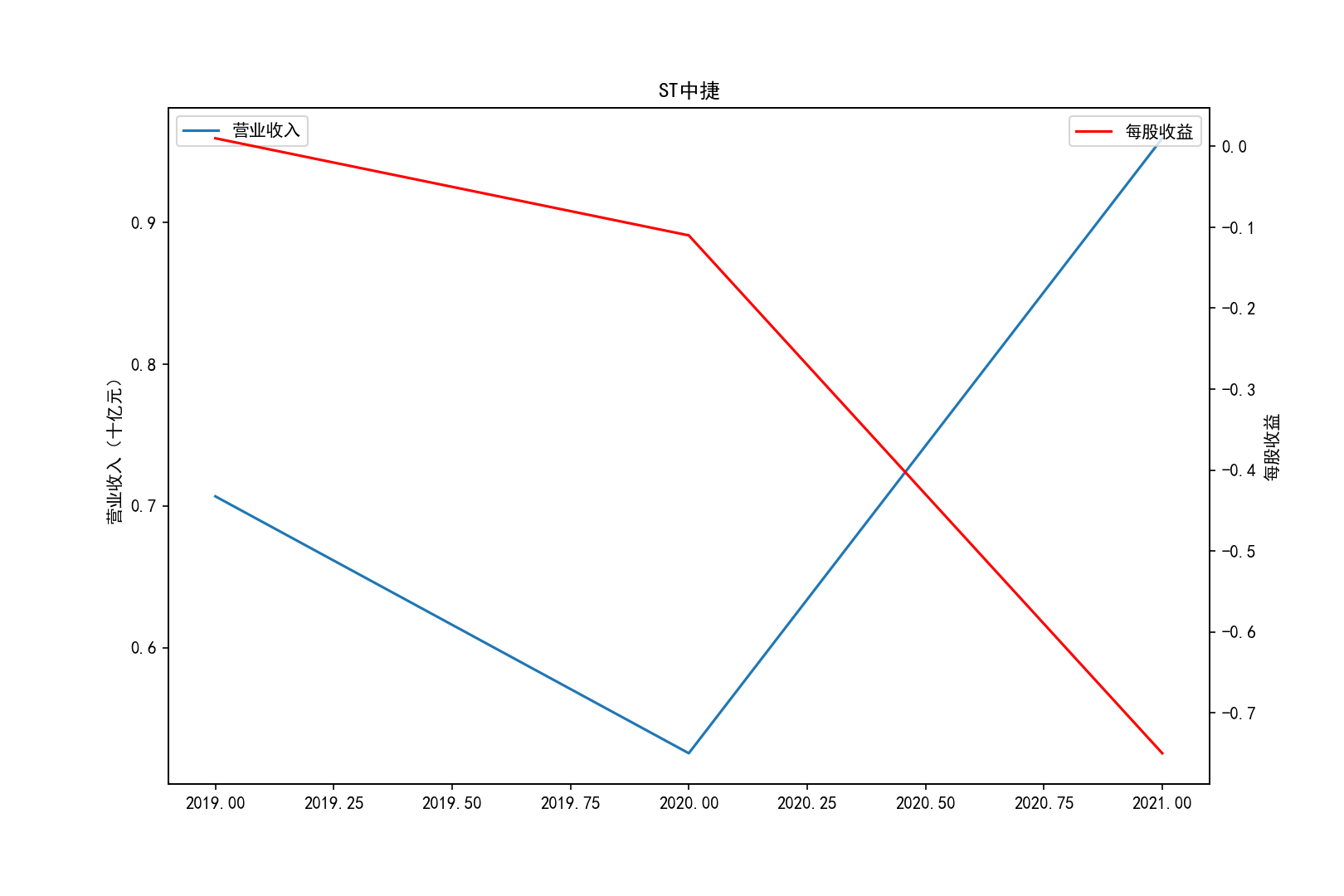
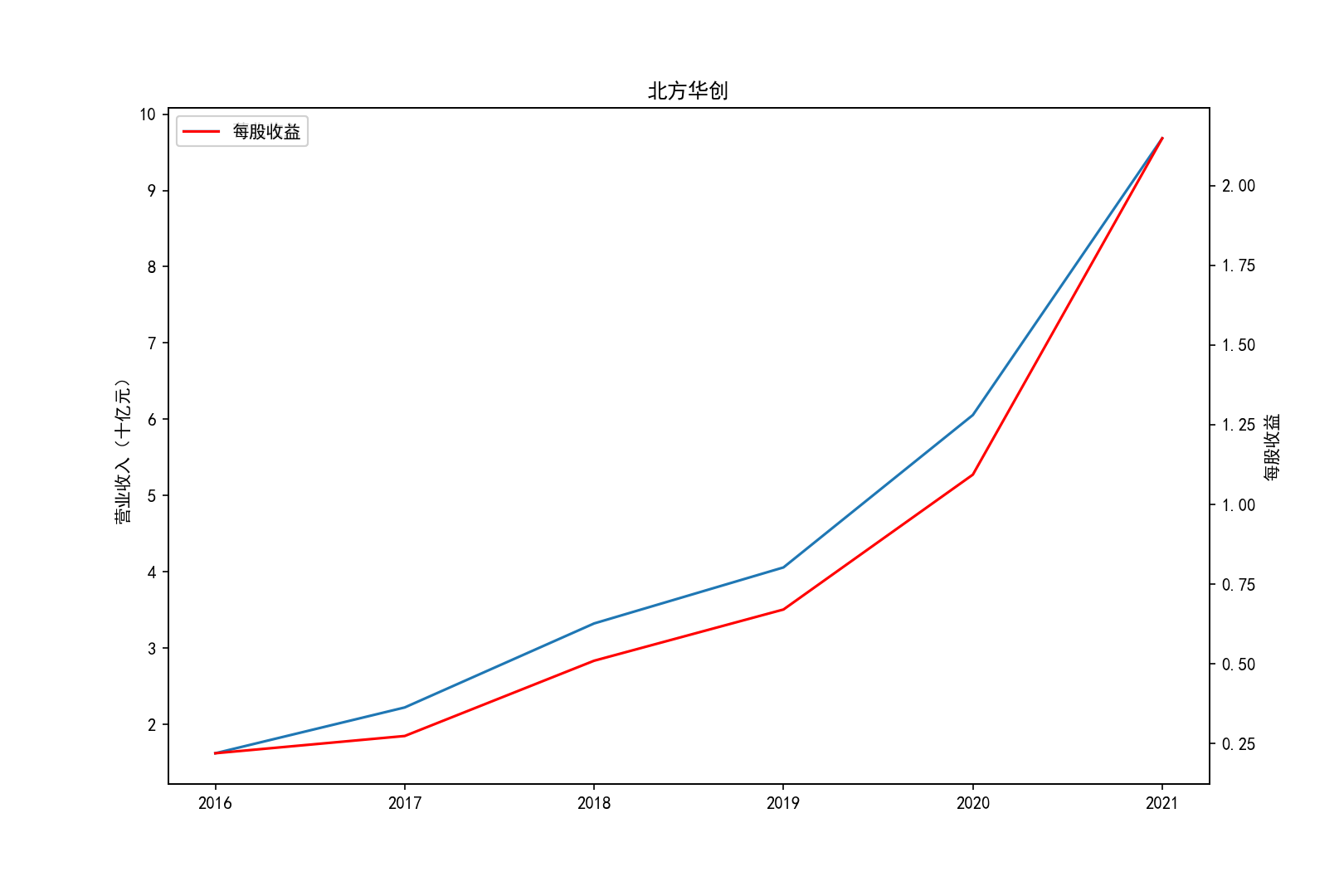
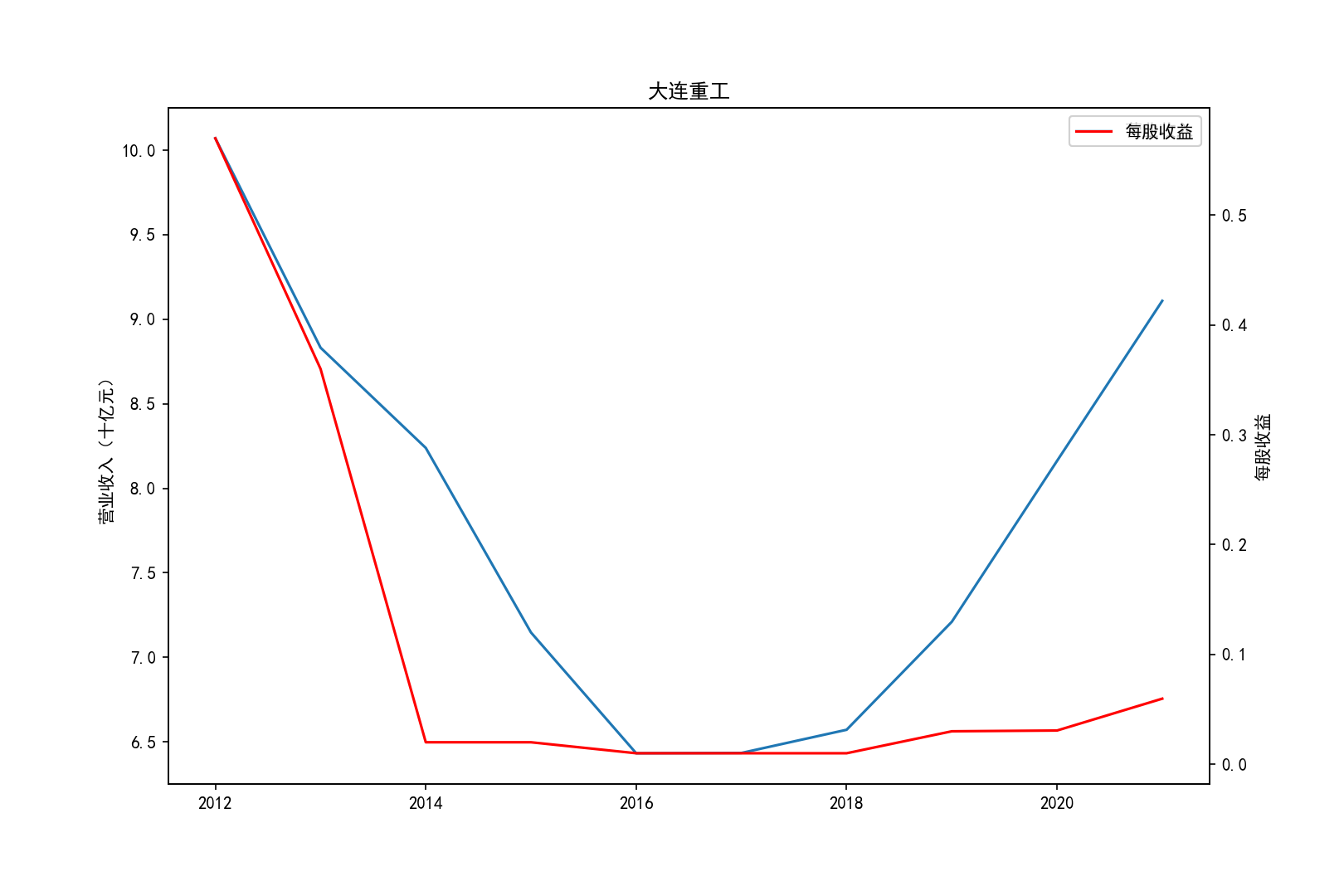
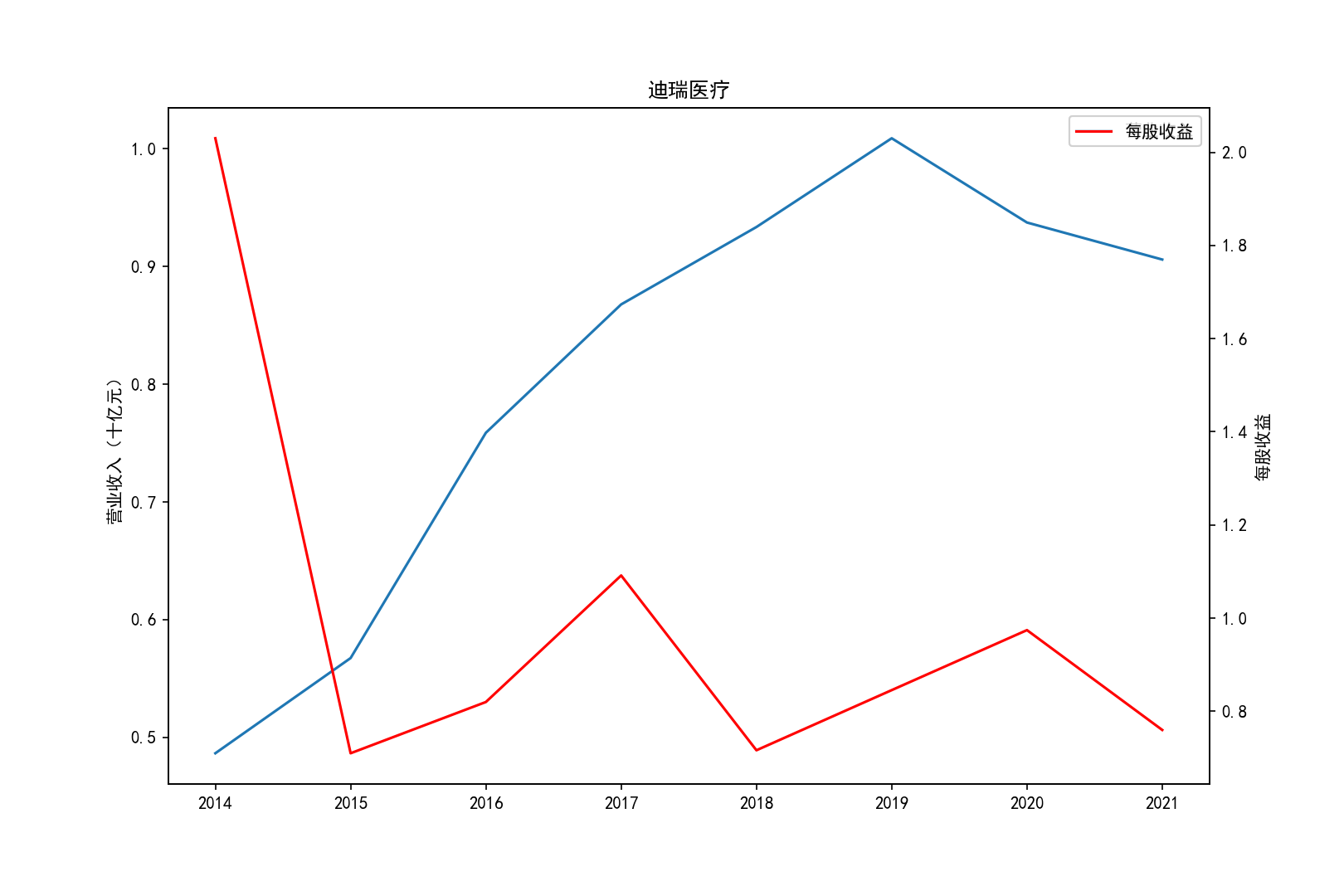
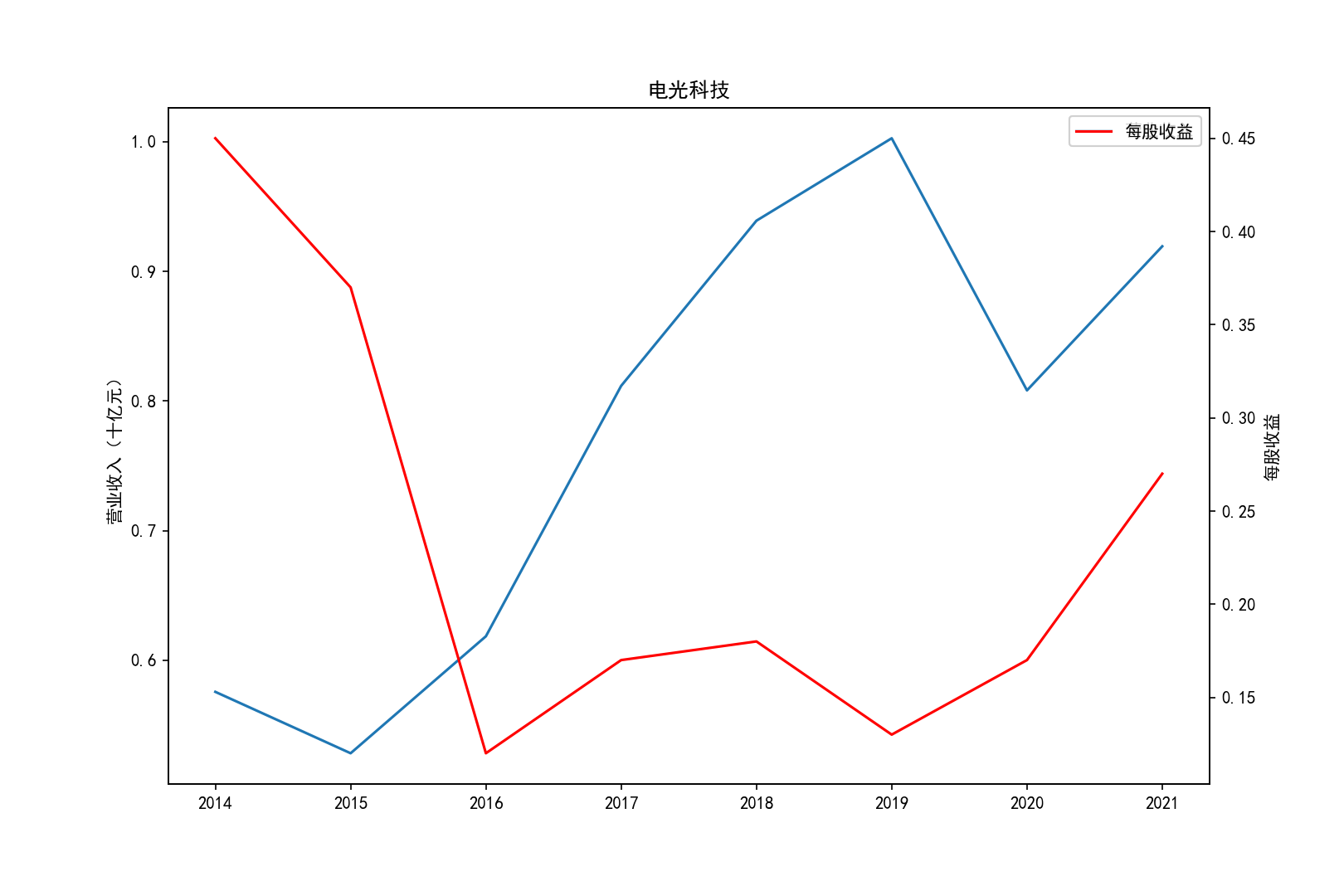
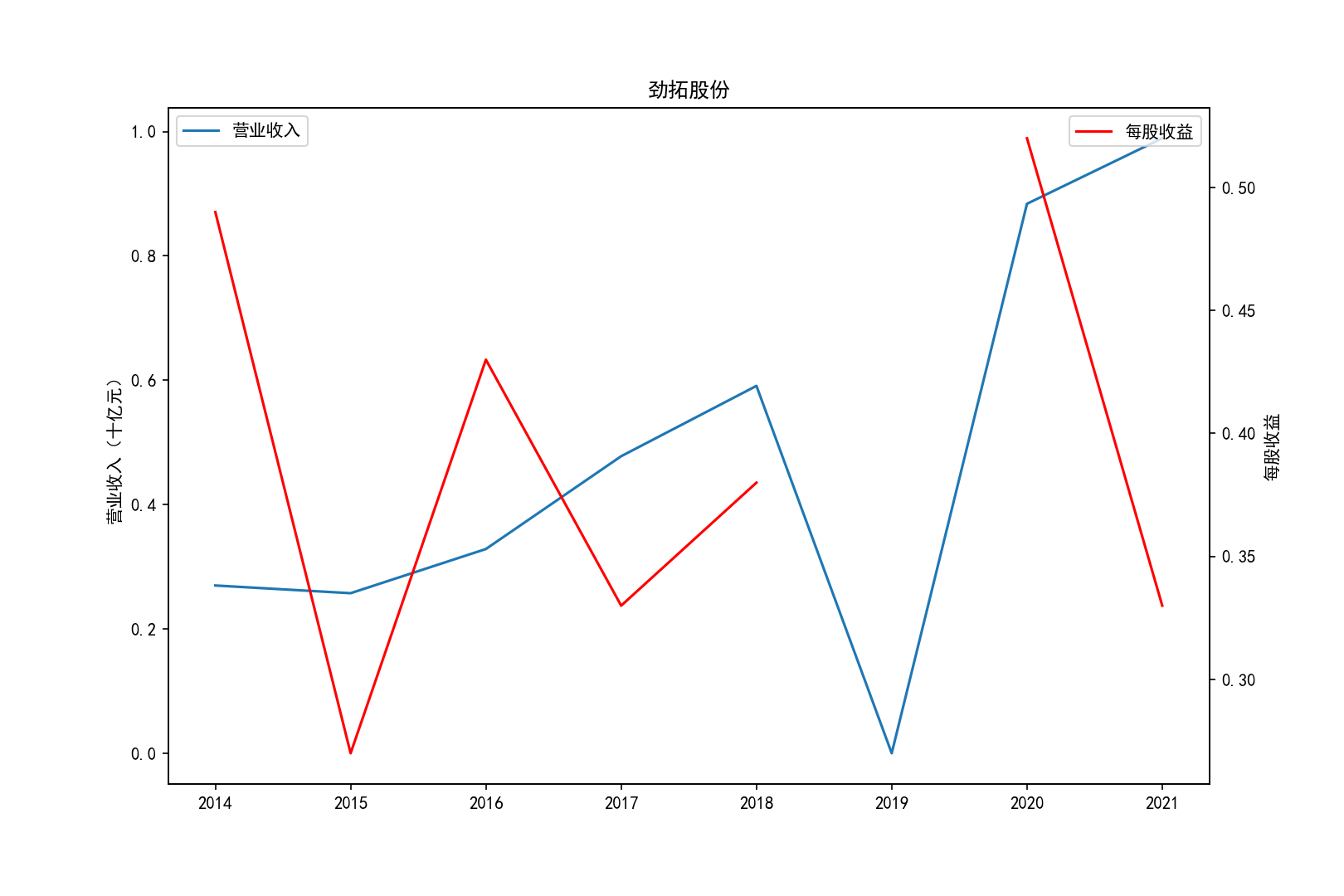
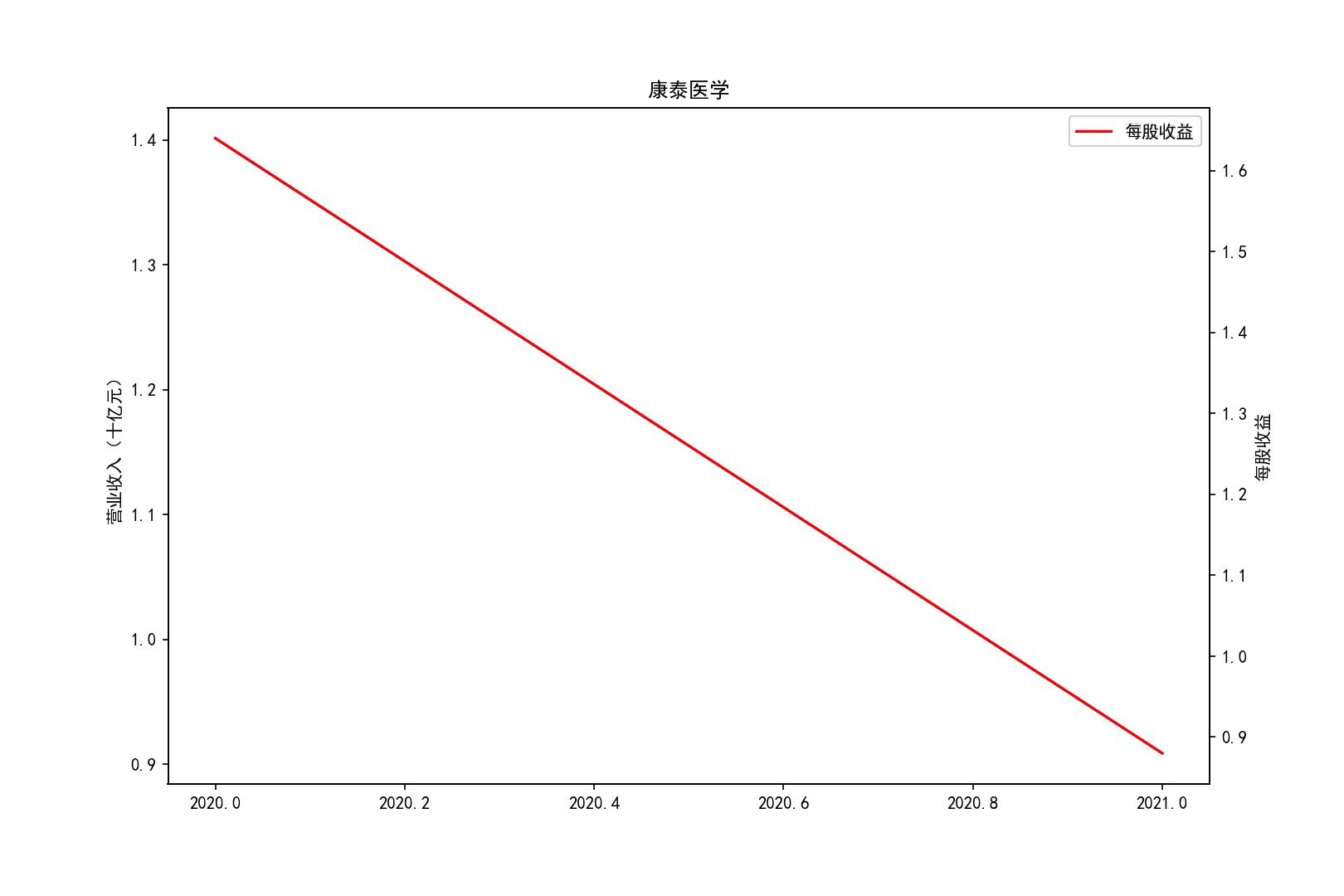
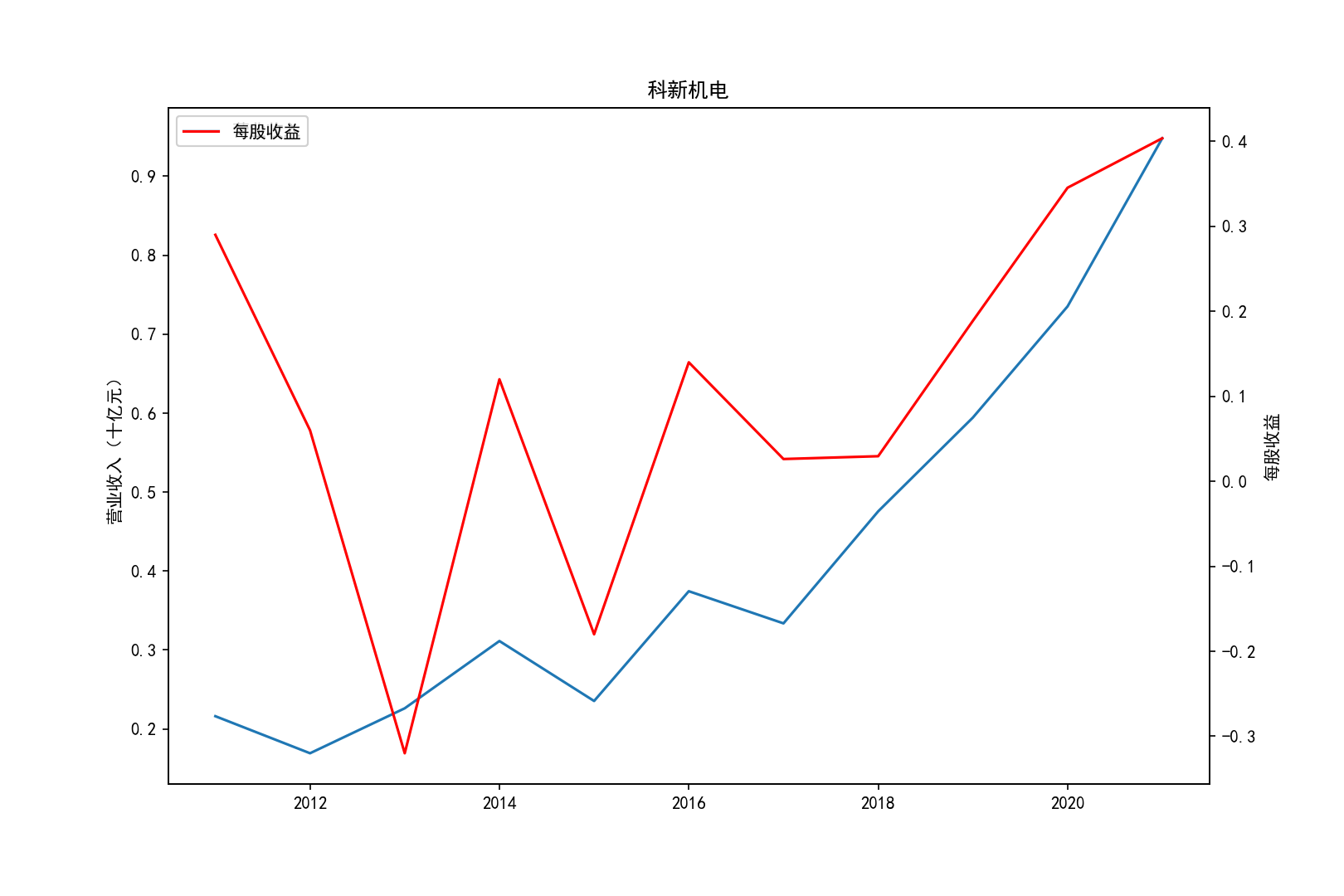
for i in range(10):
title=shouru.columns[i]
x= shouru.index.tolist()
y1=shouru.iloc[:,i]
y1=y1.tolist()
y2=meigushouyi.iloc[:,i]
y2=y2.tolist()
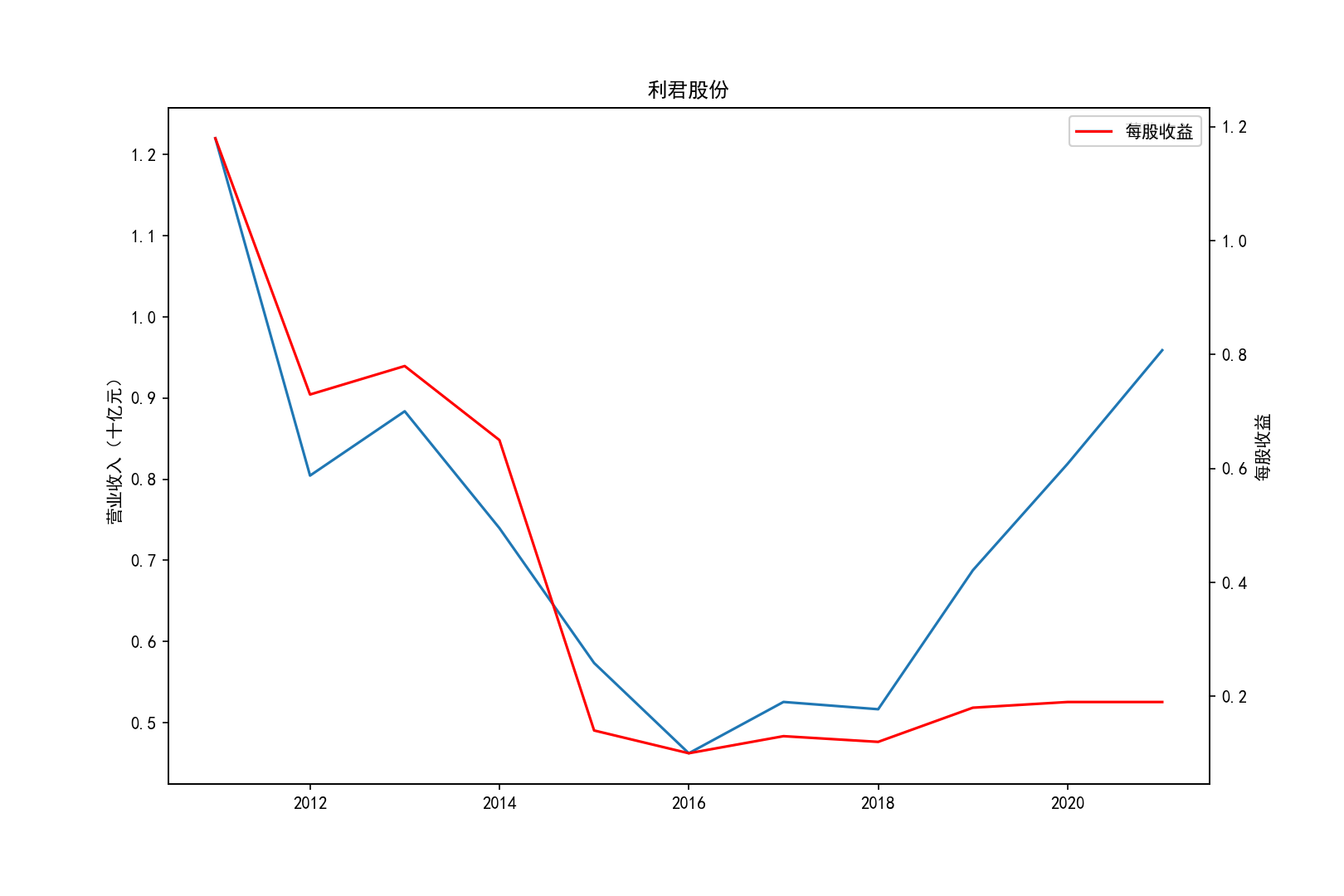
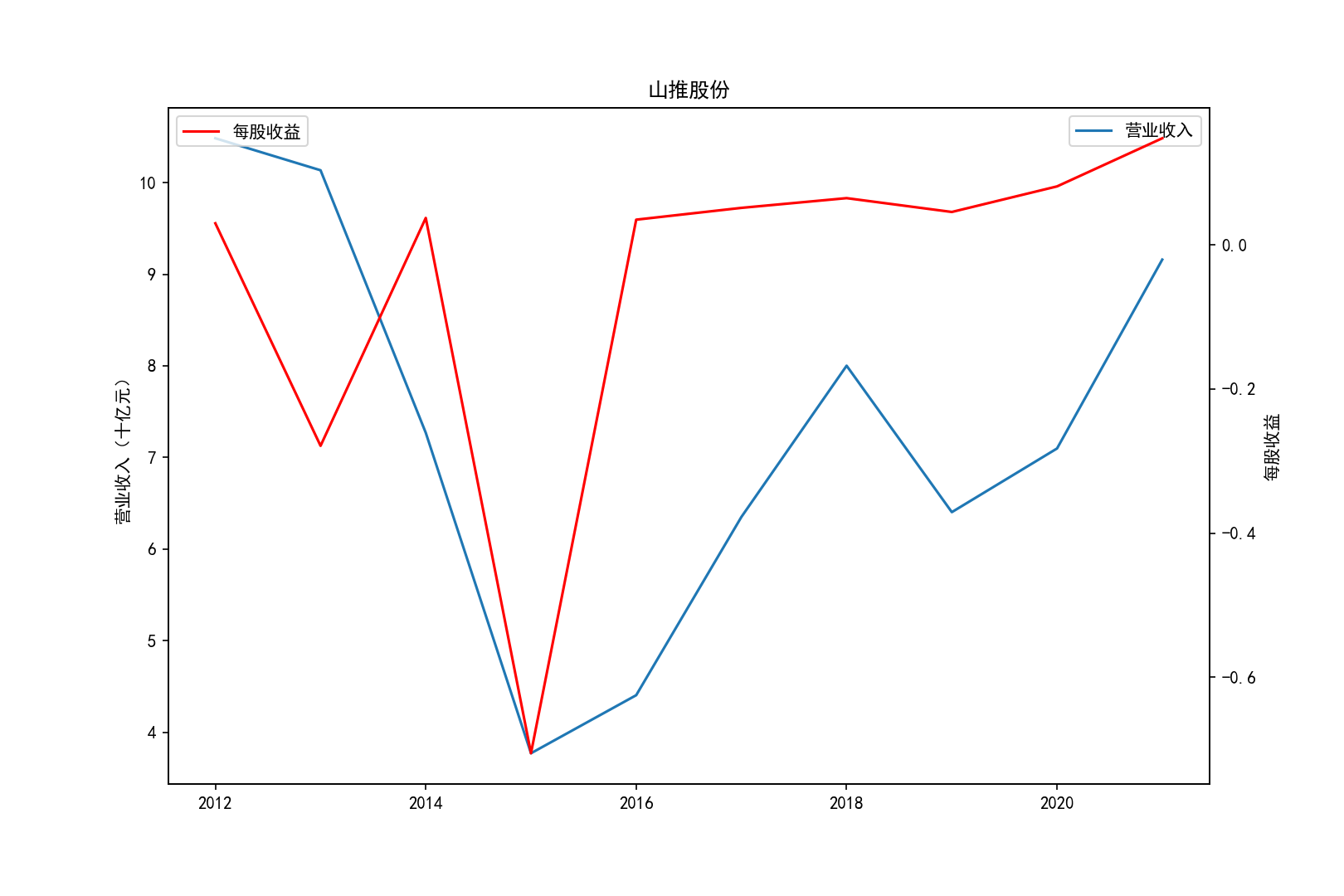
fig = plt.figure(figsize=(10.8, 7.2),dpi=150)
ax1 = fig.add_subplot(111)
ax1.plot(x, y1,label='营业收入')
ax1.set_ylabel('营业收入(十亿元)',)
ax1.set_title(title,)
ax1.legend(loc=0)
ax2 = ax1.twinx()
ax2.plot(x, y2, 'r',label='每股收益')
ax2.set_ylabel('每股收益',)
ax2.set_xlabel('年份')
ax2.legend(loc=0)
plt.savefig(title+".png")
plt.show()
shouru1=shouru.head(4)
shouru2=shouru.iloc[4:8]
shouru3=shouru.tail(3)
meigushouyi1=meigushouyi.head(4)
meigushouyi2=meigushouyi.iloc[4:8]
meigushouyi3=meigushouyi.tail(3)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
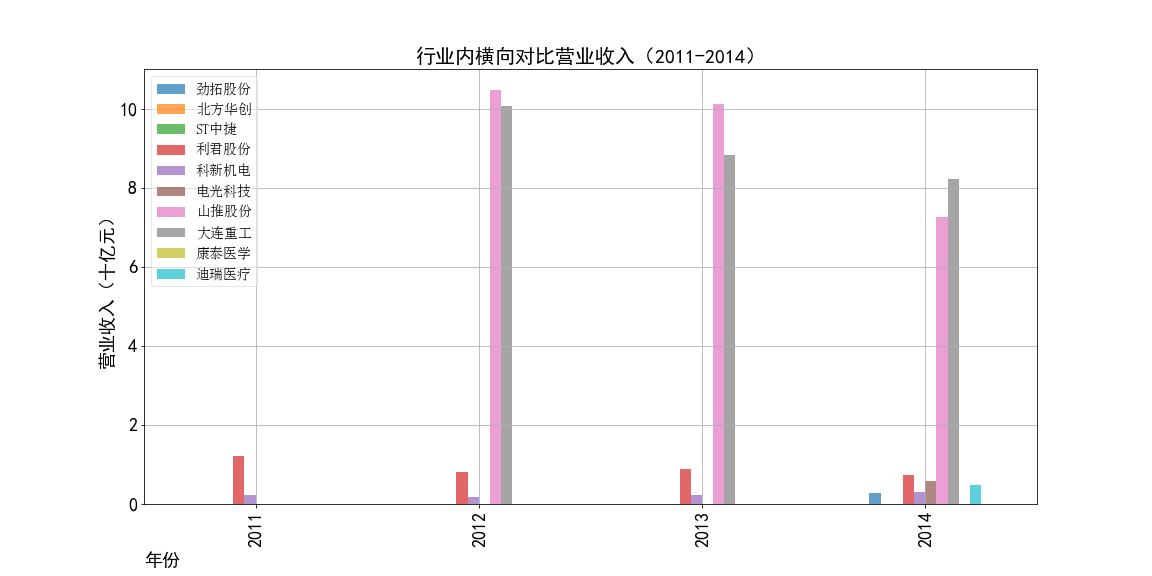
ax1=shouru1.plot(kind='bar',figsize=(16,8),fontsize=18,alpha=0.7,grid=True)
ax1.legend(loc='best',prop={'family':'simsun', 'size': 14},framealpha=0.5)
ax1.set_xlabel('年份',loc='left',fontsize=18)
ax1.set_ylabel('营业收入(十亿元)',fontsize=18)
ax1.set_title('行业内横向对比营业收入(2011-2014)',fontsize=20)
ax1.figure.savefig('2011-2014营业收入对比')
ax2=shouru2.plot(kind='bar',figsize=(16 ,8),fontsize=18,alpha=0.7,grid=True)
ax2.legend(loc='best',prop={'family':'simsun', 'size': 14},framealpha=0.5)
ax2.set_xlabel('年份',loc='left',fontsize=18)
ax2.set_ylabel('营业收入(十亿元)',fontsize=18)
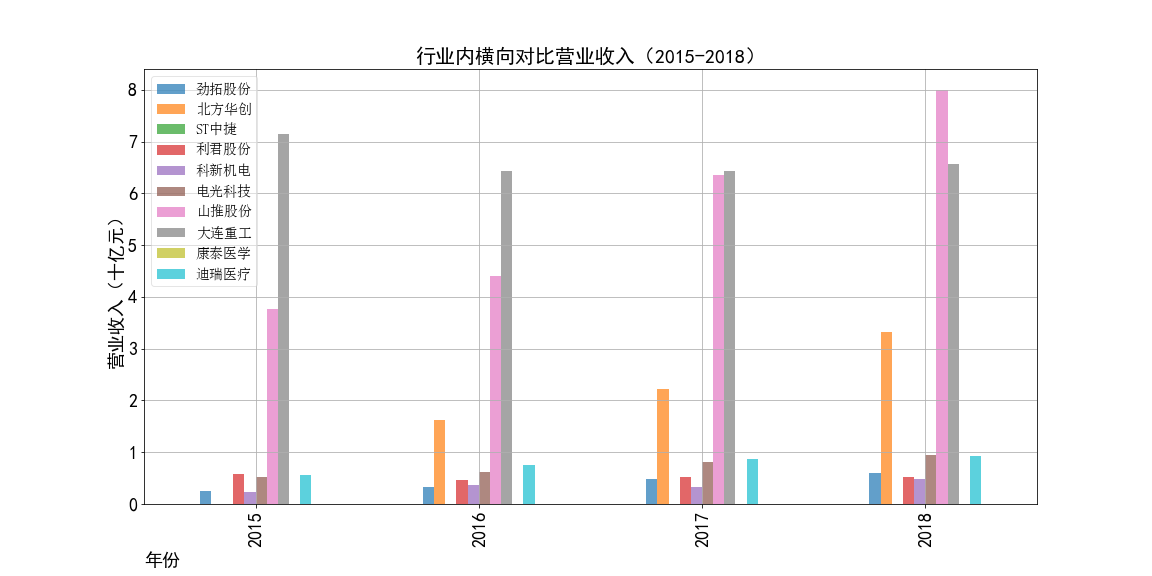
ax2.set_title('行业内横向对比营业收入(2015-2017)',fontsize=20)
ax2.figure.savefig('2015-2016营业收入对比')
ax3=shouru3.plot(kind='bar',figsize=(16,8),fontsize=18,alpha=0.7,grid=True)
ax3.legend(loc='best',prop={'family':'simsun', 'size': 14},framealpha=0.5)
ax3.set_xlabel('年份',loc='left',fontsize=18)
ax3.set_ylabel('营业收入(十亿元)',fontsize=18)
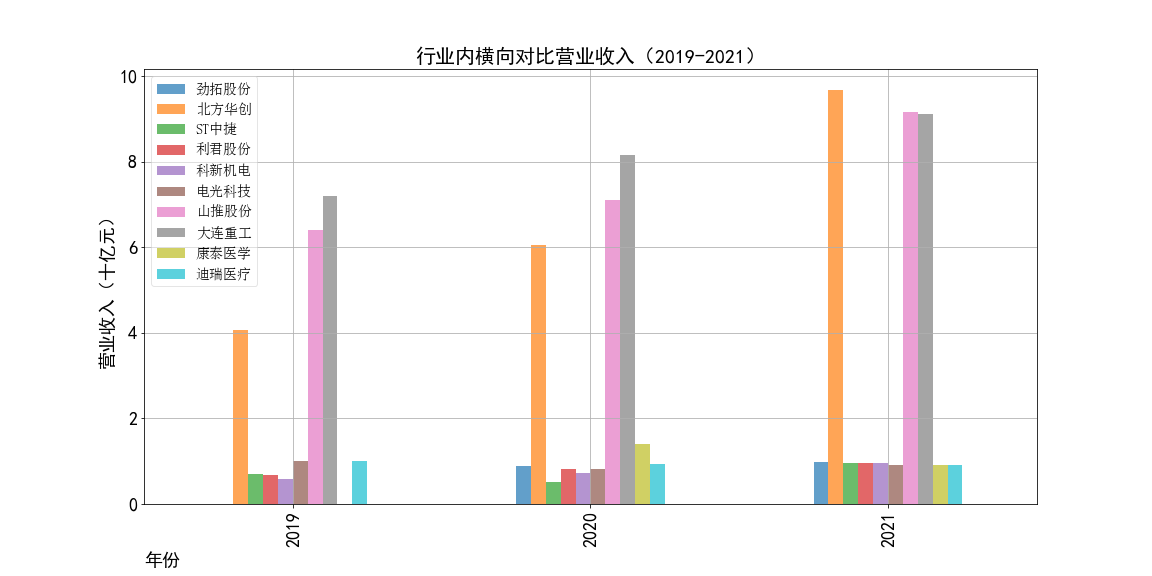
ax3.set_title('行业内横向对比营业收入(2018-2021)',fontsize=20)
ax3.figure.savefig('2017-2021营业收入对比')
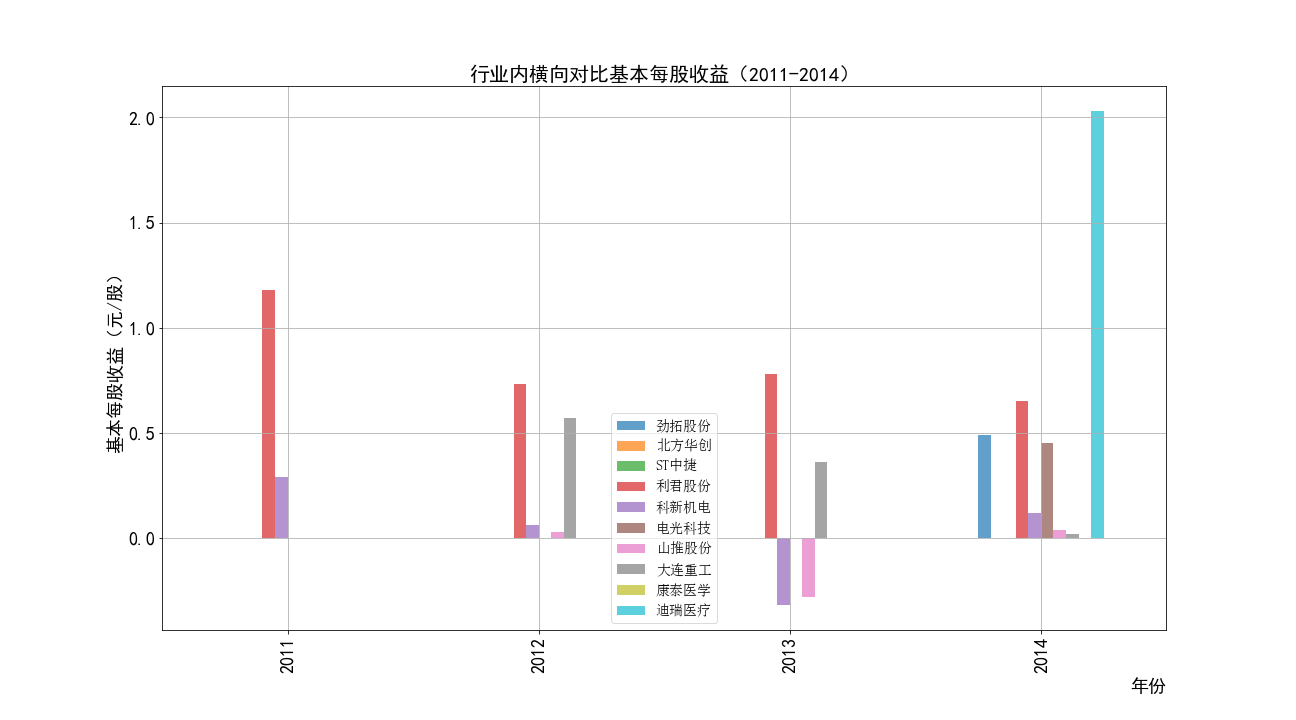
ax1=meigushouyi1.plot(kind='bar',figsize=(18,10),fontsize=18,grid=True,alpha=0.7)
ax1.legend(loc='best',prop={'family':'simsun', 'size': 14},framealpha=0.7)
ax1.set_xlabel('年份',loc='right',fontsize=18)
ax1.set_ylabel('基本每股收益(元/股)',fontsize=18)
ax1.set_title('行业内横向对比基本每股收益(2011-2014)',fontsize=20)
ax1.figure.savefig('2011-2014每股收益对比')
ax2=meigushouyi2.plot(kind='bar',figsize=(18,10),fontsize=18,grid=True,alpha=0.7)
ax2.set_xlabel('年份',loc='right',fontsize=18)
ax2.set_ylabel('基本每股收益(元/股)',fontsize=18)
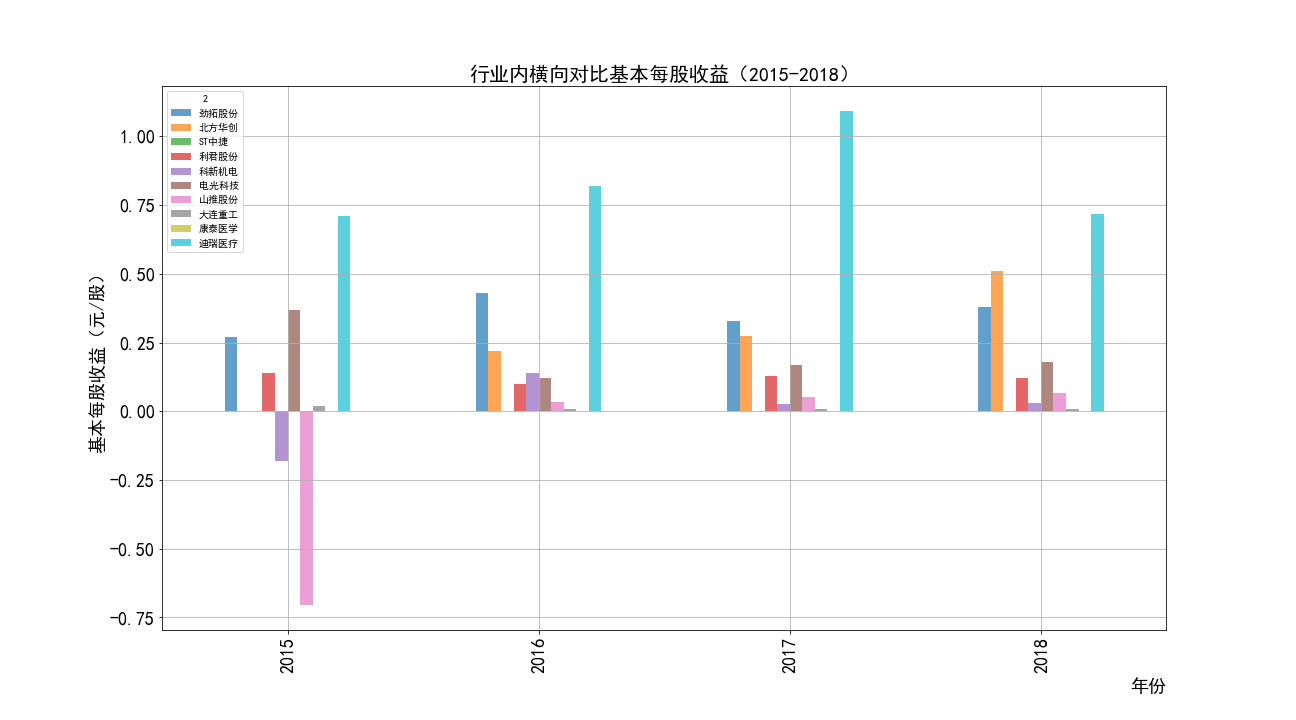
ax2.set_title('行业内横向对比基本每股收益(2015-2017)',fontsize=20)
ax2.figure.savefig('2015-2016每股收益对比')
ax3=meigushouyi3.plot(kind='bar',figsize=(18,10),fontsize=18,grid=True,alpha=0.7)
ax3.legend(loc='best',prop={'family':'simsun', 'size': 14},framealpha=0.3)
ax3.set_xlabel('年份',loc='left',fontsize=18)
ax3.set_ylabel('基本每股收益(元/股)',fontsize=18)
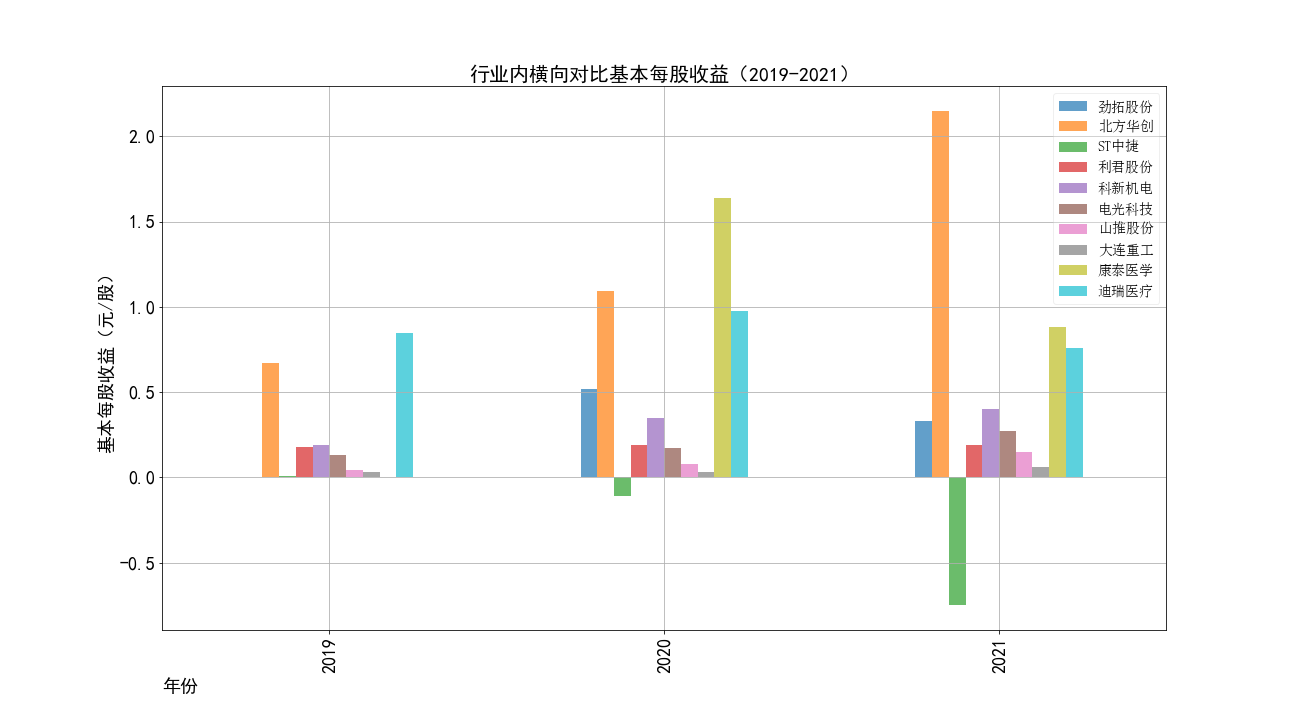
ax3.set_title('行业内横向对比基本每股收益(2018-2021)',fontsize=20)
ax3.figure.savefig('2017-2021每股收益对比')