import json
import os
from time import sleep
from urllib import parse
import requests
import time,random
from fake_useragent import UserAgent
ua = UserAgent()
userAgen = ua.random
def get_adress(bank_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': bank_name,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent':userAgen,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
get_json = requests.post(url, headers=hd, data=data)
data_json = get_json.content
toStr = str(data_json, encoding="utf-8")
last_json = json.loads(toStr)
orgId = last_json["keyBoardList"][0]["orgId"] # 获取参数
plate = last_json["keyBoardList"][0]["plate"]
code = last_json["keyBoardList"][0]["code"]
return orgId, plate, code
def download_PDF(url, file_name): # 下载pdf
url = url
r = requests.get(url)
f = open(company + "/" + file_name + ".pdf", "wb")
f.write(r.content)
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 20,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'User-Agent': ua.random,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
}
data = parse.urlencode(data)
data_json = requests.post(url, headers=hd, data=data)
toStr = str(data_json.content, encoding="utf-8")
last_json = json.loads(toStr)
reports_list = last_json['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']:
continue
if 'H' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:" + pdf_url, "存放在当前目录:/" + company + "/" + file_name)
download_PDF(pdf_url, file_name)
time.sleep(random.random()*3)
if __name__ == '__main__':
list = ["000301","000420","000677","000703","000782","000936","000949","002064","002172","002206","002254","002427","2493"]
for company in list:
os.mkdir(company)
orgId, plate, code=get_adress(company)
get_PDF(orgId, plate, code)
#然后将获取的公司年报地址存入csv文件中并且删除摘要文件链接
for i in range(len(firm)):
name = firm[i][1]
f = open('inner_HTML_%s.html' %name,encoding='utf-8')
t = f.read()
f.close()
dt = DisclosureTable(t)
df = dt.get_data()
df.to_csv('data_%s.csv' %name)
lst = {}
df5 = pd.DataFrame(columns = ['股票简称','attachpath'])
df4 = pd.DataFrame(columns = ['股票简称'])
for i in range(len(firm)):
name = firm[i][1]
df1 = pd.DataFrame(columns = ['股票简称','attachpath'])
with open('data_%s.csv' %name,'r',newline='',encoding='utf-8') as csvfile:
csvreader = csv.reader(csvfile)
reader = next(csvreader)
for row in csvreader:
r = re.compile('.*摘要.*',re.DOTALL)
f = r.findall(row[3])
if f == []:
lst1 = {}
lst['股票简称'] = name
lst['attachpath'] = row[4]
lst1['股票简称'] = name
df1 = df1.append(lst,ignore_index=True)
df4 = df4.append(lst1,ignore_index=True)
df5 = df5.append(lst,ignore_index=True)
df4 = df4.drop_duplicates()
#下载获取的pdf文件
for k in range(len(df1[df1['股票简称']=='{}'.format(name)])):
r = requests.get(df1['attachpath'][k],allow_redirects=True)
f = open('{0}_{1}.pdf'.format(df1['股票简称'][k],k),'wb')
f.write(r.content)
f.close()
r.close()
#提取PDF文件中“股票简称”,“股票代码”,“办公地址”,“公司网址”
df2 = pd.DataFrame(columns=['股票简称','股票代码','办公地址','公司网址'])
for x in range(len(df4)):
name = df4['股票简称'][x]
doc = fitz.open('{0}_0.pdf'.format(name))
lst = ['股票简称','股票代码','办公地址','公司[国际互联网]*网址']
pages = {}
lst_text = {}
for i in lst:
try:
p = re.compile(i,re.DOTALL)
page_number = doc.page_count#获取文件页数
#对每一页进行遍历,匹配lst中的每一个元素
for page in range(page_number):
txt = doc[page].get_text()
match = p.findall(txt)
#若匹配到的macth不为空,则提取此时的页码
if len(match) != 0:
pages[i] = page
for k,v in pages.items():
text = doc[v].get_text()
r1 = re.compile('股票简称\s+(.+?)\n',re.DOTALL)
p1 = r1.findall(text)
lst_text['股票简称'] = p1[0]
r2 = re.compile('股票代码\s+(\d+)\s+',re.DOTALL)
p2 = r2.findall(text)
lst_text['股票代码'] = p2[0]
r3 = re.compile('办公地址\s+(.+?)\n',re.DOTALL)
p3 = r3.findall(text)
lst_text['办公地址'] = p3[0]
r4 = re.compile('公司[国际互联网]*网址\s+(.*?.+?)\s+',re.DOTALL)
p4 = r4.findall(text)
lst_text['公司网址'] = p4[0]
except Exception:
print('错误')
df2 = df2.append(lst_text,ignore_index=True)
 #提取“营业收入(元)”
r1 = re.compile('\s营业[总]*收入(元)\s*(-?[\d,.]+)\s*',re.DOTALL)
r2 = re.compile('\n(20[\d]{2}\s年)年度报告',re.DOTALL)
r3 = re.compile('\s基本每股收益(元/股)\s*(-?[\d,.]+)\s*',re.DOTALL)
for n in range(len(df4)):
x = df4['股票简称'][n]
data = pd.DataFrame()
for i in range(len(df5[df5['股票简称']=='{}'.format(x)])):
#遍历每一个PDF文件
doc = fitz.open('{0}_{1}.pdf'.format(x,i))
#读取报告年份
f2 = doc[0].get_text()
year = r2.findall(f2)
page_num = doc.page_count
for page in range(page_num):
#匹配营业收入
f1 = doc[page].get_text()
match1 = r1.findall(f1)
if match1 != []:
profit = match1[0]
data1 = pd.DataFrame(profit,index=[x],columns=year)
data = pd.concat([data1,data],join='outer',axis=1)
data.to_csv('{}——营业收入.csv'.format(x),encoding='utf-8')
#提取“基本每股收益(元/股)”
for n in range(len(df4)):
x = df4['股票简称'][n]
data = pd.DataFrame()
for i in range(len(df5[df5['股票简称']=='{}'.format(x)])):
#遍历每一个PDF文件
doc = fitz.open('{0}_{1}.pdf'.format(x,i))
#读取报告年份
f2 = doc[0].get_text()
year = r2.findall(f2)
page_num = doc.page_count
#name = df4.loc[n]
for page in range(page_num):
#匹配营业收入
f1 = doc[page].get_text()
match1 = r3.findall(f1)
if match1 != []:
profit = match1[0]
data1 = pd.DataFrame(profit,index=[x],columns=year)
data = pd.concat([data1,data],join='outer',axis=1)
data.to_csv('{}——每股收益.csv'.format(x),encoding='utf-8')
#绘图
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False
df = pd.read_csv('行业信息.csv',index_col=0,dtype=(str))
df_eps = pd.read_csv('基本每股收益.csv',index_col=0)
df_revenue = pd.read_csv('营业收入.csv',index_col=0)
df_information = pd.read_csv('化学原料与化学制品制造业信息.csv',index_col=0,dtype=(str))
df_revenue = df_revenue/100000000
df_revenue.loc['sum'] = df_revenue.sum()
df_revenue = df_revenue.T
df_revenue = df_revenue.sort_values(by='sum',ascending=False,axis=0)
df_revenue = df_revenue.iloc[:10]
top10_list = df_revenue.index.values.tolist()
for i in range(len(top10_list)):
top10_list[i] = top10_list[i][:-6]
#读取基本每股收益
dt0 = pd.read_csv('东方盛虹营业收入年报.csv',encoding='utf-8')
dt0 = dt0.rename(columns={'Unnamed: 0':'Data'})
dt0 = dt0.set_index('Data')
#删除重复列
del dt0['2020 年.1']
#将数据转换为浮点型
dt0.loc['东方盛虹'] = dt0.loc['东方盛虹'].str.replace(',','').astype(float)
dt1 = pd.read_csv('吉林化纤营业收入年报.csv',encoding='utf-8')
dt1 = dt1.rename(columns={'Unnamed: 0':'Data'})
dt1 = dt1.set_index('Data')
dt1.loc['吉林化纤'] = dt1.loc['吉林化纤'].str.replace(',','').astype(float)
dt2 = pd.read_csv('恒天海龙营业收入年报.csv',encoding='utf-8')
dt2 = dt2.rename(columns={'Unnamed: 0':'Data'})
dt2 = dt2.set_index('Data')
dt2.loc['恒天海龙'] = dt2.loc['恒天海龙'].str.replace(',','').astype(float)
dt3 = pd.read_csv('恒逸石化营业收入年报.csv',encoding='utf-8')
dt3 = dt3.rename(columns={'Unnamed: 0':'Data'})
dt3 = dt3.set_index('Data')
dt3.loc['恒逸石化'] = dt3.loc['恒逸石化'].str.replace(',','').astype(float)
dt4 = pd.read_csv('美达股份营业收入年报.csv',encoding='utf-8')
dt4 = dt4.rename(columns={'Unnamed: 0':'Data'})
dt4 = dt4.set_index('Data')
dt4.loc['美达股份'] = dt4.loc['美达股份'].str.replace(',','').astype(float)
dt5 = pd.read_csv('华西股份营业收入年报.csv',encoding='utf-8')
dt5 = dt5.rename(columns={'Unnamed: 0':'Data'})
dt5 = dt5.set_index('Data')
dt5.loc['华西股份'] = dt5.loc['华西股份'].str.replace(',','').astype(float)
dt6 = pd.read_csv('新乡化纤营业收入年报.csv',encoding='utf-8')
dt6 = dt6.rename(columns={'Unnamed: 0':'Data'})
dt6 = dt6.set_index('Data')
dt6.loc['新乡化纤'] = dt6.loc['新乡化纤'].str.replace(',','').astype(float)
dt7 = pd.read_csv('华峰化学营业收入年报.csv',encoding='utf-8')
dt7 = dt7.rename(columns={'Unnamed: 0':'Data'})
dt7 = dt7.set_index('Data')
dt7.loc['华峰化学'] = dt7.loc['华峰化学'].str.replace(',','').astype(float)
dt8 = pd.read_csv('澳洋健康营业收入年报.csv',encoding='utf-8')
dt8 = dt8.rename(columns={'Unnamed: 0':'Data'})
dt8 = dt8.set_index('Data')
dt8.loc['澳洋健康'] = dt8.loc['澳洋健康'].str.replace(',','').astype(float)
dt9 = pd.read_csv('海利得营业收入年报.csv',encoding='utf-8')
dt9 = dt9.rename(columns={'Unnamed: 0':'Data'})
dt9 = dt9.set_index('Data')
dt9.loc['海利得'] = dt9.loc['海利得'].str.replace(',','').astype(float)
#提取“营业收入(元)”
r1 = re.compile('\s营业[总]*收入(元)\s*(-?[\d,.]+)\s*',re.DOTALL)
r2 = re.compile('\n(20[\d]{2}\s年)年度报告',re.DOTALL)
r3 = re.compile('\s基本每股收益(元/股)\s*(-?[\d,.]+)\s*',re.DOTALL)
for n in range(len(df4)):
x = df4['股票简称'][n]
data = pd.DataFrame()
for i in range(len(df5[df5['股票简称']=='{}'.format(x)])):
#遍历每一个PDF文件
doc = fitz.open('{0}_{1}.pdf'.format(x,i))
#读取报告年份
f2 = doc[0].get_text()
year = r2.findall(f2)
page_num = doc.page_count
for page in range(page_num):
#匹配营业收入
f1 = doc[page].get_text()
match1 = r1.findall(f1)
if match1 != []:
profit = match1[0]
data1 = pd.DataFrame(profit,index=[x],columns=year)
data = pd.concat([data1,data],join='outer',axis=1)
data.to_csv('{}——营业收入.csv'.format(x),encoding='utf-8')
#提取“基本每股收益(元/股)”
for n in range(len(df4)):
x = df4['股票简称'][n]
data = pd.DataFrame()
for i in range(len(df5[df5['股票简称']=='{}'.format(x)])):
#遍历每一个PDF文件
doc = fitz.open('{0}_{1}.pdf'.format(x,i))
#读取报告年份
f2 = doc[0].get_text()
year = r2.findall(f2)
page_num = doc.page_count
#name = df4.loc[n]
for page in range(page_num):
#匹配营业收入
f1 = doc[page].get_text()
match1 = r3.findall(f1)
if match1 != []:
profit = match1[0]
data1 = pd.DataFrame(profit,index=[x],columns=year)
data = pd.concat([data1,data],join='outer',axis=1)
data.to_csv('{}——每股收益.csv'.format(x),encoding='utf-8')
#绘图
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False
df = pd.read_csv('行业信息.csv',index_col=0,dtype=(str))
df_eps = pd.read_csv('基本每股收益.csv',index_col=0)
df_revenue = pd.read_csv('营业收入.csv',index_col=0)
df_information = pd.read_csv('化学原料与化学制品制造业信息.csv',index_col=0,dtype=(str))
df_revenue = df_revenue/100000000
df_revenue.loc['sum'] = df_revenue.sum()
df_revenue = df_revenue.T
df_revenue = df_revenue.sort_values(by='sum',ascending=False,axis=0)
df_revenue = df_revenue.iloc[:10]
top10_list = df_revenue.index.values.tolist()
for i in range(len(top10_list)):
top10_list[i] = top10_list[i][:-6]
#读取基本每股收益
dt0 = pd.read_csv('东方盛虹营业收入年报.csv',encoding='utf-8')
dt0 = dt0.rename(columns={'Unnamed: 0':'Data'})
dt0 = dt0.set_index('Data')
#删除重复列
del dt0['2020 年.1']
#将数据转换为浮点型
dt0.loc['东方盛虹'] = dt0.loc['东方盛虹'].str.replace(',','').astype(float)
dt1 = pd.read_csv('吉林化纤营业收入年报.csv',encoding='utf-8')
dt1 = dt1.rename(columns={'Unnamed: 0':'Data'})
dt1 = dt1.set_index('Data')
dt1.loc['吉林化纤'] = dt1.loc['吉林化纤'].str.replace(',','').astype(float)
dt2 = pd.read_csv('恒天海龙营业收入年报.csv',encoding='utf-8')
dt2 = dt2.rename(columns={'Unnamed: 0':'Data'})
dt2 = dt2.set_index('Data')
dt2.loc['恒天海龙'] = dt2.loc['恒天海龙'].str.replace(',','').astype(float)
dt3 = pd.read_csv('恒逸石化营业收入年报.csv',encoding='utf-8')
dt3 = dt3.rename(columns={'Unnamed: 0':'Data'})
dt3 = dt3.set_index('Data')
dt3.loc['恒逸石化'] = dt3.loc['恒逸石化'].str.replace(',','').astype(float)
dt4 = pd.read_csv('美达股份营业收入年报.csv',encoding='utf-8')
dt4 = dt4.rename(columns={'Unnamed: 0':'Data'})
dt4 = dt4.set_index('Data')
dt4.loc['美达股份'] = dt4.loc['美达股份'].str.replace(',','').astype(float)
dt5 = pd.read_csv('华西股份营业收入年报.csv',encoding='utf-8')
dt5 = dt5.rename(columns={'Unnamed: 0':'Data'})
dt5 = dt5.set_index('Data')
dt5.loc['华西股份'] = dt5.loc['华西股份'].str.replace(',','').astype(float)
dt6 = pd.read_csv('新乡化纤营业收入年报.csv',encoding='utf-8')
dt6 = dt6.rename(columns={'Unnamed: 0':'Data'})
dt6 = dt6.set_index('Data')
dt6.loc['新乡化纤'] = dt6.loc['新乡化纤'].str.replace(',','').astype(float)
dt7 = pd.read_csv('华峰化学营业收入年报.csv',encoding='utf-8')
dt7 = dt7.rename(columns={'Unnamed: 0':'Data'})
dt7 = dt7.set_index('Data')
dt7.loc['华峰化学'] = dt7.loc['华峰化学'].str.replace(',','').astype(float)
dt8 = pd.read_csv('澳洋健康营业收入年报.csv',encoding='utf-8')
dt8 = dt8.rename(columns={'Unnamed: 0':'Data'})
dt8 = dt8.set_index('Data')
dt8.loc['澳洋健康'] = dt8.loc['澳洋健康'].str.replace(',','').astype(float)
dt9 = pd.read_csv('海利得营业收入年报.csv',encoding='utf-8')
dt9 = dt9.rename(columns={'Unnamed: 0':'Data'})
dt9 = dt9.set_index('Data')
dt9.loc['海利得'] = dt9.loc['海利得'].str.replace(',','').astype(float)
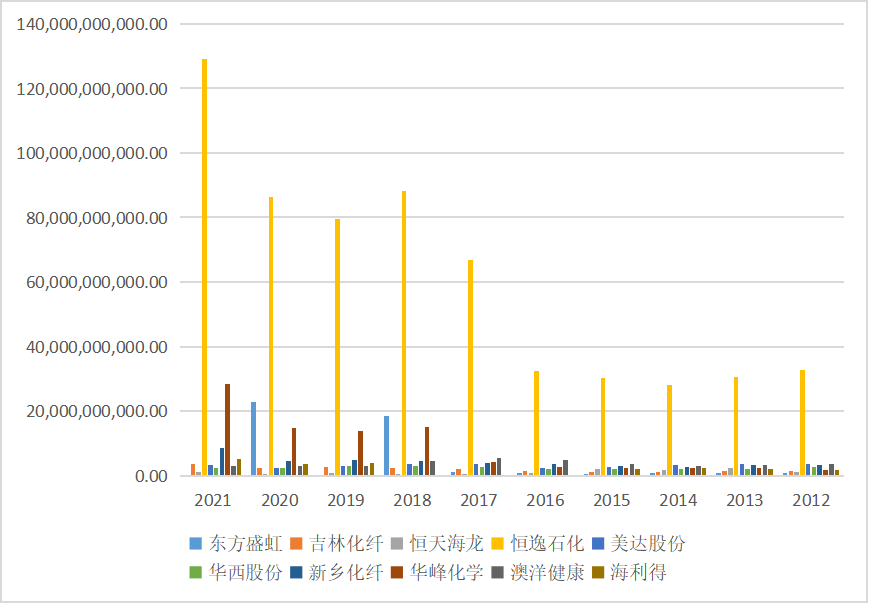
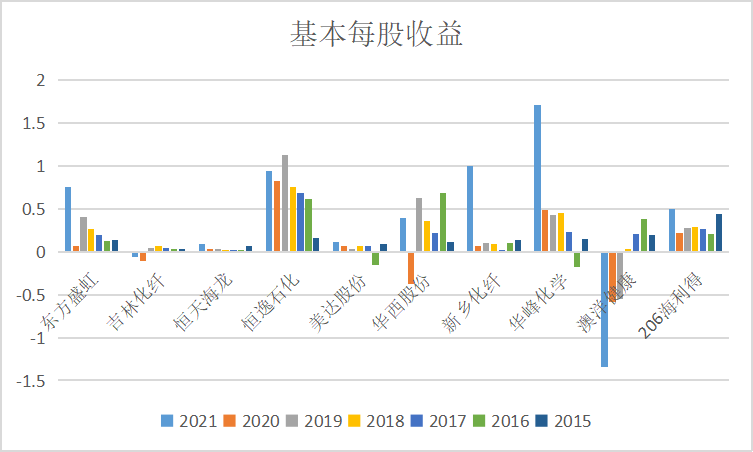 #绘制营业收入折线图
#显示中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
#显示负号
plt.rcParams['axes.unicode_minus'] = False
# fname为你下载的字体库路径,
# 注意 SourceHanSansSC-Bold.otf
# 字体的路径
fname = "C:\Windows\Fonts\方正粗黑宋简体.ttf"
zhfont1 = fm.FontProperties(fname=fname)
#设置显示图片清晰度
plt.rcParams['figure.dpi'] = 100
#绘制营业收入
fig = plt.figure(figsize=(15,20))
plt.subplots_adjust(wspace=0.3,hspace=0.6)
fig.suptitle('营业收入',fontsize=40)
ax0 = fig.add_subplot(5,2,1)
ax0.plot(dt0.loc['东方盛虹'])
ax0.set_xlabel('年 份',fontsize=14)
ax0.set_ylabel('营业收入(亿元)',fontsize=14)
ax0.set_title('东方盛虹',fontsize=14)
#绘制营业收入折线图
#显示中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
#显示负号
plt.rcParams['axes.unicode_minus'] = False
# fname为你下载的字体库路径,
# 注意 SourceHanSansSC-Bold.otf
# 字体的路径
fname = "C:\Windows\Fonts\方正粗黑宋简体.ttf"
zhfont1 = fm.FontProperties(fname=fname)
#设置显示图片清晰度
plt.rcParams['figure.dpi'] = 100
#绘制营业收入
fig = plt.figure(figsize=(15,20))
plt.subplots_adjust(wspace=0.3,hspace=0.6)
fig.suptitle('营业收入',fontsize=40)
ax0 = fig.add_subplot(5,2,1)
ax0.plot(dt0.loc['东方盛虹'])
ax0.set_xlabel('年 份',fontsize=14)
ax0.set_ylabel('营业收入(亿元)',fontsize=14)
ax0.set_title('东方盛虹',fontsize=14)
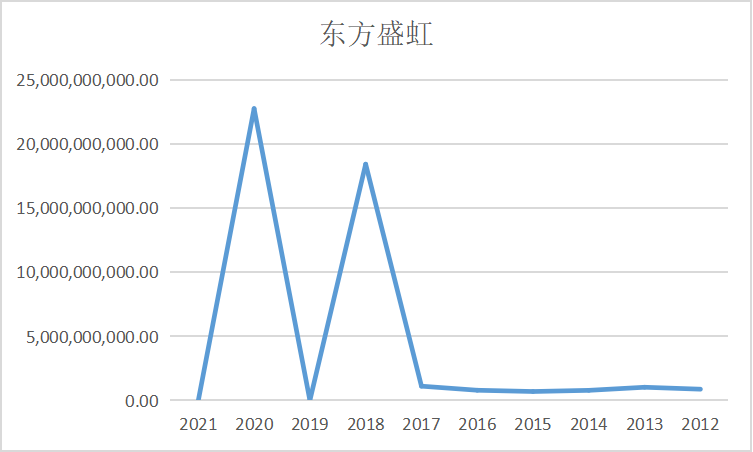 ax1 = fig.add_subplot(5,2,2)
ax1.plot(dt1.loc['吉林化纤'])
ax1.set_xlabel('年 份',fontsize=14)
ax1.set_ylabel('营业收入(亿元)',fontsize=14)
ax1.set_title('吉林化纤',fontsize=14)
ax1 = fig.add_subplot(5,2,2)
ax1.plot(dt1.loc['吉林化纤'])
ax1.set_xlabel('年 份',fontsize=14)
ax1.set_ylabel('营业收入(亿元)',fontsize=14)
ax1.set_title('吉林化纤',fontsize=14)
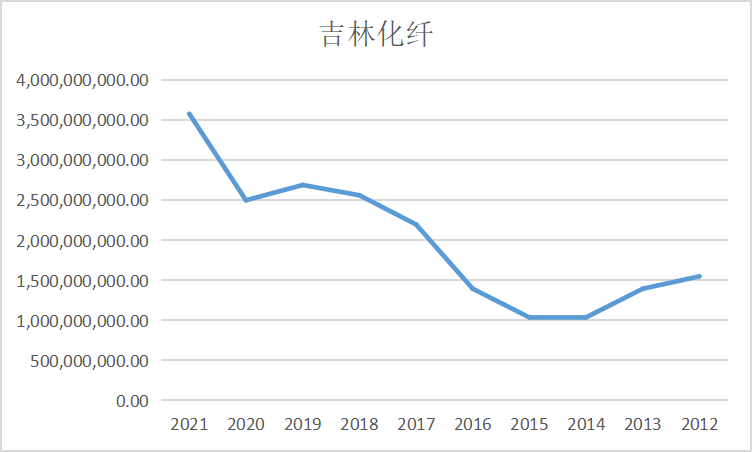 ax2 = fig.add_subplot(5,2,3)
ax2.plot(dt2.loc['恒天海龙'])
ax2.set_xlabel('年 份',fontsize=14)
ax2.set_ylabel('营业收入(亿元)',fontsize=14)
ax2.set_title('恒天海龙',fontsize=14)
ax2 = fig.add_subplot(5,2,3)
ax2.plot(dt2.loc['恒天海龙'])
ax2.set_xlabel('年 份',fontsize=14)
ax2.set_ylabel('营业收入(亿元)',fontsize=14)
ax2.set_title('恒天海龙',fontsize=14)
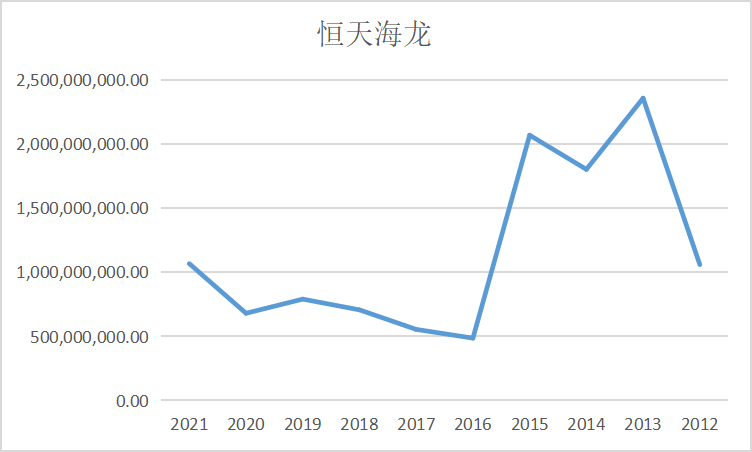 ax3 = fig.add_subplot(5,2,4)
ax3.plot(dt3.loc['恒逸石化'])
ax3.set_xlabel('年 份',fontsize=14)
ax3.set_ylabel('营业收入(亿元)',fontsize=14)
ax3.set_title('恒逸石化',fontsize=14)
ax3 = fig.add_subplot(5,2,4)
ax3.plot(dt3.loc['恒逸石化'])
ax3.set_xlabel('年 份',fontsize=14)
ax3.set_ylabel('营业收入(亿元)',fontsize=14)
ax3.set_title('恒逸石化',fontsize=14)
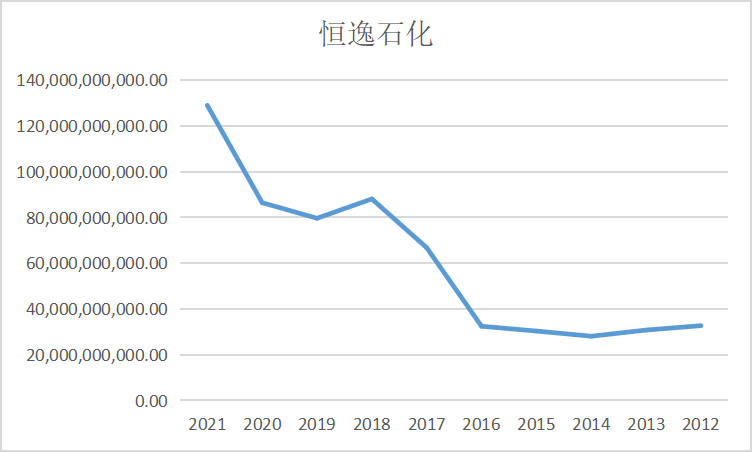 ax4 = fig.add_subplot(5,2,5)
ax4.plot(dt4.loc['美达股份'])
ax4.set_xlabel('年 份',fontsize=14)
ax4.set_ylabel('营业收入(亿元)',fontsize=14)
ax4.set_title('美达股份',fontsize=14)
ax4 = fig.add_subplot(5,2,5)
ax4.plot(dt4.loc['美达股份'])
ax4.set_xlabel('年 份',fontsize=14)
ax4.set_ylabel('营业收入(亿元)',fontsize=14)
ax4.set_title('美达股份',fontsize=14)
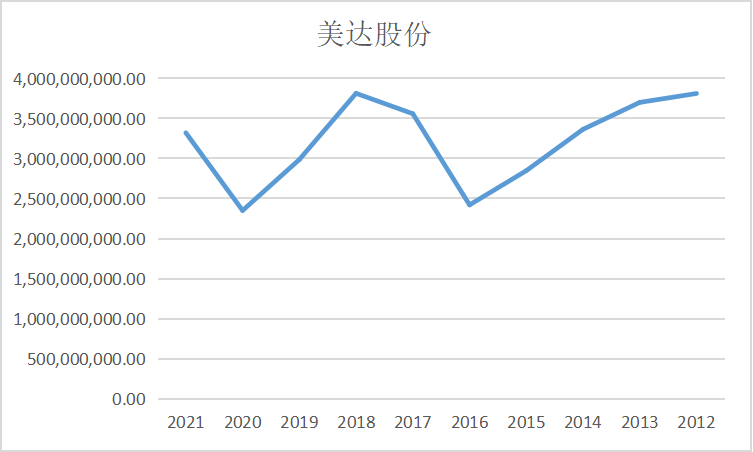 ax5 = fig.add_subplot(5,2,6)
ax5.plot(dt5.loc['华西股份'])
ax5.set_xlabel('年 份',fontsize=14)
ax5.set_ylabel('营业收入(亿元)',fontsize=14)
ax5.set_title('华西股份',fontsize=14)
ax5 = fig.add_subplot(5,2,6)
ax5.plot(dt5.loc['华西股份'])
ax5.set_xlabel('年 份',fontsize=14)
ax5.set_ylabel('营业收入(亿元)',fontsize=14)
ax5.set_title('华西股份',fontsize=14)
 ax6 = fig.add_subplot(5,2,7)
ax6.plot(dt6.loc['新乡化纤'])
ax6.set_xlabel('年 份',fontsize=14)
ax6.set_ylabel('营业收入(亿元)',fontsize=14)
ax6.set_title('新乡化纤',fontsize=14)
ax6 = fig.add_subplot(5,2,7)
ax6.plot(dt6.loc['新乡化纤'])
ax6.set_xlabel('年 份',fontsize=14)
ax6.set_ylabel('营业收入(亿元)',fontsize=14)
ax6.set_title('新乡化纤',fontsize=14)
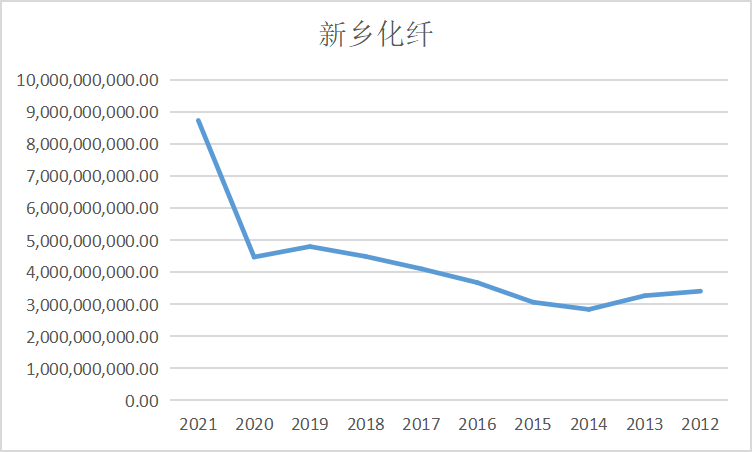 ax7 = fig.add_subplot(5,2,8)
ax7.plot(dt7.loc['华峰化学'])
ax7.set_xlabel('年 份',fontsize=14)
ax7.set_ylabel('营业收入(亿元)',fontsize=14)
ax7.set_title('华峰化学',fontsize=14)
ax7 = fig.add_subplot(5,2,8)
ax7.plot(dt7.loc['华峰化学'])
ax7.set_xlabel('年 份',fontsize=14)
ax7.set_ylabel('营业收入(亿元)',fontsize=14)
ax7.set_title('华峰化学',fontsize=14)
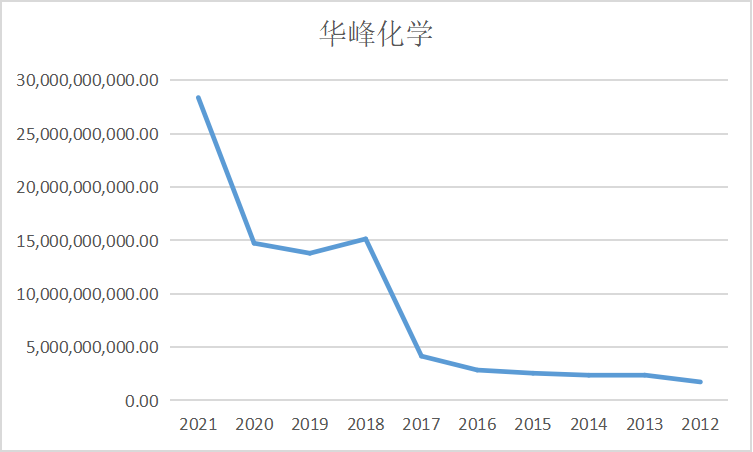 ax8 = fig.add_subplot(5,2,9)
ax8.plot(dt8.loc['澳洋健康'])
ax8.set_xlabel('年 份',fontsize=14)
ax8.set_ylabel('营业收入(亿元)',fontsize=14)
ax8.set_title('澳洋健康',fontsize=14)
ax8 = fig.add_subplot(5,2,9)
ax8.plot(dt8.loc['澳洋健康'])
ax8.set_xlabel('年 份',fontsize=14)
ax8.set_ylabel('营业收入(亿元)',fontsize=14)
ax8.set_title('澳洋健康',fontsize=14)
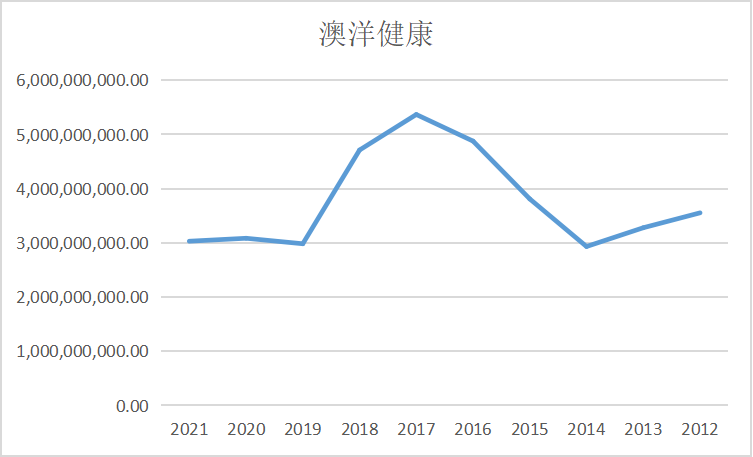 ax9 = fig.add_subplot(5,2,10)
ax9.plot(dt9.loc['海利得'])
ax9.set_xlabel('年 份',fontsize=14)
ax9.set_ylabel('营业收入(亿元)',fontsize=14)
ax9.set_title('海利得',fontsize=14)
plt.show()
ax9 = fig.add_subplot(5,2,10)
ax9.plot(dt9.loc['海利得'])
ax9.set_xlabel('年 份',fontsize=14)
ax9.set_ylabel('营业收入(亿元)',fontsize=14)
ax9.set_title('海利得',fontsize=14)
plt.show()
 #读取基本每股收益数据
dt_0 = pd.read_csv('东方盛虹每股收益.csv',encoding='utf-8')
dt_0 = dt_0.rename(columns={'Unnamed: 0':'Data'})
dt_0 = dt_0.set_index('Data')
#删除重复列
del dt_0['2020 年.1']
dt_0.loc['东方盛虹'] = dt_0.loc['东方盛虹'].astype(float)
dt_1 = pd.read_csv('吉林化纤每股收益.csv',encoding='utf-8')
dt_1 = dt_1.rename(columns={'Unnamed: 0':'Data'})
dt_1 = dt_1.set_index('Data')
dt_1.loc['吉林化纤'] = dt_1.loc['吉林化纤'].astype(float)
dt_2 = pd.read_csv('恒天海龙每股收益.csv',encoding='utf-8')
dt_2 = dt_2.rename(columns={'Unnamed: 0':'Data'})
dt_2 = dt_2.set_index('Data')
dt_2.loc['恒天海龙'] = dt_2.loc['恒天海龙'].astype(float)
dt_3 = pd.read_csv('恒逸石化每股收益.csv',encoding='utf-8')
dt_3 = dt_3.rename(columns={'Unnamed: 0':'Data'})
dt_3 = dt_3.set_index('Data')
dt_3.loc['恒逸石化'] = dt_3.loc['恒逸石化'].astype(float)
dt_4 = pd.read_csv('美达股份每股收益.csv',encoding='utf-8')
dt_4 = dt_4.rename(columns={'Unnamed: 0':'Data'})
dt_4 = dt_4.set_index('Data')
dt_4 = dt_4.set_index('Data')
dt_4.loc['美达股份'] = dt_4.loc['美达股份'].astype(float)
dt_5 = pd.read_csv('华西股份每股收益.csv',encoding='utf-8')
dt_5 = dt_5.rename(columns={'Unnamed: 0':'Data'})
dt_5 = dt_5.set_index('Data')
dt_5.loc['华西股份'] = dt_5.loc['华西股份'].astype(float)
dt_6 = pd.read_csv('新乡化纤每股收益.csv',encoding='utf-8')
dt_6 = dt_6.rename(columns={'Unnamed: 0':'Data'})
dt_6 = dt_6.set_index('Data')
dt_6.loc['新乡化纤'] = dt_6.loc['新乡化纤'].astype(float)
dt_7 = pd.read_csv('华峰化学每股收益.csv',encoding='utf-8')
dt_7 = dt_7.rename(columns={'Unnamed: 0':'Data'})
dt_7 = dt_7.set_index('Data')
dt_7.loc['华峰化学'] = dt_7.loc['华峰化学'].astype(float)
dt_8 = pd.read_csv('澳洋健康每股收益.csv',encoding='utf-8')
dt_8 = dt_8.rename(columns={'Unnamed: 0':'Data'})
dt_8 = dt_8.set_index('Data')
del dt_8['2021 年.1']
dt_8.loc['澳洋健康'] = dt_8.loc['澳洋健康'].astype(float)
dt_9 = pd.read_csv('海利得每股收益.csv',encoding='utf-8')
dt_9 = dt_9.rename(columns={'Unnamed: 0':'Data'})
dt_9 = dt_9.set_index('Data')
dt_9.loc['海利得'] = dt_9.loc['海利得'].astype(float)
#绘制基本每股收益
fig = plt.figure(figsize=(15,20))
plt.subplots_adjust(wspace=0.3,hspace=0.6)
fig.suptitle('基本每股收益',fontsize=30)
ax0 = fig.add_subplot(5,2,1)
ax0.plot(dt_0.loc['东方盛虹'])
ax0.set_xlabel('年 份',fontsize=14)
ax0.set_ylabel('基本每股收益',fontsize=14)
ax0.set_title('东方盛虹',fontsize=14)
#读取基本每股收益数据
dt_0 = pd.read_csv('东方盛虹每股收益.csv',encoding='utf-8')
dt_0 = dt_0.rename(columns={'Unnamed: 0':'Data'})
dt_0 = dt_0.set_index('Data')
#删除重复列
del dt_0['2020 年.1']
dt_0.loc['东方盛虹'] = dt_0.loc['东方盛虹'].astype(float)
dt_1 = pd.read_csv('吉林化纤每股收益.csv',encoding='utf-8')
dt_1 = dt_1.rename(columns={'Unnamed: 0':'Data'})
dt_1 = dt_1.set_index('Data')
dt_1.loc['吉林化纤'] = dt_1.loc['吉林化纤'].astype(float)
dt_2 = pd.read_csv('恒天海龙每股收益.csv',encoding='utf-8')
dt_2 = dt_2.rename(columns={'Unnamed: 0':'Data'})
dt_2 = dt_2.set_index('Data')
dt_2.loc['恒天海龙'] = dt_2.loc['恒天海龙'].astype(float)
dt_3 = pd.read_csv('恒逸石化每股收益.csv',encoding='utf-8')
dt_3 = dt_3.rename(columns={'Unnamed: 0':'Data'})
dt_3 = dt_3.set_index('Data')
dt_3.loc['恒逸石化'] = dt_3.loc['恒逸石化'].astype(float)
dt_4 = pd.read_csv('美达股份每股收益.csv',encoding='utf-8')
dt_4 = dt_4.rename(columns={'Unnamed: 0':'Data'})
dt_4 = dt_4.set_index('Data')
dt_4 = dt_4.set_index('Data')
dt_4.loc['美达股份'] = dt_4.loc['美达股份'].astype(float)
dt_5 = pd.read_csv('华西股份每股收益.csv',encoding='utf-8')
dt_5 = dt_5.rename(columns={'Unnamed: 0':'Data'})
dt_5 = dt_5.set_index('Data')
dt_5.loc['华西股份'] = dt_5.loc['华西股份'].astype(float)
dt_6 = pd.read_csv('新乡化纤每股收益.csv',encoding='utf-8')
dt_6 = dt_6.rename(columns={'Unnamed: 0':'Data'})
dt_6 = dt_6.set_index('Data')
dt_6.loc['新乡化纤'] = dt_6.loc['新乡化纤'].astype(float)
dt_7 = pd.read_csv('华峰化学每股收益.csv',encoding='utf-8')
dt_7 = dt_7.rename(columns={'Unnamed: 0':'Data'})
dt_7 = dt_7.set_index('Data')
dt_7.loc['华峰化学'] = dt_7.loc['华峰化学'].astype(float)
dt_8 = pd.read_csv('澳洋健康每股收益.csv',encoding='utf-8')
dt_8 = dt_8.rename(columns={'Unnamed: 0':'Data'})
dt_8 = dt_8.set_index('Data')
del dt_8['2021 年.1']
dt_8.loc['澳洋健康'] = dt_8.loc['澳洋健康'].astype(float)
dt_9 = pd.read_csv('海利得每股收益.csv',encoding='utf-8')
dt_9 = dt_9.rename(columns={'Unnamed: 0':'Data'})
dt_9 = dt_9.set_index('Data')
dt_9.loc['海利得'] = dt_9.loc['海利得'].astype(float)
#绘制基本每股收益
fig = plt.figure(figsize=(15,20))
plt.subplots_adjust(wspace=0.3,hspace=0.6)
fig.suptitle('基本每股收益',fontsize=30)
ax0 = fig.add_subplot(5,2,1)
ax0.plot(dt_0.loc['东方盛虹'])
ax0.set_xlabel('年 份',fontsize=14)
ax0.set_ylabel('基本每股收益',fontsize=14)
ax0.set_title('东方盛虹',fontsize=14)
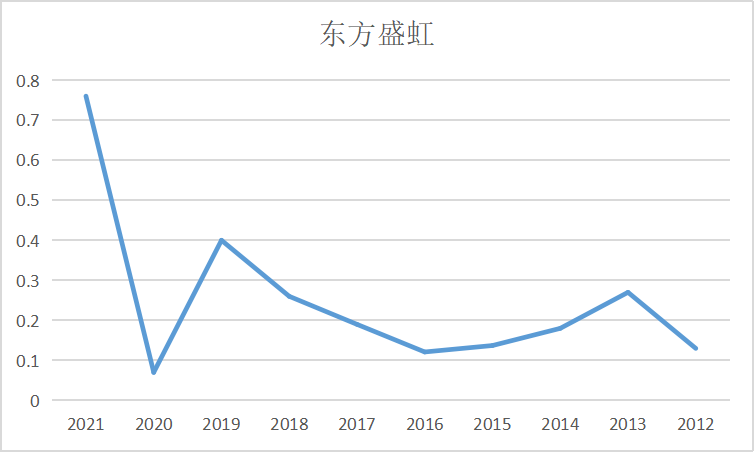 ax1 = fig.add_subplot(5,2,2)
ax1.plot(dt_1.loc['吉林化纤'])
ax1.set_xlabel('年 份',fontsize=14)
ax1.set_ylabel('基本每股收益',fontsize=14)
ax1.set_title('吉林化纤',fontsize=14)
ax1 = fig.add_subplot(5,2,2)
ax1.plot(dt_1.loc['吉林化纤'])
ax1.set_xlabel('年 份',fontsize=14)
ax1.set_ylabel('基本每股收益',fontsize=14)
ax1.set_title('吉林化纤',fontsize=14)
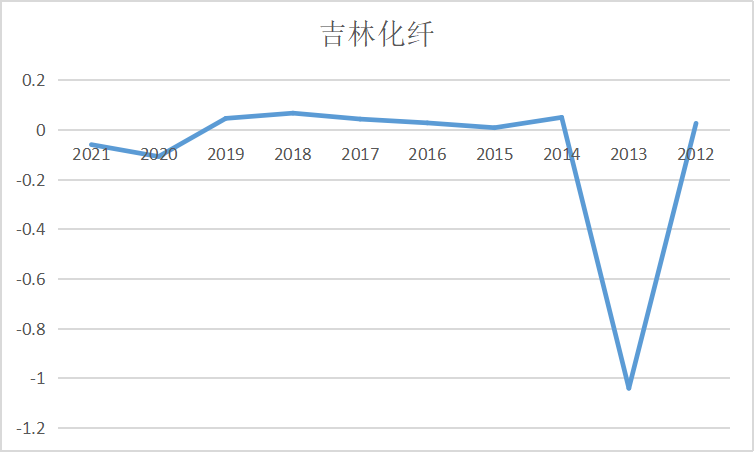 ax2 = fig.add_subplot(5,2,3)
ax2.plot(dt_2.loc['恒天海龙'])
ax2.set_xlabel('年 份',fontsize=14)
ax2.set_ylabel('基本每股收益',fontsize=14)
ax2.set_title('恒天海龙',fontsize=14)
ax2 = fig.add_subplot(5,2,3)
ax2.plot(dt_2.loc['恒天海龙'])
ax2.set_xlabel('年 份',fontsize=14)
ax2.set_ylabel('基本每股收益',fontsize=14)
ax2.set_title('恒天海龙',fontsize=14)
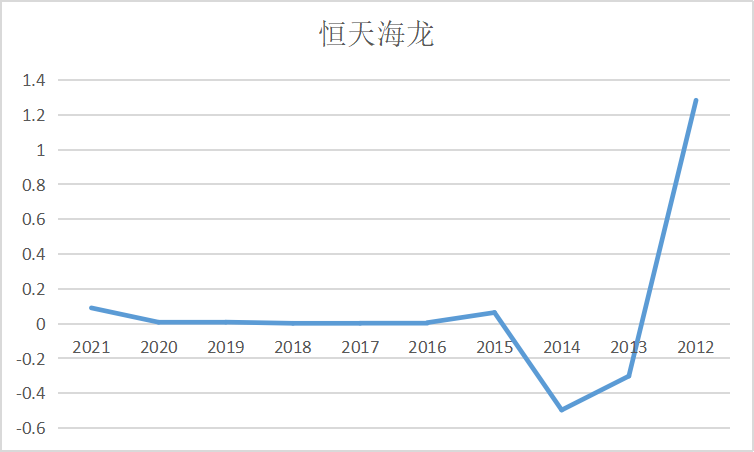 ax3 = fig.add_subplot(5,2,4)
ax3.plot(dt_3.loc['恒逸石化'])
ax3.set_xlabel('年 份',fontsize=14)
ax3.set_ylabel('基本每股收益',fontsize=14)
ax3.set_title('恒逸石化',fontsize=14)
ax3 = fig.add_subplot(5,2,4)
ax3.plot(dt_3.loc['恒逸石化'])
ax3.set_xlabel('年 份',fontsize=14)
ax3.set_ylabel('基本每股收益',fontsize=14)
ax3.set_title('恒逸石化',fontsize=14)
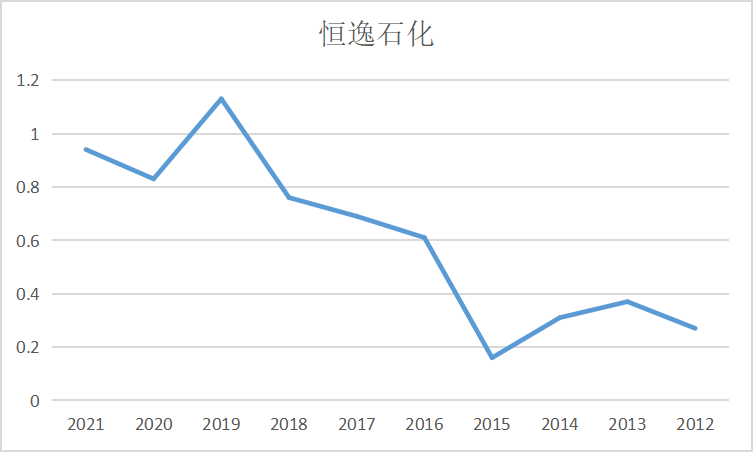 ax4 = fig.add_subplot(5,2,5)
ax4.plot(dt_4.loc['美达股份'])
ax4.set_xlabel('年 份',fontsize=14)
ax4.set_ylabel('基本每股收益',fontsize=14)
ax4.set_title('美达股份',fontsize=14)
ax4 = fig.add_subplot(5,2,5)
ax4.plot(dt_4.loc['美达股份'])
ax4.set_xlabel('年 份',fontsize=14)
ax4.set_ylabel('基本每股收益',fontsize=14)
ax4.set_title('美达股份',fontsize=14)
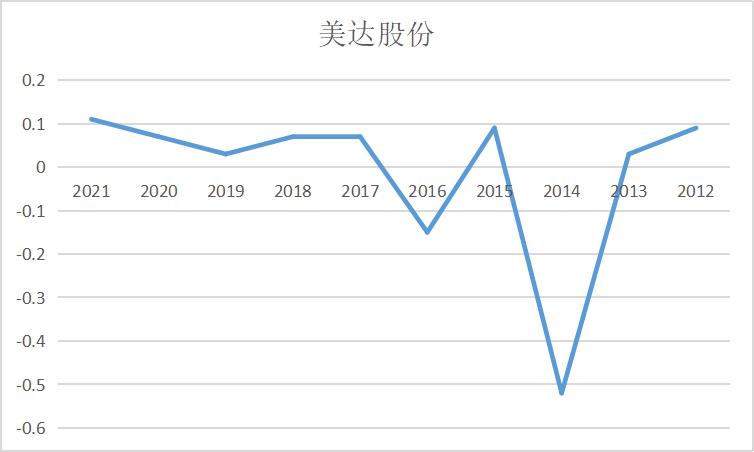 ax5 = fig.add_subplot(5,2,6)
ax5.plot(dt_5.loc['华西股份'])
ax5.set_xlabel('年 份',fontsize=14)
ax5.set_ylabel('基本每股收益',fontsize=14)
ax5.set_title('华西股份',fontsize=14)
ax5 = fig.add_subplot(5,2,6)
ax5.plot(dt_5.loc['华西股份'])
ax5.set_xlabel('年 份',fontsize=14)
ax5.set_ylabel('基本每股收益',fontsize=14)
ax5.set_title('华西股份',fontsize=14)
 ax6 = fig.add_subplot(5,2,7)
ax6.plot(dt_6.loc['新乡化纤'])
ax6.set_xlabel('年 份',fontsize=14)
ax6.set_ylabel('基本每股收益',fontsize=14)
ax6.set_title('新乡化纤',fontsize=14)
ax6 = fig.add_subplot(5,2,7)
ax6.plot(dt_6.loc['新乡化纤'])
ax6.set_xlabel('年 份',fontsize=14)
ax6.set_ylabel('基本每股收益',fontsize=14)
ax6.set_title('新乡化纤',fontsize=14)
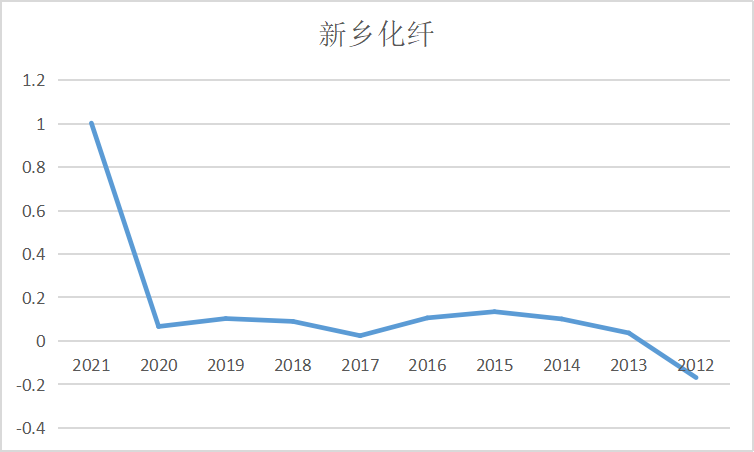 ax7 = fig.add_subplot(5,2,8)
ax7.plot(dt_7.loc['华峰化学'])
ax7.set_xlabel('年 份',fontsize=14)
ax7.set_ylabel('基本每股收益',fontsize=14)
ax7.set_title('华峰化学',fontsize=14)
ax7 = fig.add_subplot(5,2,8)
ax7.plot(dt_7.loc['华峰化学'])
ax7.set_xlabel('年 份',fontsize=14)
ax7.set_ylabel('基本每股收益',fontsize=14)
ax7.set_title('华峰化学',fontsize=14)
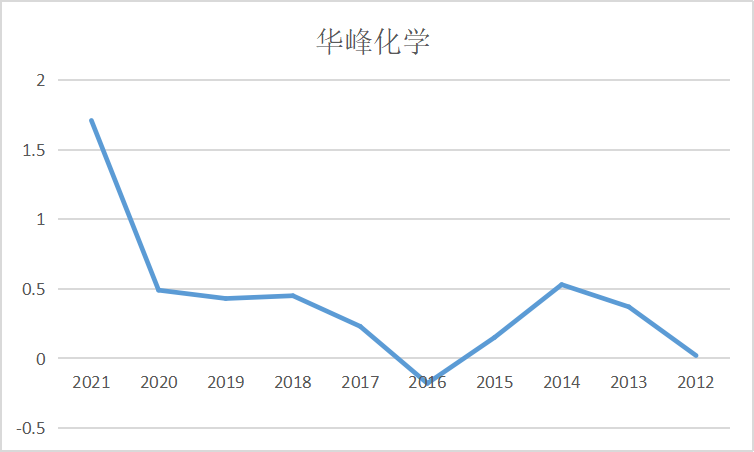 ax8 = fig.add_subplot(5,2,9)
ax8.plot(dt_8.loc['澳洋健康'])
ax8.set_xlabel('年 份',fontsize=14)
ax8.set_ylabel('基本每股收益',fontsize=14)
ax8.set_title('澳洋健康',fontsize=14)
ax8 = fig.add_subplot(5,2,9)
ax8.plot(dt_8.loc['澳洋健康'])
ax8.set_xlabel('年 份',fontsize=14)
ax8.set_ylabel('基本每股收益',fontsize=14)
ax8.set_title('澳洋健康',fontsize=14)
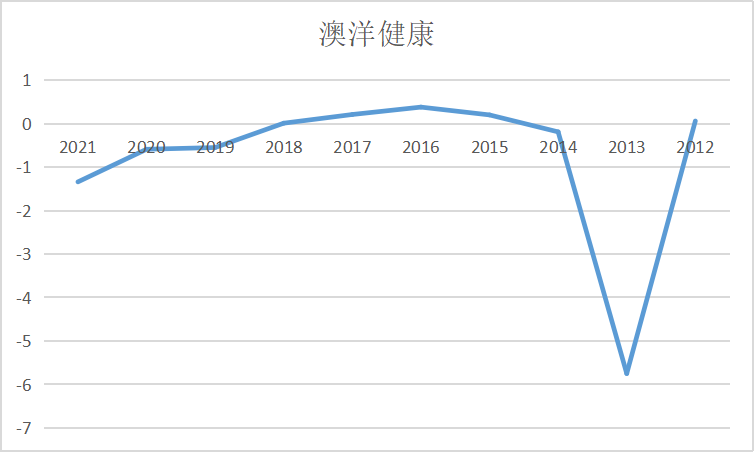 ax9 = fig.add_subplot(5,2,10)
ax9.plot(dt_9.loc['海利得'])
ax9.set_xlabel('年 份',fontsize=14)
ax9.set_ylabel('基本每股收益',fontsize=14)
ax9.set_title('海利得',fontsize=14)
ax9 = fig.add_subplot(5,2,10)
ax9.plot(dt_9.loc['海利得'])
ax9.set_xlabel('年 份',fontsize=14)
ax9.set_ylabel('基本每股收益',fontsize=14)
ax9.set_title('海利得',fontsize=14)
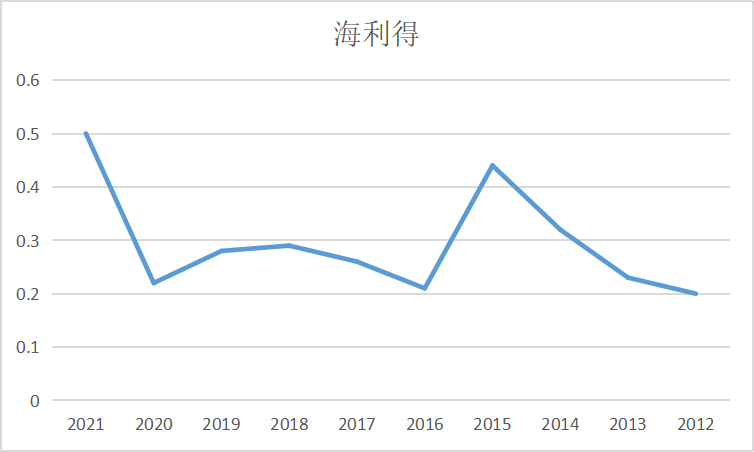 plt.show()
plt.show()
解释
从以上数据分析可知道,该行业整体的收益波动很大,在2019年受到疫情影响均出现大幅降低,然后2020年出现反弹。