from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.select import Select
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import pandas as pd
import os
import re
import time
import json
import requests
df_sz = pd.DataFrame({'index': ['000589','000599','000619','000659','000859','000887','000973','002014','002108','002224','002243','002263','002324','002372','002381','002395','002420','002522','002585','002641','002676','002694','002735','002768','002790','002812','002825','002838','002886','002984','003011','003018'],
'name': ['贵州轮胎','青岛双星','海螺型材','珠海中富','国风塑业','中鼎股份','佛塑科技','永新股份','沧州明珠','三力士','力合科创','大东南','普利特','伟星新材','双箭股份','双象股份','毅昌股份','浙江众成','双星新材','永高股份','顺威股份','顾地科技','王子新材','国恩股份','瑞尔特','恩捷股份','纳尔股份','道恩股份','沃特股份','森麒麟','海象新材','金富科技']
})
df_sh = pd.DataFrame({'index': ['600143','600182','600210','600458','600469','601058','601163','601500','601966','603033','603212','603221','603266','603408','603580','603615','603655','603657','603726','603806','603856','603991','603992','605255','605488','688026','688219','688299','688323','688386','688560','688669','688680'],
'name': ['金发科技','SST佳通','紫江企业','时代新材','风神股份','赛轮轮胎','三角轮胎','通用股份','玲珑轮胎','三维股份','赛伍技术','爱丽家居','天龙股份','建霖家居','艾艾精工','茶花股份','朗博科技','春光科技','朗迪集团','福斯特','东宏股份','至正股份','松霖科技','天普股份','福莱新材','洁特生物','会通股份','长阳科技','瑞华泰','泛亚微透','明冠新材','聚石化学','海优新材']
})
name_sz = df_sz['name'].tolist()
code_sh = df_sh['index'].tolist()
driver = webdriver.Edge()
def getszHTML(name): #定义函数,获取深交所上市公司html网页
driver.get("http://www.szse.cn/disclosure/listed/fixed/index.html")
driver.maximize_window()
driver.implicitly_wait(3)
driver.find_element(By.ID, "input_code").click()
driver.find_element(By.ID, "input_code").send_keys(name)
driver.find_element(By.ID, "input_code").send_keys(Keys.DOWN)
driver.find_element(By.ID, "input_code").send_keys(Keys.ENTER)
driver.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
driver.find_element(By.LINK_TEXT, "年度报告").click()
driver.find_element(By.CSS_SELECTOR, ".input-left").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 .calendar-year span").click()
driver.find_element(By.CSS_SELECTOR, ".active li:nth-child(113)").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 tr:nth-child(1) > .available:nth-child(3) > .tdcontainer").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-2 tr:nth-child(2) > .weekend:nth-child(1) > .tdcontainer").click()
driver.find_element(By.ID, "query-btn").click()
element = driver.find_element(By.ID, 'disclosure-table')
def getshHTML(code): #定义函数,获取上交所上市公司html网页
driver.get("http://www.sse.com.cn/disclosure/listedinfo/regular/")
driver.maximize_window()
driver.implicitly_wait(3)
driver.find_element(By.ID, "inputCode").click()
driver.find_element(By.ID, "inputCode").send_keys(code)
driver.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
driver.find_element(By.LINK_TEXT, "年报").click()
def Save(filename,content): #保存文件
name = open(filename+'.html','w',encoding='utf-8')
name.write(content)
name.close()
i=1
for code in code_sh:#爬取深交所上市公司html
getshHTML(code)
time.sleep(1)
html = driver.find_element(By.CLASS_NAME, 'table-responsive')
innerHTML = html.get_attribute('innerHTML')
Save(code,innerHTML)
print('上交所共有',len(code_sh),'家,已获取第',i,'/',len(code_sh))
i=i+1
i=1
for name in name_sz:#爬取上交所上市公司html
getszHTML(name)
time.sleep(1)
html = driver.find_element(By.ID, 'disclosure-table')
innerHTML = html.get_attribute('innerHTML')
Save(name,innerHTML)
driver.refresh()
time.sleep(1)
print('深交所共有',len(name_sz),'家,已获取第',i,'/',len(name_sz))
i=i+1
driver.quit()
print('获取完毕')
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('
(.*?)
', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'公告时间': times,
'href': [prefix_href + aht[1] for aht in ahts]
})
self.df_data = df
return(df)
def getshDATA(code): #解析上交所公司html
f = open(code+'.html',encoding='utf-8')
html = f.read()
f.close()
p1 = re.compile('
(.*?)
', re.DOTALL)
tds = p1.findall(html)
p_code_name = re.compile('(.*?).*?(.*?)', re.DOTALL)
codes = [p_code_name.search(td).group(1) for td in tds]
names = [p_code_name.search(td).group(2) for td in tds]
p2 = re.compile('(.*?)(.*?)',
re.DOTALL)
href = [p2.search(td).group(1) for td in tds]
titles = [p2.search(td).group(2) for td in tds]
times = [p2.search(td).group(3) for td in tds]
prefix0 = 'http://www.sse.com.cn'
df = pd.DataFrame({'证券代码': codes,
'简称': names[1],
'公告标题': [lf.strip() for lf in titles],
'href': [prefix0 + lf.strip() for lf in href],
'公告时间': [t.strip() for t in times]
})
return(df)
def Readhtml(filename): #读取
with open(filename+'.html', encoding='utf-8') as f:
html = f.read()
return html
def tidy(df): #清除
d = []
for index, row in df.iterrows():
dd = row[2]
n = re.search("摘要|取消|英文", dd)
if n != None:
d.append(index)
df1 = df.drop(d).reset_index(drop = True)
return df1
def filter_links(words,df,include=True):
ls=[]
for word in words:
if include:
ls.append([word in f for f in df.公告标题])
else:
ls.append([word not in f for f in df.公告标题])
index = []
for r in range(len(df)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df2 = df[index]
return(df2)
def rename(df):
for i in df["简称"]:
i = i.replace("*","")
i = i.replace(" ","")
if i !="-":
sn=i
return sn
def Loadpdf_sh(df): #用于下载文件
d1 = {}
df["公告时间"] = pd.to_datetime(df["公告时间"])
na = rename(df)
for index, row in df.iterrows():
names = na + str(row[4].year-1)+"年年度报告"
d1[names] = row[3]
for key, value in d1.items():
f = requests.get(value)
with open (key + ".pdf", "wb") as ff:
ff.write(f.content)
def Loadpdf(df): #用于下载文件
d1 = {}
for index, row in df.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
with open (key + ".pdf", "wb") as code:
code.write(f.content)
i = 0
for index,row in df_sh.iterrows(): #提取上交所信息表
i+=1
code = row[0]
name = row[1]
df = getshDATA(code)
df_all = filter_links(["摘要","营业","并购","承诺","取消","英文"],df,include= False)
df_orig = filter_links(["(","("],df_all,include = False)
df_updt = filter_links(["(","("],df_all,include = True)
df_updt = filter_links(["取消"],df_updt,include = False)
df_all.to_csv(name+'.csv',encoding='utf-8-sig')
os.makedirs(name,exist_ok=True)
os.chdir(name)
Loadpdf_sh(df_all)
print(code+'年报已保存完毕。共',len(code_sh),'所公司,当前第',i,'所。')
os.chdir('../')
i = 0
for index,row in df_sz.iterrows(): #提取深交所信息表
i+=1
name = row[1].replace('*','')
html = Readhtml(name)
dt = DisclosureTable(html)
df = dt.get_data()
df1 = tidy(df)
df1.to_csv(name+'.csv',encoding='utf-8-sig')
os.makedirs(name,exist_ok=True)
os.chdir(name)
Loadpdf(df1)
print(name+'年报已保存完毕。共',len(name_sz),'所公司,当前第',i,'所。')
os.chdir('../')
结果
Part 2 数据处理与筛选
import pandas as pd
import fitz
import re
df_company = pd.DataFrame({'index': ['000589','000599','000659','000859','000887','002108','002224','002263','002324','002381','002395','002420','002522','002585','002641','002676','002694','002735','002768','002790','002825','002838','002886','002984','003011','003018'],
'name': ['贵州轮胎','青岛双星','珠海中富','国风塑业','中鼎股份','沧州明珠','三力士','大东南','普利特','双箭股份','双象股份','毅昌股份','浙江众成','双星新材','永高股份','顺威股份','顾地科技','王子新材','国恩股份','瑞尔特','纳尔股份','道恩股份','沃特股份','森麒麟','海象新材','金富科技']
})
company = df_company['name'].tolist()
t=0
for member in company:
t+=1
member = member.replace('*','')
df = pd.read_csv(member+'.csv',converters={'证券代码':str})
df = df.sort_index(ascending=False)
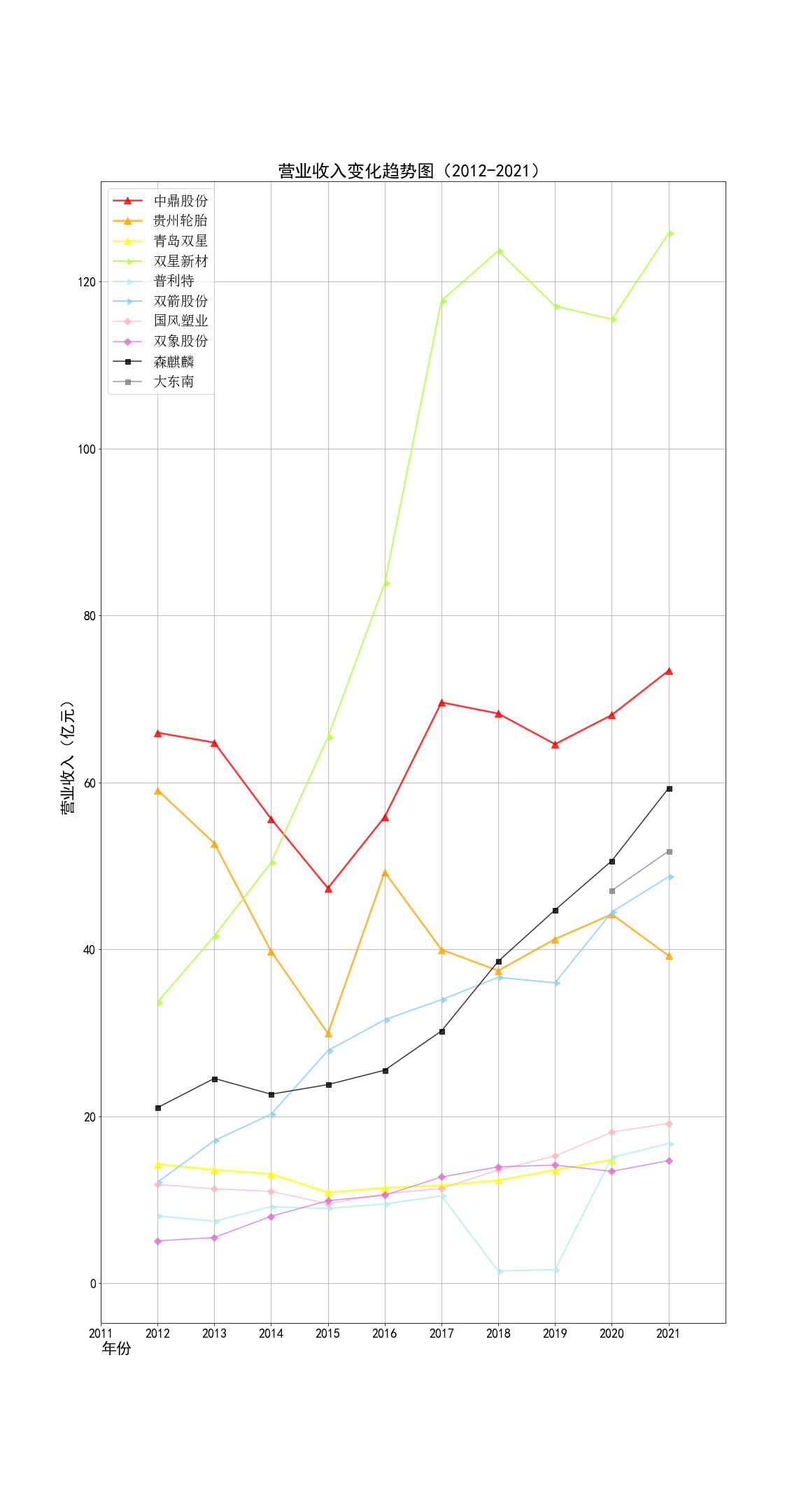
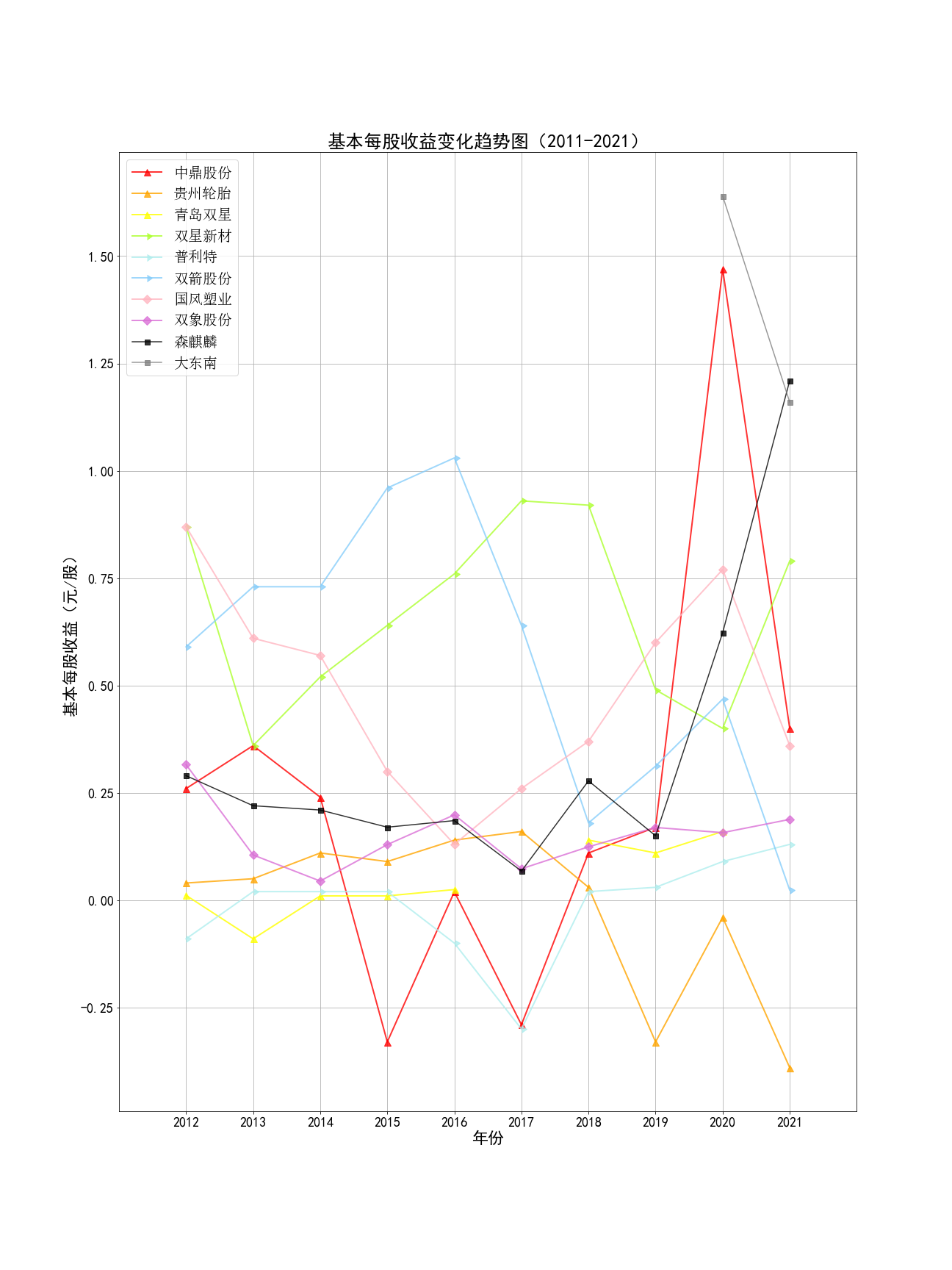
final = pd.DataFrame(index=range(2012,2022),columns=['营业收入(元)','基本每股收益(元/股)'])
final.index.name='年份'
code = str(df.iloc[0,1])
name = df.iloc[-1,2].replace(' ','')
for i in range(len(df)):
title=df.iloc[i,3]
doc = fitz.open('./%s/%s.pdf'%(member,title))
text=''
for j in range(20):
page = doc[j]
text += page.get_text()
p_year=re.compile('.*?(\d{4}) .*?年度报告.*?')
year = int(p_year.findall(text)[0])
#设置需要匹配的四种数据的pattern
p_rev = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
p_eps = re.compile('(?<=\n)基本每股收益(元/?/?\n?股)\s?\n?([-\d+,.]*)\s?\n?')
p_site = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
p_web =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./:]*)\s?(?=\n)',re.DOTALL)
revenue=float(p_rev.search(text).group(1).replace(',',''))
eps=p_eps.search(text).group(1)
final.loc[year,'营业收入(元)']=revenue
final.loc[year,'基本每股收益(元/股)']=eps
final.to_csv('%s数据.csv' %member,encoding='utf-8-sig')
site=p_site.search(text).group(1)
web=p_web.search(text).group(1)
with open('%s数据.csv'%member,'a',encoding='utf-8-sig') as f:
result='股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name,code,site,web)
f.write(result)
print(name+'数据已保存完毕'+'(',t,'/',len(company),')')
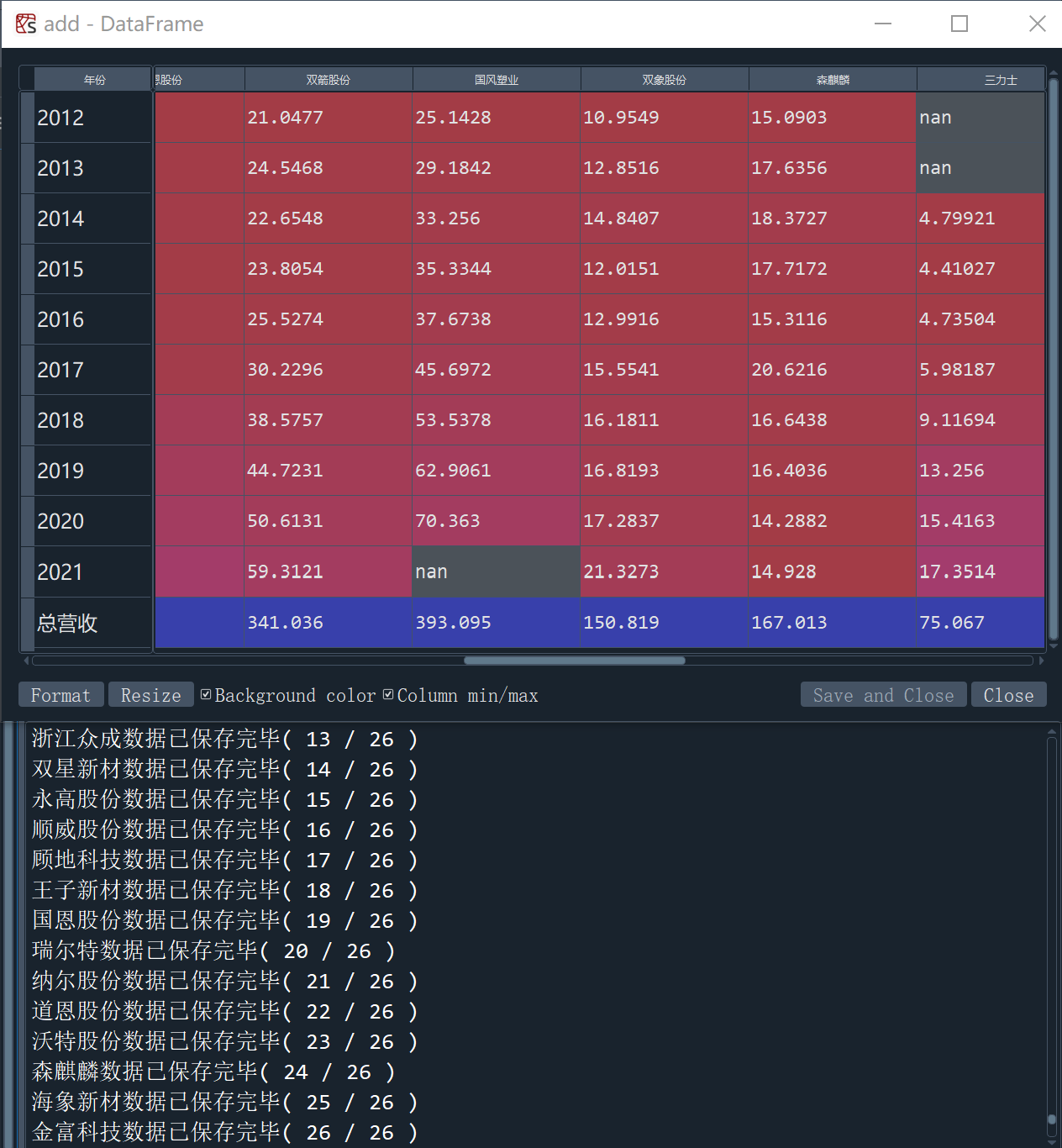
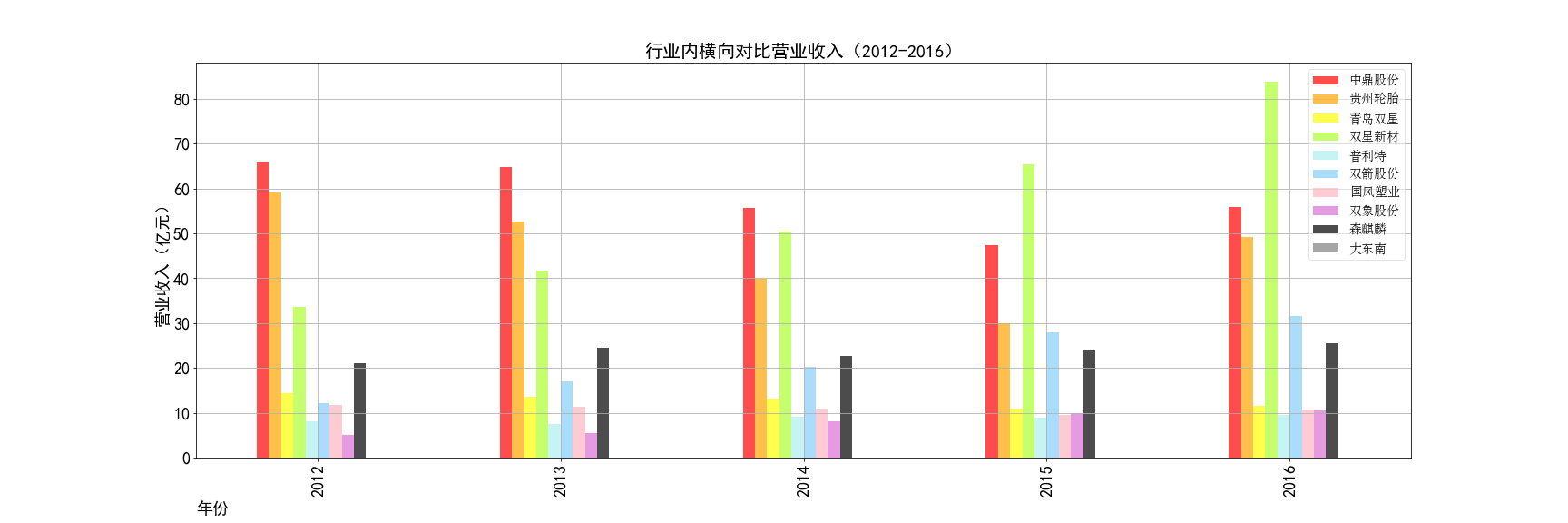
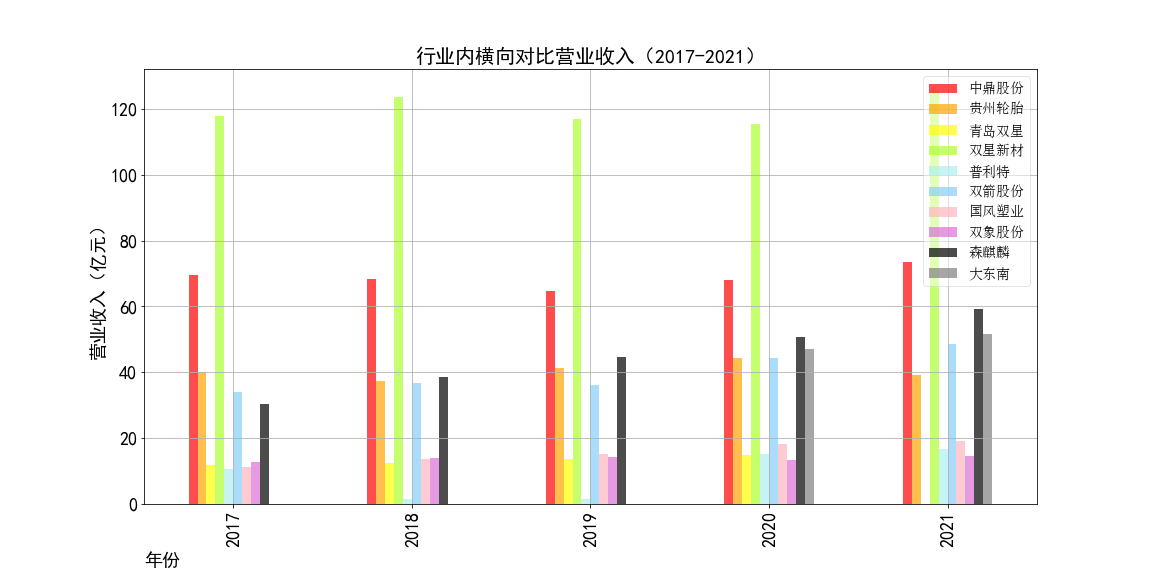
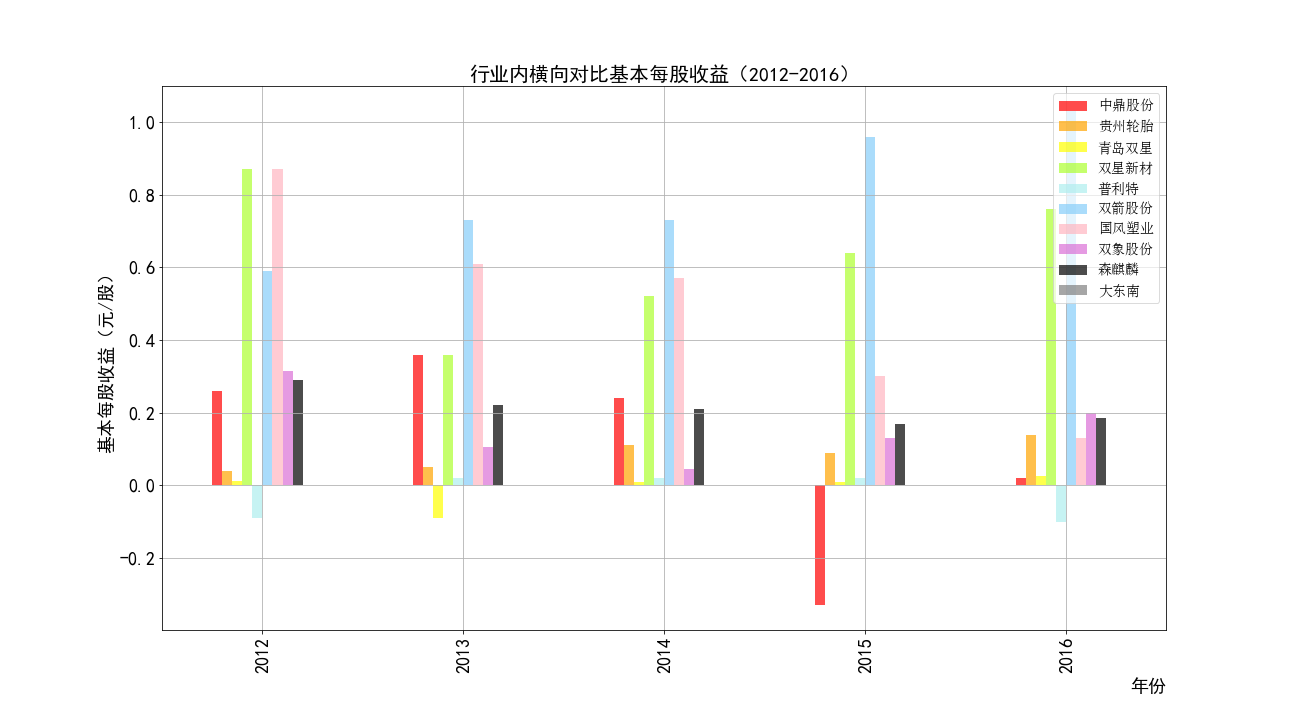
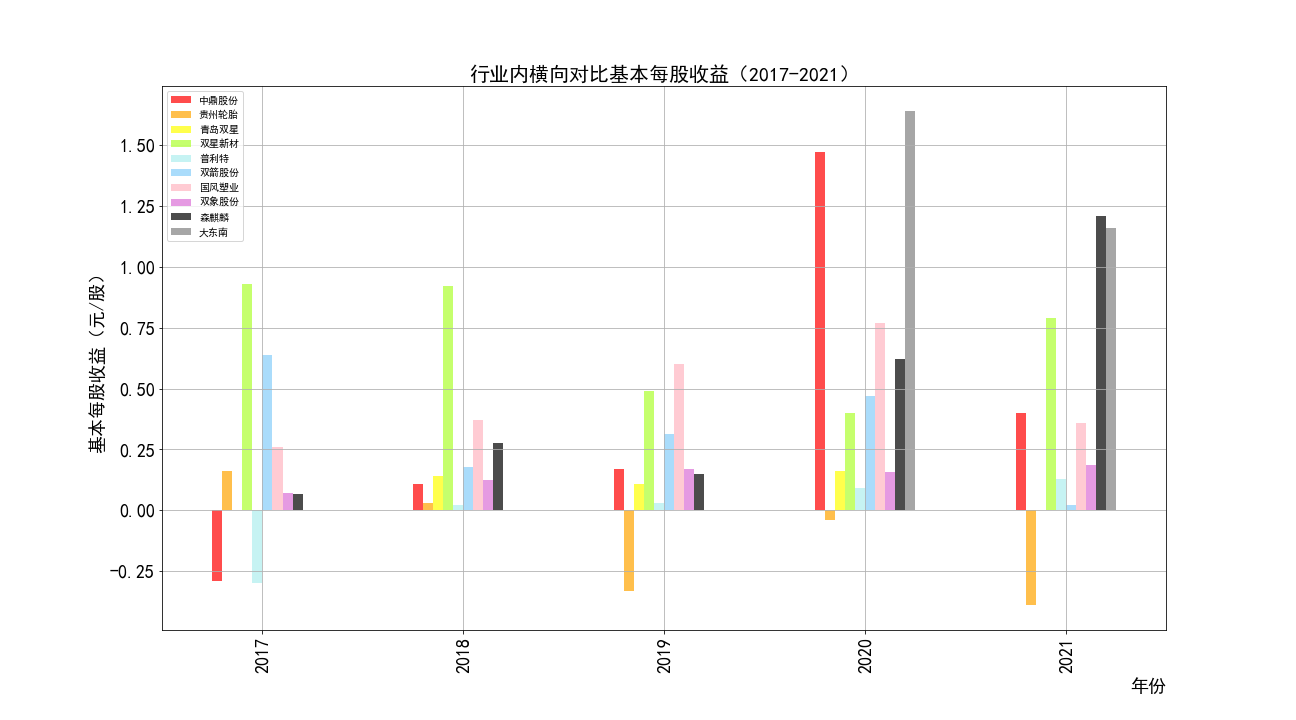
add = hori_rev
add.loc["总营收"] = add.apply(lambda x:x.sum()) # 数据筛选