彭广威的实验报告
彭广威的实验报告
爬取报表
代码
import requests
import json
import os
import random
# data headers url构造
def str2dic(strs):
a = strs.strip().split('\n') #删除首尾字符 strip()
m = '{'
for i in a:
i = i.strip()
if ':' in i:
k = i.split(':')
else:
k = i.split(' ')
m += "'"+k[0].strip()+"'"+":"+"'"+k[1].strip()+"',"
m += '}'
return eval(m)
def get_json():
rand = str(random.random())
header = str2dic('''Content-Type: application/json
Host: www.szse.cn
Origin: https://www.szse.cn
Referer: https://www.szse.cn/disclosure/listed/fixed/index.html
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36 Edg/101.0.1210.39
''')
daima = '''
000663 永安林业
002489 浙江永强
002572 索菲亚
002751 易尚展示
002853 皮阿诺
300616 尚品宅配
300729 乐歌股份
300749 顶固集创
301061 匠心家居
603008 喜临门
603180 金牌厨柜
603208 江山欧派
603313 梦百合
603326 我乐家居
603389 亚振家居
603600 永艺股份
603610 麒盛科技
603661 恒林股份
603709 中源家居
603801 志邦家居
603816 顾家家居
603818 曲美家居
603833 欧派家居
603898 好莱客
'''
daima = str2dic(daima)
stockid = str(list(daima.keys())).replace("'", '"')
i = 1
data = json.loads('{"seDate":["2012-01-01","2022-5-12"],"stock":'+stockid+ #把str转化json模式
',"channelCode":["fixed_disc"],"bigCategoryId":["010301"],"pageSize":50,"pageNum":'+str(i)+'}')
url = 'https://www.szse.cn/api/disc/announcement/annList?'+rand
# request向主页请求,获得筛选数据信息
index = requests.post(url, json.dumps(data), headers=header) #json.dumps转化成字符串,data是字典
count = index.json()["announceCount"] #通过json该属性得知共有多少条数据,因为只请求了1页(50条),剩余的链接需要再构造
count = count//50+1 if count%50!=0 else count//50
data_j = index.json()
for i in range(2, count+1):
url = 'https://www.szse.cn/api/disc/announcement/annList?' + rand
data = json.loads(
'{"seDate":["2012-01-01","2022-5-12"],"stock":' + stockid +
',"channelCode":["fixed_disc"],"bigCategoryId":["010301"],"pageSize":50,"pageNum":' + str(i) + '}')
# 将得到的后续页数数据插入第一页的数据,方便统一处理
data_j['data'][-1:-1] = requests.post(url, data=json.dumps(data), headers=header).json()['data']
return data_j
# 构造下载链接
#该方法从json中提取所有年报pdf的链接
def get_url(data_j):
down_head = 'https://disc.szse.cn/download'
reports_url = []
all_d = data_j['data']
for report in all_d:
# 摘要和修改前的年报不提取
if '取消' in report['title'] or '摘要' in report['title']:
continue
# 文件名不能出现*号
reports_url.append((down_head+report['attachPath'], report['title'].replace('*', '')))
return reports_url
def reques_url(url):
# 年报链接挨个请求,并写入文件
if 'reports' not in os.listdir():
os.mkdir('reports')
path = 'reports/'+url[1]+'.pdf'
# 判断语句是为了支持断点续传
if path not in os.listdir('reports/'):
rep = requests.get(url[0])
print(url[1], rep.status_code)
with open(path, 'wb') as fp:
print('正在写入')
fp.write(rep.content)
print('写入完毕')
def main():
data_j = get_json()
reports_urls = get_url(data_j)
for url in reports_urls:
reques_url(url)
if __name__ == '__main__':
main()
结果
解释
用模拟发送下载包的形式爬取
获取营业数据
代码
import fitz
import re
import pandas as pd
import os
path = r"C:\Users\ASUS\Documents\Python Scripts\Spyder\reports"
os.chdir(path)
class NB():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
name = """顶固集创:2018年年度报告.pdf,
顶固集创:2019年年度报告.pdf,
顶固集创:2020年年度报告.pdf,
顶固集创:2021年年度报告.pdf,
匠心家居:2021年年度报告全文(更新后).pdf,
匠心家居:2021年年度报告全文.pdf,
乐歌股份:2017年年度报告.pdf,
乐歌股份:2018年年度报告.pdf,
乐歌股份:2019年年度报告(更新后).pdf,
乐歌股份:2020年年度报告.pdf,
乐歌股份:2021年年度报告.pdf,
皮阿诺:2017年年度报告.pdf,
皮阿诺:2018年年度报告.pdf,
皮阿诺:2019年年度报告(更新后).pdf,
皮阿诺:2020年年度报告.pdf,
皮阿诺:2021年年度报告.pdf,
尚品宅配:2017年年度报告.pdf,
尚品宅配:2018年年度报告.pdf,
尚品宅配:2019年年度报告.pdf,
尚品宅配:2020年年度报告.pdf,
尚品宅配:2021年年度报告.pdf,
索菲亚:2011年年度报告.pdf,
索菲亚:2012年年度报告.pdf,
索菲亚:2013年年度报告.pdf,
索菲亚:2014年年度报告.pdf,
索菲亚:2015年年度报告.pdf,
索菲亚:2016年年度报告.pdf,
索菲亚:2017年年度报告.pdf,
索菲亚:2018年年度报告.pdf,
索菲亚:2019年年度报告.pdf,
索菲亚:2020年年度报告.pdf,
索菲亚:2021年年度报告.pdf,
易尚展示:2015年年度报告.pdf,
易尚展示:2016年年度报告.pdf,
易尚展示:2017年年度报告.pdf,
易尚展示:2018年年度报告.pdf,
易尚展示:2019年年度报告.pdf,
易尚展示:2020年年度报告.pdf,
易尚展示:2021年年度报告.pdf,
永安林业:2010年年度报告(更新后).pdf,
永安林业:2011年年度报告.pdf,
永安林业:2012年年度报告.pdf,
永安林业:2013年年度报告.pdf,
永安林业:2014年年度报告.pdf,
永安林业:2015年年度报告(更新后).pdf,
永安林业:2016年年度报告.pdf,
永安林业:2017年年度报告.pdf,
永安林业:2018年年度报告(更新后).pdf,
永安林业:2019年年度报告.pdf,
永安林业:2021年年度报告.pdf,
浙江永强:2011年年度报告.pdf,
浙江永强:2012年年度报告(更新后).pdf,
浙江永强:2013年年度报告.pdf,
浙江永强:2014年年度报告.pdf,
浙江永强:2015年年度报告.pdf,
浙江永强:2016年年度报告.pdf,
浙江永强:2017年年度报告.pdf,
浙江永强:2018年年度报告.pdf,
浙江永强:2019年年度报告.pdf,
浙江永强:2020年年度报告.pdf,
浙江永强:2021年年度报告.pdf,
ST永林:2020年年度报告.pdf
"""
name_list = name.split(",")
name_test = []
list_res = []
for item in name_list:
name_test.append(item.replace("\n",""))
for i in range(len(name_test)):
doc = fitz.open('%s'%(name_test[i]))
text=""
for j in range(16):
page = doc[j]
text += page.get_text()
p_year=re.compile('.*?(\d{4}) .*?年度报告.*?')
year = p_year.findall(text)[0]
sent = name_test[i]
sent_1 = sent.split(":")
name = sent_1[0]
p_rev = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
p_eps = re.compile('(?<=\n)基本每股收益(元/?/?\n?股)\s?\n?([-\d+,.]*)\s?\n?')
#p_site = re.compile('(?<=\n)\s?办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
#p_web =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./:]*)\s?(?=\n)',re.DOTALL)
revenue = float(p_rev.search(text).group(1).replace(',',''))
eps = p_eps.search(text).group(1)
#site = p_site.search(text).group(1)
#web = p_web.search(text).group(1)
tuple_res = (name,year,revenue,eps)
list_res.append(tuple_res)
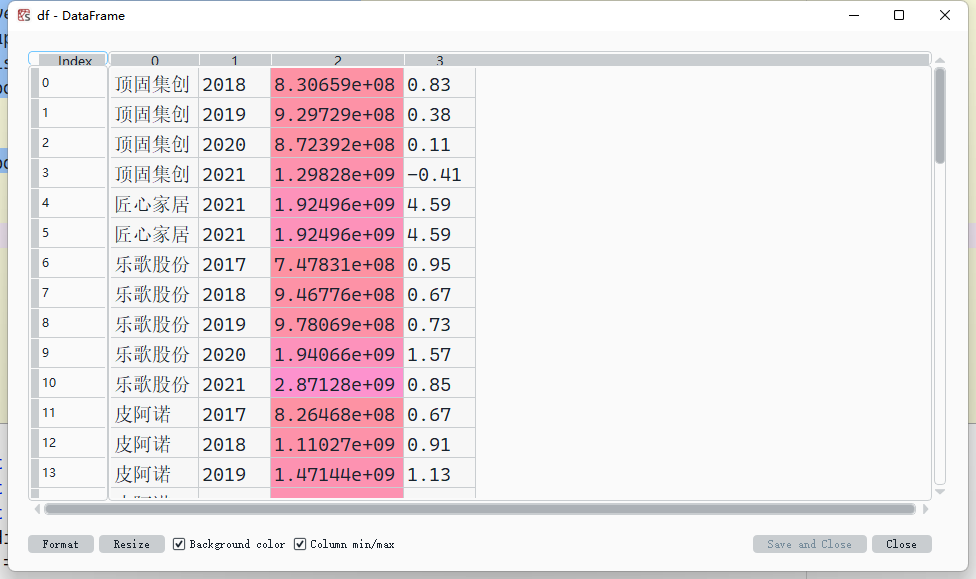
df = pd.DataFrame(list_res)
df = pd.DataFrame(list_res)
结果
| 股票简称 |
股票代码 |
办公地址 |
公司网址 |
| 顶固集创 |
300749 |
中山市东凤镇东阜三路 429 号 |
www.dinggu.net |
| 匠心家居 |
301061 |
常州市星港路 61 号 |
http://www.hhc-group.com.cn/ |
| 乐歌股份 |
300729 |
宁波市鄞州区首南街道学士路 536 号金东大厦 15-19 层 |
www.loctek.com< |
| 皮阿诺 |
002853 |
广东省中山市石岐区海景路 1 号 |
http://www.pianor.com//td>
|
| 尚品宅配 |
300616 |
广东省中山市石岐区海景路 1 号 |
http://www.pianor.com/ |
| 索菲亚 |
002572 |
广东省中山市石岐区海景路 1 号 |
http://www.pianor.com/ |
| 易尚展示 |
002751 |
广东省中山市石岐区海景路 1 号 |
http://www.pianor.com/ |
| 永安林业 |
000663 |
广东省中山市石岐区海景路 1 号 |
http://www.pianor.com/ |
| 浙江永强 |
002489 |
广东省中山市石岐区海景路 1 号 |
http://www.pianor.com/ |
解释
在收集数据的时候遇到非常多的问题,可能是犹豫对正则表达式的熟练度问题,也可能是基础不太牢的缘故,以至于公司的位置和网站仍然存在部分公司爬取不出来,超出了能力范围外,
这是我所欠缺的,所以一定程度上用了手动的方式
画图
代码
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.font_manager as fm
os.chdir(r"C:\Windows\Fonts")
fname = "simsun.ttc"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams["figure.dpi"] = 600
x_axis_data = [2012,2013,2014,2015,2016,2017,2018,2019,2020,2021]
y_axis_data1 = [None,None,None,None,None,None,8.30659e+08,9.29729e+08,8.72392e+08,1.29828e+09]
y_axis_data2 = [None,None,None,None,None,None,None,None,None,5.80792e+08]
y_axis_data3 = [None,None,None,None,None,None,None,None,None,1.92496e+09]
y_axis_data4 = [None,None,None,None,None,7.47831e+08,9.46776e+08,9.78069e+08,1.94066e+09,2.87128e+09]
y_axis_data5 = [None,None,None,None,None,8.26468e+08,1.11027e+09,1.47144e+09,1.49362e+09,1.82366e+09]
y_axis_data6 = [None,None,None,None,None,5.32345e+09,6.64539e+09,7.26079e+09,6.51343e+09,7.30961e+09]
y_axis_data7 = [1.2217e+09,1.78348e+09,2.36108e+09,3.19574e+09,4.52996e+09,6.16144e+09,7.31089e+09,7.68608e+09,8.35283e+09,1.04071e+10]
y_axis_data8 = [None,None,None,5.37178e+08,6.40466e+08,7.32428e+08,1.12403e+09,1.04554e+09,1.02427e+09,8.03661e+08]
y_axis_data9 = [4.56898e+08,4.58932e+08,4.60006e+08,8.91661e+08,1.55398e+09,1.24003e+09,7.54832e+08,7.02153e+08,None,5.06311e+08]
y_axis_data10 = [2.75911e+09,3.02236e+09,3.29974e+09,3.54061e+09,3.79234e+09,4.53632e+09,4.3861e+09,4.68521e+09,4.95463e+09,8.15081e+09]
plt.plot(x_axis_data, y_axis_data1, 'black', alpha=0.5, linewidth=1, label='顶固集创')
plt.plot(x_axis_data, y_axis_data2, 'red', alpha=0.5, linewidth=1, label='ST永林')
plt.plot(x_axis_data, y_axis_data3, 'orange', alpha=0.5, linewidth=1, label='匠心家居')
plt.plot(x_axis_data, y_axis_data4, 'gold', alpha=0.5, linewidth=1, label='乐哥股份')
plt.plot(x_axis_data, y_axis_data5, 'y', alpha=0.5, linewidth=1, label='皮阿诺')
plt.plot(x_axis_data, y_axis_data6, 'lawngreen', alpha=0.5, linewidth=1, label='尚品宅配')
plt.plot(x_axis_data, y_axis_data7, 'aquamarine', alpha=0.5, linewidth=1, label='索菲亚')
plt.plot(x_axis_data, y_axis_data8, 'cyan', alpha=0.5, linewidth=1, label='易尚展示')
plt.plot(x_axis_data, y_axis_data9, 'dodgerblue', alpha=0.5, linewidth=1, label='永安林业')
plt.plot(x_axis_data, y_axis_data10, 'm', alpha=0.5, linewidth=1, label='浙江永强')
plt.legend(prop = zhfont1)
plt.xlabel('time')
plt.ylabel('Revenue')
plt.show()
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.font_manager as fm
os.chdir(r"C:\Windows\Fonts")
fname = "simsun.ttc"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams["figure.dpi"] = 600
x_axis_data = [2012,2013,2014,2015,2016,2017,2018,2019,2020,2021]
y_axis_data1 = [None,None,None,None,None,None,0.83,0.38,0.11,-0.41]
y_axis_data2 = [None,None,None,None,None,None,None,None,None,4.59]
y_axis_data3 = [None,None,None,None,None,None,None,None,None,0.11]
y_axis_data4 = [None,None,None,None,None,0.95,0.67,0.73,1.57,0.85]
y_axis_data5 = [None,None,None,None,None,0.67,0.91,1.13,1.27,-3.91]
y_axis_data6 = [None,None,None,None,None,3.71,2.46,2.69,0.510,0.45]
y_axis_data7 = [0.81,0.56,0.74,1.04,1.48,0.98,1.04,1.18,1.31,0.13]
y_axis_data8 = [None,None,None,0.31,0.11,0.34,0.54,0.28,0.35,-3.23]
y_axis_data9 = [0.05,0.05,-0.10,0.20,0.36,0.20,-3.90,-0.7,None,0.16]
y_axis_data10 = [0.40,0.55,0.67,0.24,0.03,0.04,-0.05,0.23,0.24,0.06]
plt.plot(x_axis_data, y_axis_data1, 'black', alpha=0.5, linewidth=1, label='顶固集创')
plt.plot(x_axis_data, y_axis_data2, 'red', alpha=0.5, linewidth=1, label='ST永林')
plt.plot(x_axis_data, y_axis_data3, 'orange', alpha=0.5, linewidth=1, label='匠心家居')
plt.plot(x_axis_data, y_axis_data4, 'gold', alpha=0.5, linewidth=1, label='乐哥股份')
plt.plot(x_axis_data, y_axis_data5, 'y', alpha=0.5, linewidth=1, label='皮阿诺')
plt.plot(x_axis_data, y_axis_data6, 'lawngreen', alpha=0.5, linewidth=1, label='尚品宅配')
plt.plot(x_axis_data, y_axis_data7, 'aquamarine', alpha=0.5, linewidth=1, label='索菲亚')
plt.plot(x_axis_data, y_axis_data8, 'cyan', alpha=0.5, linewidth=1, label='易尚展示')
plt.plot(x_axis_data, y_axis_data9, 'dodgerblue', alpha=0.5, linewidth=1, label='永安林业')
plt.plot(x_axis_data, y_axis_data10, 'm', alpha=0.5, linewidth=1, label='浙江永强')
plt.legend(prop = zhfont1)
plt.xlabel('time')
plt.ylabel('Revenue')
plt.show()
结果
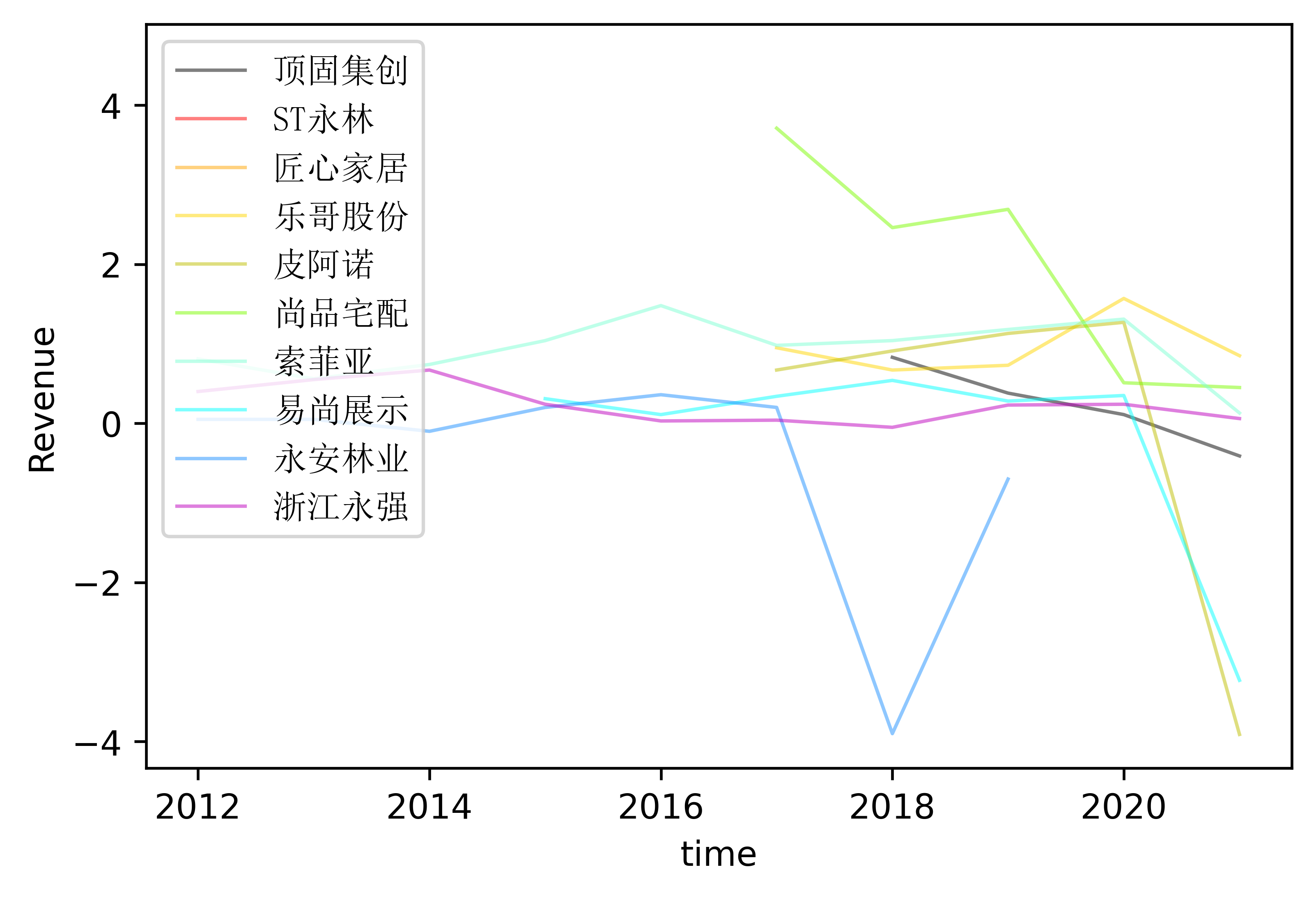
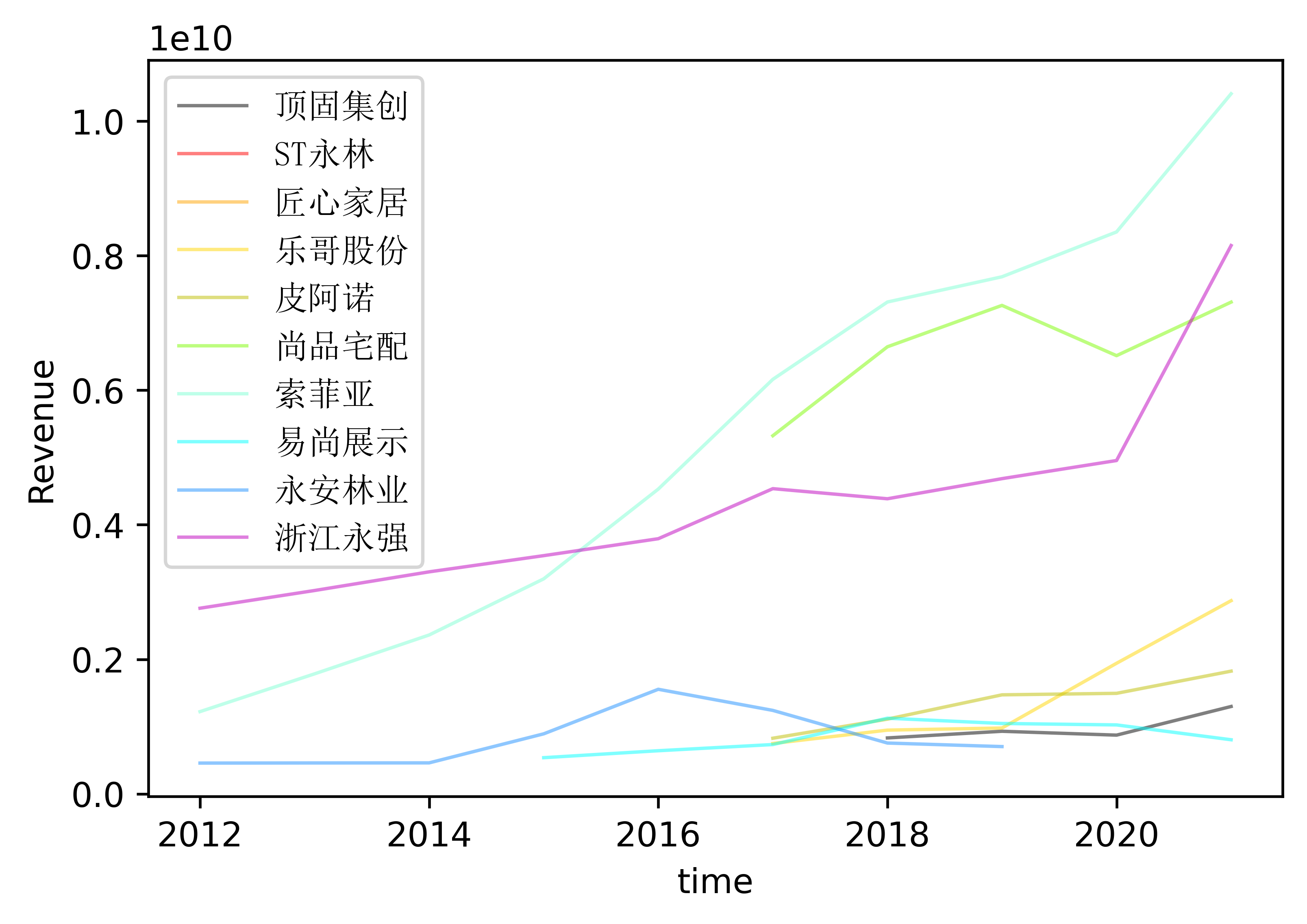
解释
在画图上,我处理不出来转化数据的方法,于是便采取了人工处理的办法
分析
从已有图像可以看出,在家居制造业,平均的利润水平彼此之间相差是不大的,而且随着时间的推移,大部分的公司都倾向统一利润水平。
而从EPS的角度可以看到,出去易尚展示、尚品宅配以及浙江永强外是值得投资的公司,其余的公司在EPS的表现都较差,并且、浙江永强和易尚展示在近几年仍然呈现一股上升姿态,这是不错的利好信息。
总结
虽然总体上完成度不佳,但是相对而言我还是比较满意的,从0基础到现在多少会用爬虫和fitz来处理pdf,我感觉我的能力得到很大程度的提升,但还欠缺一段时间的打磨