import requests
import json
import os
import random
def str2dic(strs):
a = strs.strip().split('\n') #删除首尾字符 strip()
m = '{'
for i in a:
i = i.strip()
if ':' in i:
k = i.split(':')
else:
k = i.split(' ')
m += "'"+k[0].strip()+"'"+":"+"'"+k[1].strip()+"',"
m += '}'
return eval(m)
def get_json():
rand = str(random.random())
header = str2dic('''Content-Type: application/json
Host: www.szse.cn
Origin: https://www.szse.cn
Referer: https://www.szse.cn/disclosure/listed/fixed/index.html
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36 Edg/101.0.1210.39
''')
daima = '''
000059 华锦股份
000637 茂化实华
000698 沈阳化工
000723 美锦能源
000819 岳阳兴长
002778 中晟高科
300839 博汇股份
600688 上海石化
600725 云维股份
600740 山西焦化
600792 云煤能源
600997 开滦股份
601011 宝泰隆
601015 陕西黑猫
603113 金能科技
603798 康普顿
'''
daima = str2dic(daima)
stockid = str(list(daima.keys())).replace("'", '"')
i = 1
data = json.loads('{"seDate":["2012-01-01","2022-5-12"],"stock":'+stockid+ #把str转化json模式
',"channelCode":["fixed_disc"],"bigCategoryId":["010301"],"pageSize":50,"pageNum":'+str(i)+'}')
url = 'https://www.szse.cn/api/disc/announcement/annList?'+rand
index = requests.post(url, json.dumps(data), headers=header) #json.dumps转化成字符串,data是字典
count = index.json()["announceCount"] #通过json该属性得知共有多少条数据,因为只请求了1页(50条),剩余的链接需要再构造
count = count//50+1 if count%50!=0 else count//50
data_j = index.json()
for i in range(2, count+1):
url = 'https://www.szse.cn/api/disc/announcement/annList?' + rand
data = json.loads(
'{"seDate":["2012-01-01","2022-5-12"],"stock":' + stockid +
',"channelCode":["fixed_disc"],"bigCategoryId":["010301"],"pageSize":50,"pageNum":' + str(i) + '}')
data_j['data'][-1:-1] = requests.post(url, data=json.dumps(data), headers=header).json()['data']
return data_j
def get_url(data_j):
down_head = 'https://disc.szse.cn/download'
reports_url = []
all_d = data_j['data']
for report in all_d:
if '取消' in report['title'] or '摘要' in report['title']:
continue
reports_url.append((down_head+report['attachPath'], report['title'].replace('*', '')))
return reports_url
def reques_url(url):
if 'reports' not in os.listdir():
os.mkdir('reports')
path = 'reports/'+url[1]+'.pdf'
if path not in os.listdir('reports/'):
rep = requests.get(url[0])
print(url[1], rep.status_code)
with open(path, 'wb') as fp:
print('正在写入')
fp.write(rep.content)
print('写入完毕')
def main():
data_j = get_json()
reports_urls = get_url(data_j)
for url in reports_urls:
reques_url(url)
if __name__ == '__main__':
main()
import fitz
import re
import pandas as pd
import os
path = r"C:\Users\清风知朗月\OneDrive\文档\Python\reports"
os.chdir(path)
class NB():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
name = """博汇股份:2020年年度报告.pdf,
博汇股份:2021年年度报告.pdf,
高科石化:2015年年度报告.pdf,
高科石化:2016年年度报告.pdf,
高科石化:2017年年度报告.pdf,
高科石化:2018年年度报告.pdf,
高科石化:2019年年度报告.pdf,
高科石化:2020年年度报告.pdf,
华锦股份:2013年年度报告.pdf,
华锦股份:2013年年度报告(更新后).pdf,
华锦股份:2014年年度报告.pdf,
华锦股份:2016年年度报告.pdf,
华锦股份:2017年年度报告.pdf,
华锦股份:2018年年度报告.pdf,
华锦股份:2019年年度报告.pdf,
华锦股份:2020年年度报告.pdf,
华锦股份:2021年年度报告.pdf,
辽通化工:2011年年度报告.pdf,
辽通化工:2012年年度报告(更新后).pdf,
茂化实华:2011年年度报告.pdf,
茂化实华:2012年年度报告.pdf,
茂化实华:2013年年度报告.pdf,
茂化实华:2014年年度报告.pdf,
茂化实华:2015年年度报告.pdf,
茂化实华:2016年年度报告.pdf,
茂化实华:2017年年度报告.pdf,
茂化实华:2018年年度报告.pdf,
茂化实华:2019年年度报告.pdf,
茂化实华:2020年年度报告.pdf,
茂化实华:2021年年度报告.pdf,
美锦能源:2011年年度报告.pdf,
美锦能源:2012年年度报告.pdf,
美锦能源:2013年年度报告.pdf,
美锦能源:2014年年度报告.pdf,
美锦能源:2015年年度报告(更新后).pdf,
美锦能源:2016年年度报告(更新后).pdf,
美锦能源:2017年年度报告(更新后).pdf,
美锦能源:2018年年度报告.pdf,
美锦能源:2019年年度报告.pdf,
美锦能源:2020年年度报告.pdf,
美锦能源:2021年年度报告.pdf,
沈阳化工:2011年年度报告.pdf,
沈阳化工:2012年年度报告.pdf,
沈阳化工:2013年年度报告.pdf,
沈阳化工:2014年年度报告.pdf,
沈阳化工:2015年年度报告(更新后).pdf,
沈阳化工:2016年年度报告.pdf,
沈阳化工:2017年年度报告.pdf,
沈阳化工:2018年年度报告.pdf,
沈阳化工:2019年年度报告.pdf,
沈阳化工:2020年年度报告.pdf,
沈阳化工:2021年年度报告.pdf,
岳阳兴长:2011年年度报告.pdf,
岳阳兴长:2012年年度报告.pdf,
岳阳兴长:2013年年度报告.pdf,
岳阳兴长:2014年年度报告.pdf,
岳阳兴长:2015年年度报告.pdf,
岳阳兴长:2016年年度报告.pdf,
岳阳兴长:2017年年度报告.pdf,
岳阳兴长:2018年年度报告.pdf,
岳阳兴长:2019年年度报告.pdf,
岳阳兴长:2020年年度报告.pdf,
岳阳兴长:2021年年度报告.pdf,
中晟高科:2021年年度报告.pdf,
ST华锦:2015年年度报告(更新后).pdf
"""
name_list = name.split(",")
name_test = []
list_res = []
for item in name_list:
name_test.append(item.replace("\n",""))
for i in range(len(name_test)):
doc = fitz.open('%s'%(name_test[i]))
text=""
for j in range(16):
page = doc[j]
text += page.get_text()
p_year=re.compile('.*?(\d{4}) .*?年度报告.*?')
year = p_year.findall(text)[0]
sent = name_test[i]
sent_1 = sent.split(":")
name = sent_1[0]
p_rev = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
p_eps = re.compile('(?<=\n)基本每股收益(元/?/?\n?股)\s?\n?([-\d+,.]*)\s?\n?')
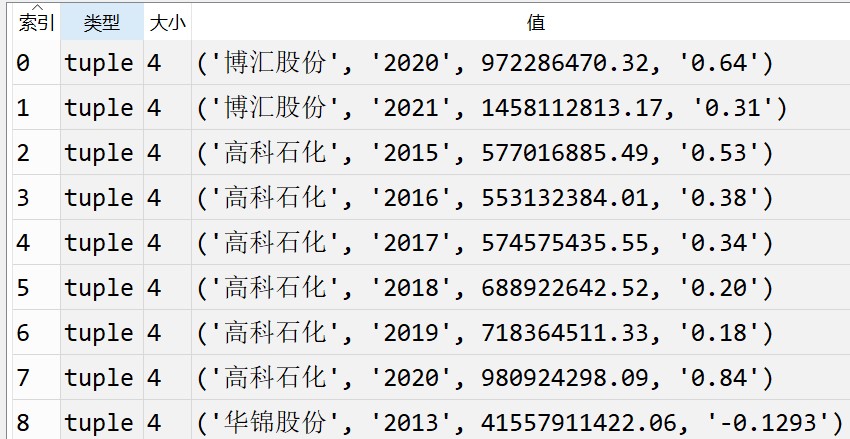
revenue = float(p_rev.search(text).group(1).replace(',',''))
eps = p_eps.search(text).group(1)
tuple_res = (name,year,revenue,eps)
list_res.append(tuple_res)
df = pd.DataFrame(list_res)
df = pd.DataFrame(list_res)
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.font_manager as fm
fname = "C:\Windows\Fonts\STFANGSO.TTF"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams["figure.dpi"] = 300
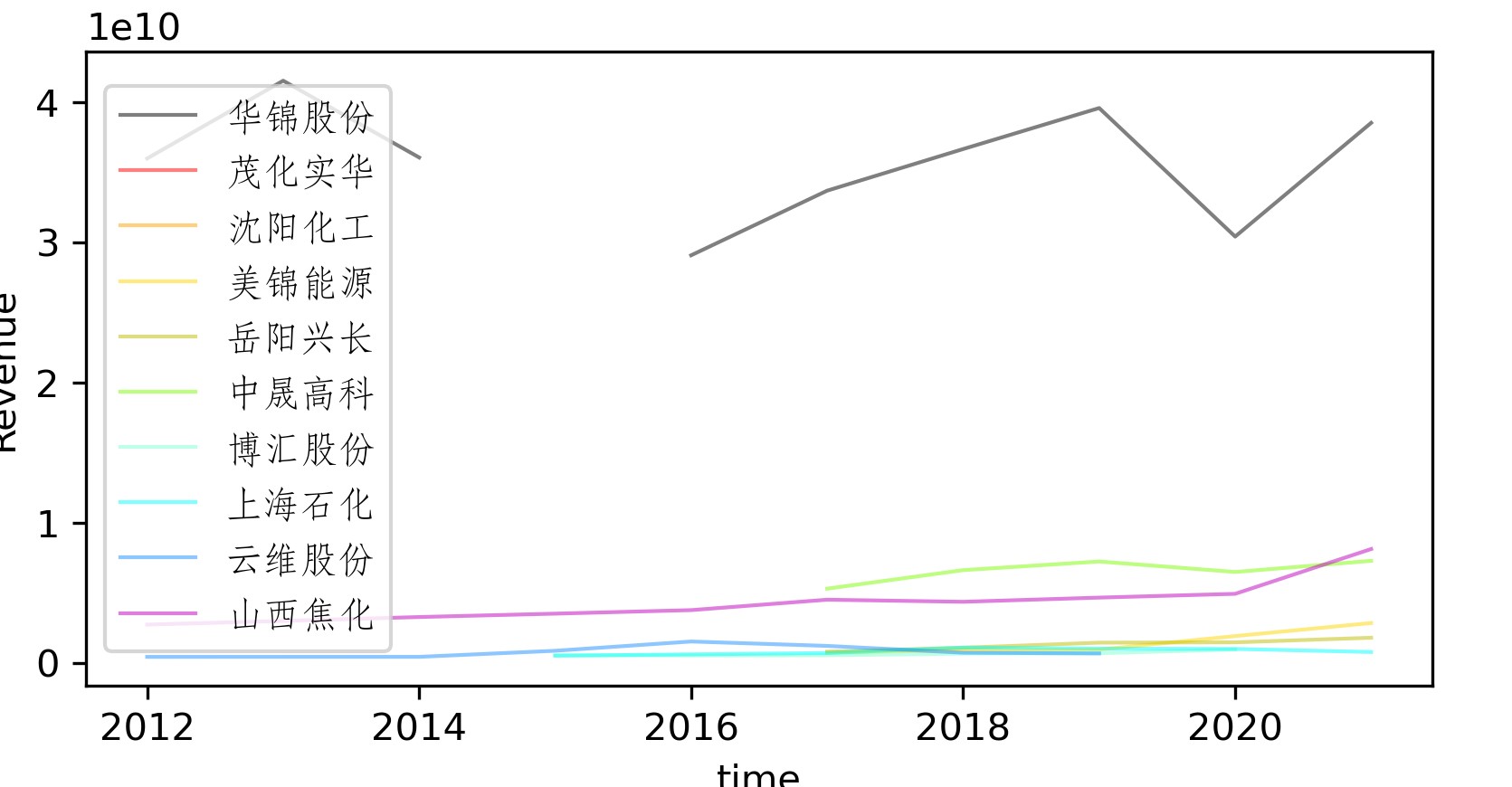
x_axis_data = [2012,2013,2014,2015,2016,2017,2018,2019,2020,2021]
y_axis_data1 = [3.60087e+10,4.15579e+10,3.60820e+10,None,2.91039e+10,3.37137e+10,3.66832e+10,3.96083e+10,3.04374e+10,3.85523e+10]
y_axis_data2 = [None,None,None,None,None,None,None,None,None,5.80792e+08]
y_axis_data3 = [None,None,None,None,None,None,None,None,None,1.92496e+09]
y_axis_data4 = [None,None,None,None,None,7.47831e+08,9.46776e+08,9.78069e+08,1.94066e+09,2.87128e+09]
y_axis_data5 = [None,None,None,None,None,8.26468e+08,1.11027e+09,1.47144e+09,1.49362e+09,1.82366e+09]
y_axis_data6 = [None,None,None,None,None,5.32345e+09,6.64539e+09,7.26079e+09,6.51343e+09,7.30961e+09]
y_axis_data7 = [None,None,None,5.77016e+08,5.53132e+08,5.74575e+08,6.88922e+08,7.18364e+08,9.80924e+08,None]
y_axis_data8 = [None,None,None,5.37178e+08,6.40466e+08,7.32428e+08,1.12403e+09,1.04554e+09,1.02427e+09,8.03661e+08]
y_axis_data9 = [4.56898e+08,4.58932e+08,4.60006e+08,8.91661e+08,1.55398e+09,1.24003e+09,7.54832e+08,7.02153e+08,None,5.06311e+08]
y_axis_data10 = [2.75911e+09,3.02236e+09,3.29974e+09,3.54061e+09,3.79234e+09,4.53632e+09,4.3861e+09,4.68521e+09,4.95463e+09,8.15081e+09]
plt.plot(x_axis_data, y_axis_data1, 'black', alpha=0.5, linewidth=1, label='华锦股份')
plt.plot(x_axis_data, y_axis_data2, 'red', alpha=0.5, linewidth=1, label='茂化实华')
plt.plot(x_axis_data, y_axis_data3, 'orange', alpha=0.5, linewidth=1, label='沈阳化工')
plt.plot(x_axis_data, y_axis_data4, 'gold', alpha=0.5, linewidth=1, label='美锦能源')
plt.plot(x_axis_data, y_axis_data5, 'y', alpha=0.5, linewidth=1, label='岳阳兴长')
plt.plot(x_axis_data, y_axis_data6, 'lawngreen', alpha=0.5, linewidth=1, label='中晟高科')
plt.plot(x_axis_data, y_axis_data7, 'aquamarine', alpha=0.5, linewidth=1, label='博汇股份')
plt.plot(x_axis_data, y_axis_data8, 'cyan', alpha=0.5, linewidth=1, label='上海石化')
plt.plot(x_axis_data, y_axis_data9, 'dodgerblue', alpha=0.5, linewidth=1, label='云维股份')
plt.plot(x_axis_data, y_axis_data10, 'm', alpha=0.5, linewidth=1, label='山西焦化')
plt.legend(prop = zhfont1)
plt.xlabel('time')
plt.ylabel('Revenue')
plt.show()
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.font_manager as fm
fname = "C:\Windows\Fonts\STFANGSO.TTF"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams["figure.dpi"] = 300
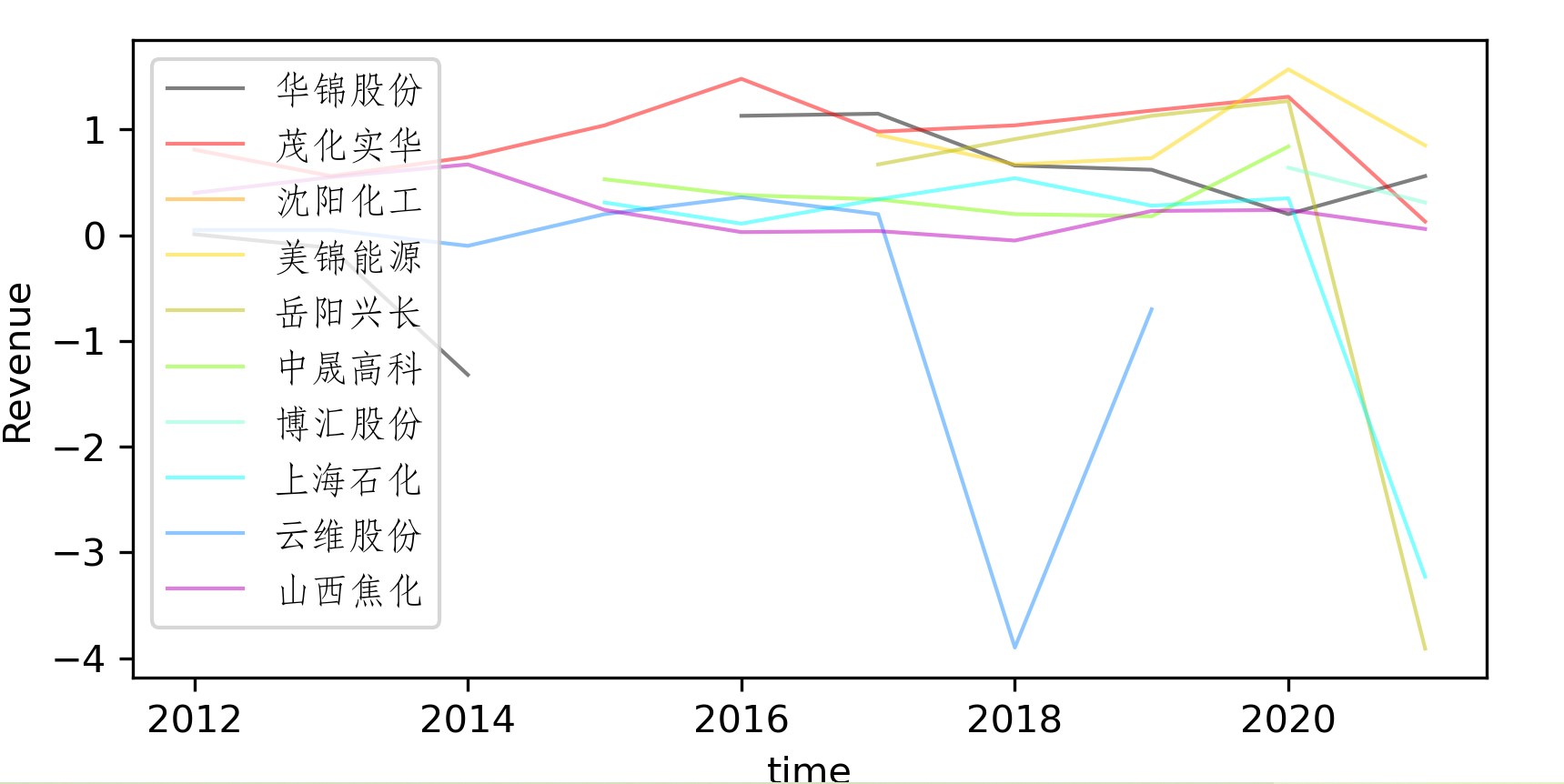
y_axis_data1 = [0.01,-0.12,-1.32,None,1.13,1.15,0.66,0.62,0.20,0.56,]
y_axis_data2 = [0.81,0.56,0.74,1.04,1.48,0.98,1.04,1.18,1.31,0.13]
y_axis_data3 = [None,None,None,None,None,None,None,None,None,0.11]
y_axis_data4 = [None,None,None,None,None,0.95,0.67,0.73,1.57,0.85]
y_axis_data5 = [None,None,None,None,None,0.67,0.91,1.13,1.27,-3.91]
y_axis_data6 = [None,None,None,0.53,0.38,0.34,0.20,0.18,0.84,None]
y_axis_data7 = [None,None,None,None,None,None,None,None,0.64,0.31]
y_axis_data8 = [None,None,None,0.31,0.11,0.34,0.54,0.28,0.35,-3.23]
y_axis_data9 = [0.05,0.05,-0.10,0.20,0.36,0.20,-3.90,-0.7,None,0.16]
y_axis_data10 = [0.40,0.55,0.67,0.24,0.03,0.04,-0.05,0.23,0.24,0.06]
plt.plot(x_axis_data, y_axis_data1, 'black', alpha=0.5, linewidth=1, label='华锦股份')
plt.plot(x_axis_data, y_axis_data2, 'red', alpha=0.5, linewidth=1, label='茂化实华')
plt.plot(x_axis_data, y_axis_data3, 'orange', alpha=0.5, linewidth=1, label='沈阳化工')
plt.plot(x_axis_data, y_axis_data4, 'gold', alpha=0.5, linewidth=1, label='美锦能源')
plt.plot(x_axis_data, y_axis_data5, 'y', alpha=0.5, linewidth=1, label='岳阳兴长')
plt.plot(x_axis_data, y_axis_data6, 'lawngreen', alpha=0.5, linewidth=1, label='中晟高科')
plt.plot(x_axis_data, y_axis_data7, 'aquamarine', alpha=0.5, linewidth=1, label='博汇股份')
plt.plot(x_axis_data, y_axis_data8, 'cyan', alpha=0.5, linewidth=1, label='上海石化')
plt.plot(x_axis_data, y_axis_data9, 'dodgerblue', alpha=0.5, linewidth=1, label='云维股份')
plt.plot(x_axis_data, y_axis_data10, 'm', alpha=0.5, linewidth=1, label='山西焦化')
plt.legend(prop = zhfont1)
plt.xlabel('time')
plt.ylabel('Revenue')
plt.show()
这次作业对我来说是非常困难了,通过此次作业,我深刻的认识到了"纠错"能力的重要性。但同时,通过对该门课程的学习, 我对爬虫、编程有了一定的认识,它能够使很多复杂的东西简单化。最后,希望通过日后的努力和练习,编程的能力越来越好。