
import re
import pandas as pd
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import requests
from bs4 import BeautifulSoup
import time
import fitz
import matplotlib.pyplot as plt
from pandas import Series, DataFrame
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
%matplotlib qt5
print(fitz.__doc__)
os.chdir(r"C:\Users\de'l\Desktop\1234")
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
doc = fitz.open('行业分类.pdf')
doc.page_count
page5 = doc.load_page(5)
text5 = page5.get_text()
page6 = doc.load_page(6)
text6 = page6.get_text()
p1 = re.compile(r'酒、饮料和精制茶制造业(.*?)酒鬼酒', re.DOTALL)
toc = p1.findall(text5)
toc1 = toc[0]
p2 = re.compile(r'(?<=\n)(\d{1})(\d{5})\n(\w+)(?=\n)')
toc2 = p2.findall(toc1)
p3 = re.compile(r'酒、饮料和精制茶制造业(.*?)605388', re.DOTALL)
toc3 = p3.findall(text6)
toc4 = toc3[0]
p2 = re.compile(r'(?<=\n)(\d{1})(\d{5})\n(\w+)(?=\n)')
toc5 = p2.findall(toc4)
hb = toc2 + toc5
hb1 = pd.DataFrame(hb)
year = {'year': ['2012', '2013', '2014','2015', '2016', '2017', '2018', '2019', '2020', '2021']}
dy = pd.DataFrame(year)
hb1[0] = hb1[0].astype(int)
hb1['a'] = hb1[0].astype(str)
hb1['code'] = hb1['a'] + hb1[1]
sse = hb1.loc[(hb1[0]==6)]
szse = hb1.loc[(hb1[0]==0)]
sse['code'] = '6' + sse[1]
sse['code'] = sse['code'].astype(int)
sse = sse.reset_index(drop=True)
driver_url = r"C:\Users\de'l\Downloads\edgedriver_win64 (1)\msedgedriver.exe"
prefs = {'profile.default_content_settings.popups': 0, 'download.default_directory':r'C:\Users\20279\Desktop\珠海港定期报告'} # 设置下载文件存放路径,这里要写绝对路径
options = webdriver.EdgeOptions()
options.add_experimental_option('prefs', prefs)
driver = webdriver.Edge(executable_path=driver_url, options=options)
'''szse'''
driver = webdriver.Edge()
driver.get('http://www.szse.cn/disclosure/listed/fixed/index.html')
driver.implicitly_wait(10)
driver.set_window_size(1552, 840)
element = driver.find_element(By.ID, 'input_code')
element.send_keys('花园生物' + Keys.RETURN)
for i in range(len(szse)):
os.chdir(r"C:\Users\de'l\Desktop\酒、饮料和精制茶制造业10年内年度报告")
name = szse[2][i]
button = driver.find_element(By.CLASS_NAME, 'btn-clearall')
button.click()
element = driver.find_element(By.ID, 'input_code')
element.send_keys('%s'%name + Keys.RETURN)
driver.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
driver.find_element(By.LINK_TEXT, "年度报告").click()
time.sleep(2)
element = driver.find_element(By.ID, 'disclosure-table')
innerHTML = element.get_attribute('innerHTML')
f = open('innerHTML_%s.html'%name,'w',encoding='utf-8')
f.write(innerHTML)
f.close()
f = open('innerHTML_%s.html'%name,encoding='utf-8')
html = f.read()
f.close()
dt = DisclosureTable(html)
df = dt.get_data()
df['简称'] = name
df['公告时间'] = pd.to_datetime(df['公告时间'])
df['year'] = df['公告时间'].dt.year
df['year'] = df['year'] - 1
p_zy = re.compile('.*?(摘要).*?')
for i in range(len(df)):
a = p_zy.findall(df['公告标题'][i])
if len(a) != 0:
df.drop([i],inplace = True)
p_yw = re.compile('.*?(英文版).*?')
for i in range(len(df)):
a = p_yw.findall(df['公告标题'][i])
if len(a) != 0:
df.drop([i],inplace = True)
df = df.reset_index(drop=True)
p_nb = re.compile('.*?(年度报告).*?')
p_nb2 = re.compile('.*?(年报).*?')
for i in range(len(df)):
b1 = p_nb.findall(df['公告标题'][i])
b2 = p_nb2.findall(df['公告标题'][i])
if len(b1) == 0 and len(b2) == 0:
df.drop([i],inplace = True)
df = df.reset_index(drop=True)
df = df.drop_duplicates('year', keep='first', inplace=False)
df = df.reset_index(drop=True)
df['year_str'] = df['year'].astype(str)
df['name'] = name + df['year_str'] + '年年报'
name1 = df['简称'][0]
df.to_csv('%scsv文件.csv'%name1)
os.mkdir('%s年度报告'%name)
os.chdir(r"C:\Users\de'l\Desktop\酒、饮料和精制茶制造业10年内年度报告\%s年度报告"%name)
for y in range(len(dy)):
y = int(y)
ye = dy['year'][y]
name1 = df['简称'][0]
rename = name1 + ye
for a in range(len(df)):
if df['name'][a] == '%s年年报'%rename:
href0 = df.iat[a,3]
r = requests.get(href0, allow_redirects=True)
f = open('%s年度报告.pdf'%rename, 'wb')
f.write(r.content)
f.close()
r.close()
def get_link(txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
title = matchObj.group(2).strip()
return([attachpath, title])
p_a = re.compile('\n\s*(.*?)\s*?', re.DOTALL)
p_span = re.compile('\n\s*(.*?)\s*?', re.DOTALL)
get_code = lambda txt: p_a.search(txt).group(1).strip()
get_time = lambda txt: p_span.search(txt).group(1).strip()
def get_data(df_txt):
prefix_href = 'http://www.sse.com.cn/'
df = df_txt
ahts = [get_link(td) for td in df['公告标题']]
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['名称']]
#
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[1] for aht in ahts],
'href': [prefix_href + aht[0] for aht in ahts],
})
return(df)
driver.get('http://www.sse.com.cn/disclosure/listedinfo/regular/')
driver.implicitly_wait(10)
driver.set_window_size(1552, 840)
dropdown = driver.find_element(By.CSS_SELECTOR, ".selectpicker-pageSize")
dropdown.find_element(By.XPATH, "//option[. = '每页100条']").click()
time.sleep(1)
for i in range(len(sse)):
os.chdir(r"C:\Users\de'l\Desktop\酒、饮料和精制茶制造业10年内年度报告")
code = sse['code'][i]
driver.find_element(By.ID, "inputCode").clear()
driver.find_element(By.ID, "inputCode").send_keys("%s"%code)
driver.find_element(By.CSS_SELECTOR, ".js_reportType .btn").click()
driver.find_element(By.LINK_TEXT, "全部").click()
driver.find_element(By.CSS_SELECTOR, ".js_reportType .btn").click()
driver.find_element(By.LINK_TEXT, "年报").click()
time.sleep(1)
element = driver.find_element(By.CLASS_NAME, 'table-responsive')
innerHTML = element.get_attribute('innerHTML')
soup = BeautifulSoup(innerHTML)
html = soup.prettify()
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
n = len(trs)
for i in range(len(trs)):
if n >= i:
if len(trs[i]) == 5:
del trs[i]
n = len(trs)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'名称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
df_data = get_data(df)
df_data = pd.concat([df_data, df['公告时间']], axis=1)
df_data['公告时间'] = pd.to_datetime(df_data['公告时间'])
df_data['year'] = df_data['公告时间'].dt.year
df_data['year'] = df_data['year'] - 1
name = df_data['简称'][0]
df_data['简称'] = name
p_zy = re.compile('.*?(摘要).*?')
for i in range(len(df_data)):
a = p_zy.findall(df_data['公告标题'][i])
if len(a) != 0:
df_data.drop([i],inplace = True)
df_data = df_data.reset_index(drop=True)
p_nb = re.compile('.*?(年度报告).*?')
p_nb2 = re.compile('.*?(年报).*?')
for i in range(len(df_data)):
b1 = p_nb.findall(df_data['公告标题'][i])
b2 = p_nb2.findall(df_data['公告标题'][i])
if len(b1) == 0 and len(b2) == 0:
df_data.drop([i],inplace = True)
df_data = df_data.reset_index(drop=True)
p_bnb = re.compile('.*?(半年).*?')
for i in range(len(df_data)):
c = p_bnb.findall(df_data['公告标题'][i])
if len(c) != 0:
df_data.drop([i],inplace = True)
df_data = df_data.drop_duplicates('year', keep='first', inplace=False)
df_data = df_data.reset_index(drop=True)
df_data['year_str'] = df_data['year'].astype(str)
df_data['name'] = name + df_data['year_str'] + '年年报'
name1 = df_data['简称'][0]
df_data.to_csv('%scsv文件.csv'%name1)
year = {'year': ['2012', '2013', '2014','2015', '2016', '2017', '2018', '2019', '2020', '2021', '2022']}
dy = pd.DataFrame(year)
os.mkdir('%s年度报告'%name)
os.chdir(r"C:\Users\de'l\Desktop\酒、饮料和精制茶制造业10年内年度报告\%s年度报告"%name)
for y in range(len(dy)):
y = int(y)
ye = dy['year'][y]
name1 = df_data['简称'][0]
rename = name1 + ye
for a in range(len(df_data)):
if df_data['name'][a] == '%s年年报'%rename:
href0 = df_data.iat[a,3]
r = requests.get(href0, allow_redirects=True)
f = open('%s年度报告.pdf'%rename, 'wb')
f.write(r.content)
f.close()
r.close()
'''解析年报'''
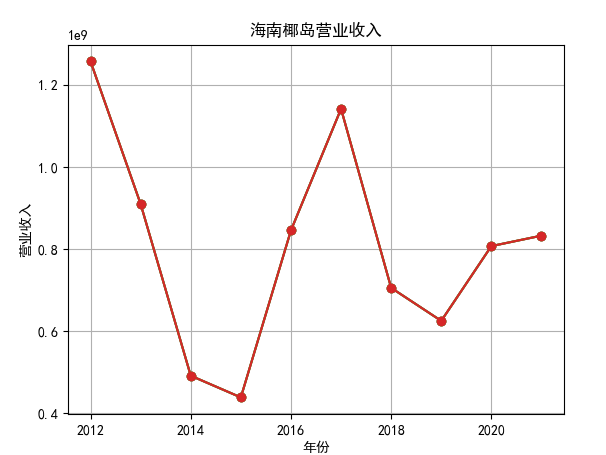
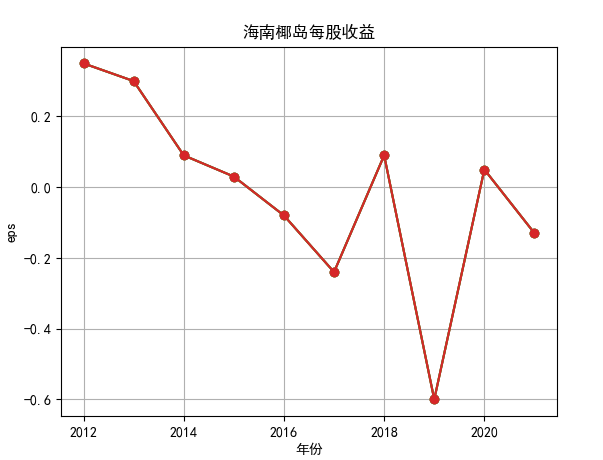
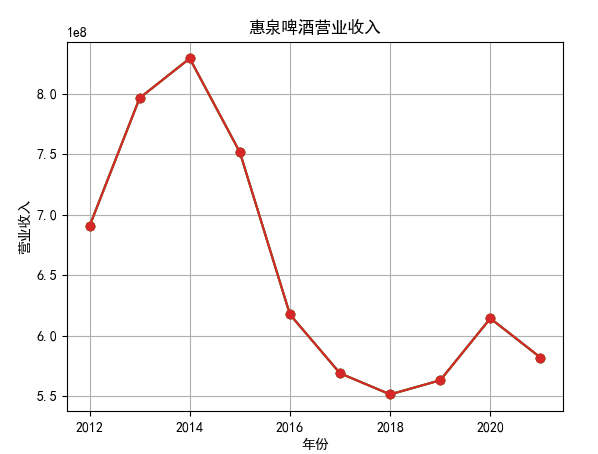
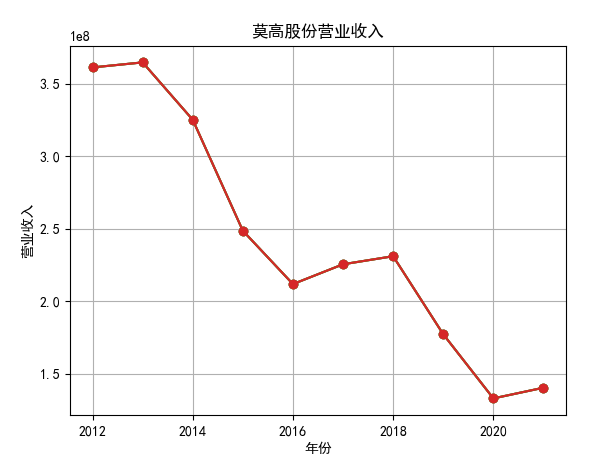
hbcwsj = pd.DataFrame(index=range(2012,2021),columns=['营业收入','基本每股收益'])
hbsj = pd.DataFrame()
#i = 31
for i in range(len(hbe)):
name2 = hb1[2][i]
code = hb1['code']
dcsv = pd.read_csv(r"C:\Users\de'l\Desktop\酒、饮料和精制茶制造业10年内年度报告\%scsv文件.csv"%name2)
dcsv['year_str'] = dcsv['year'].astype(str)
os.chdir(r"C:\Users\de'l\Desktop\酒、饮料和精制茶制造业10年内年度报告\%s年度报告"%name2)
#r = 5
for r in range(len(dcsv)):
year_int = dcsv.year[r]
if year_int >= 2012:
year2 = dcsv.year_str[r]
aba = name2 + year2
doc = fitz.open(r'%s年度报告.PDF'%aba)
text=''
for j in range(22):
page = doc[j]
text += page.get_text()
#p_year = re.compile('.*?(\d{4}) .*?年度报告.*?')
#year_int = int(p_year.findall(text)[0])
#设置需要匹配的四种数据的pattern
#p_rev = re.compile('(?<=\n)营业.*?收入.*?\n([\d+,.]*)\s?(?=\n)')
p_rev = re.compile('(?<=\n)营业.*?收入.*?\n([\d+,.]+).*?(?=\n)')
revenue = float(p_rev.search(text).group(1).replace(',',''))
#p_eps = re.compile('(?<=\n)基本每股收益.*?\n([-\d+,.]*)\s?(?=\n)')
#p_eps = re.compile('(?<=\n)基本每股收益.*?\n.*?\n?([-\d+,.]+)\s?(?=\n)')
p_eps = re.compile('(?<=\n)基\n?本\n?每\n?股\n?收\n?益.*?\n.*?\n?([-\d+,.]+)\s*?(?=\n)')
eps = float(p_eps.search(text).group(1))
#p_web = re.compile('(?<=\n)公司.*?网址.*?\n(.*?)(?=\n)')
p_web = re.compile('(?<=\n).*?网址.*?\n(.*?)(?=\n)')
web = p_web.search(text).group(1)
p_site = re.compile('(?<=\n).*?办公地址.*?\n(.*?)(?=\n)')
site = p_site.search(text).group(1)
hbcwsj.loc[year_int,'营业收入'] = revenue
hbcwsj.loc[year_int,'基本每股收益'] = eps
hbcwsj = hbcwsj.astype(float)
hbcwsj.to_csv(r"C:\Users\de'l\Desktop\酒、饮料和精制茶制造业10年内年度报告\%s财务数据.csv"%name2)
hbsj = hbsj.append(hbcwsj.tail(1))
#with open('C:\Users\20279\Desktop\酒、饮料和精制茶制造业10年内年度报告\%s财务数据.csv'%name2,'a',encoding='utf-8') as f:
#content='股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name2,code,site,web)
# f.write(content)
hbsj.index = Series(hb[2])
hbsj.sort_values(by='营业收入',axis=0,ascending=True)
hbsj2 = hbsj.head(5)
hbsj2['name'] = hbsj2.index
hbsj2 = hbsj2.reset_index(drop=True)
plt.xlabel('年份')
plt.ylabel('营业收入')
plt.grid(True)
plt.title('营业收入')
i=0
for i in range(len(hbsj2)):
name3 = hbsj2.name[i]
cwsj = pd.read_csv(r"C:\Users\de'l\Desktop\酒、饮料和精制茶制造业10年内年度报告\s%财务数据.csv"%name3)
cwsj.columns = ['year', 'rev', 'eps']
x = cwsj['year']
y = cwsj['rev']
plt.plot(x, y, label='%s'%name3, marker = 'o')
plt.legend(loc='upper left')
os.chdir(r"C:\Users\de'l\Desktop\酒、饮料和精制茶制造业10年内年度报告")
plt.savefig('十家营业收入最高的公司的收入走势图')
plt.clf()
plt.xlabel('年份')
plt.ylabel('eps')
plt.grid(True)
plt.title('每股收益')
for i in range(len(hbsj2)):
name3 = hbsj2.name[i]
cwsj = pd.read_csv(r"C:\Users\de'l\Desktop\酒、饮料和精制茶制造业10年内年度报告\s%财务数据.csv"%name3)
cwsj.columns = ['year', 'rev', 'eps']
x = cwsj['year']
y = cwsj['eps']
plt.plot(x, y, label='%s'%name3, marker = 'o')
plt.legend(loc='upper left')
plt.savefig('十家营业收入最高的公司的eps走势图')
plt.clf()
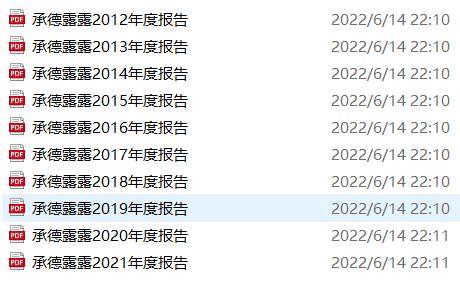
先利用网络爬虫获取深交所和上交所股票的所有html,后根据html内容下载所有年报,以承德露露为例子
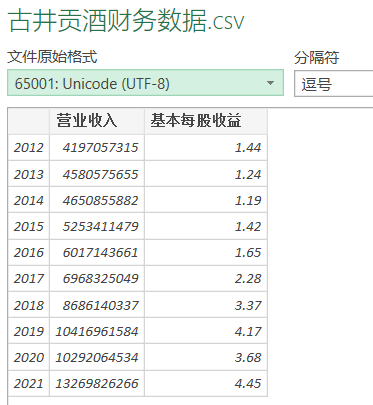

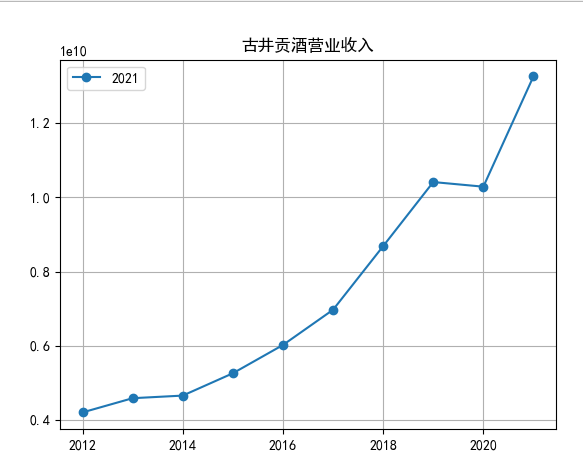
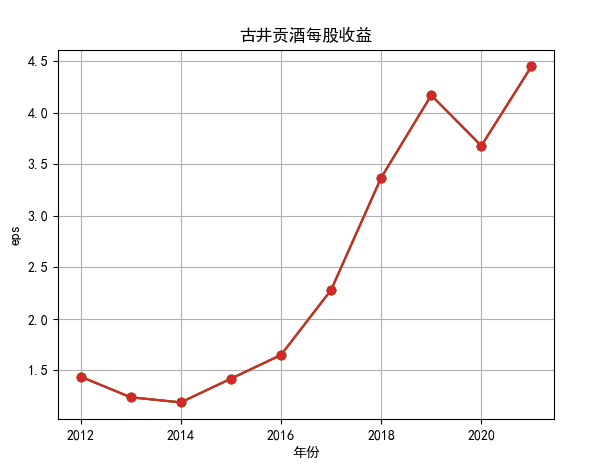
将所有年报数据提取后,另存一个csv,命名为财务数据,里面有每股收益和营业收入,由于公司过多,现以古井贡酒为例
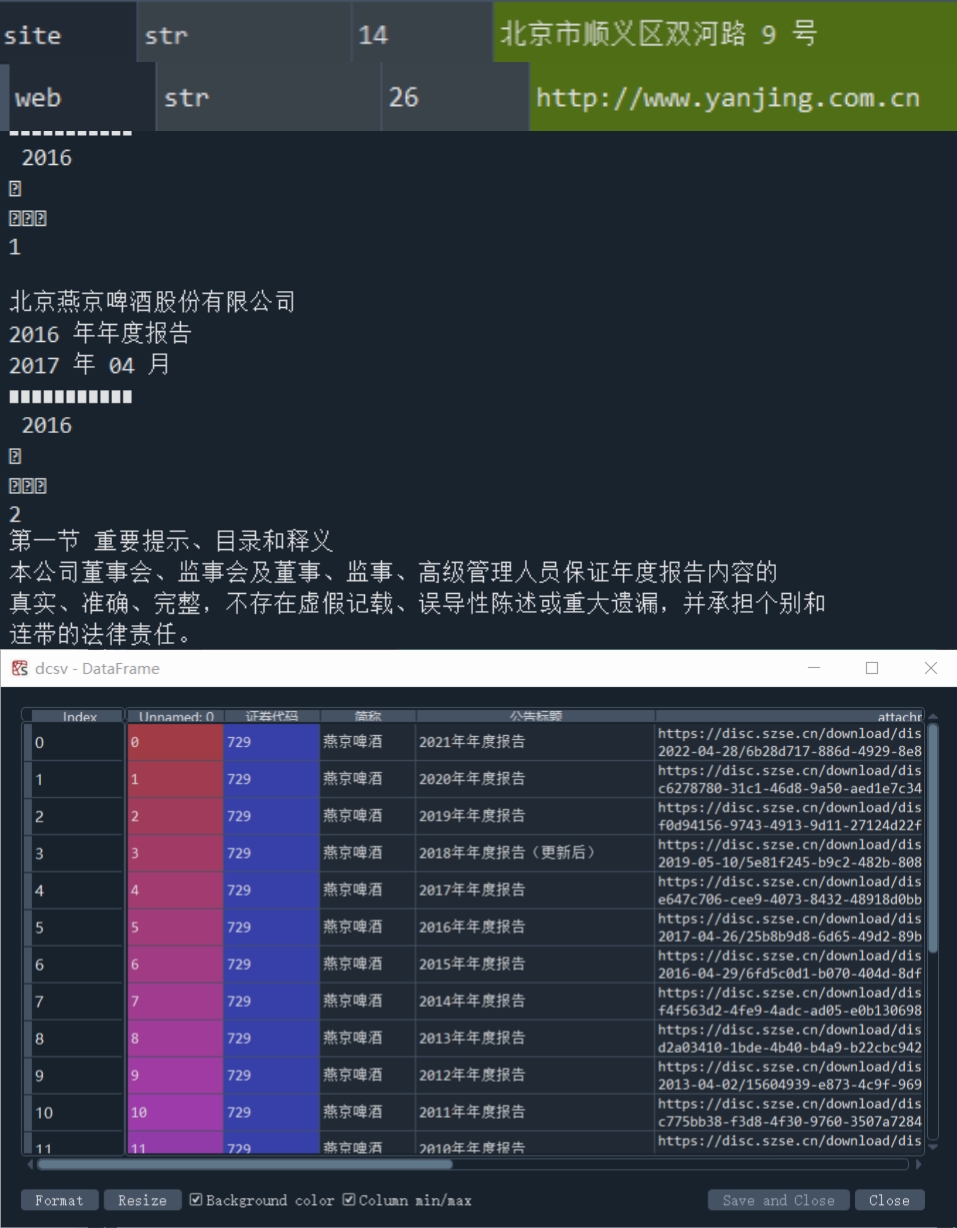
在年报中提取公司代码,简称,地址等数据保存为csv
代码运行中同时保存年报,各公司csv,以及财务数据csv
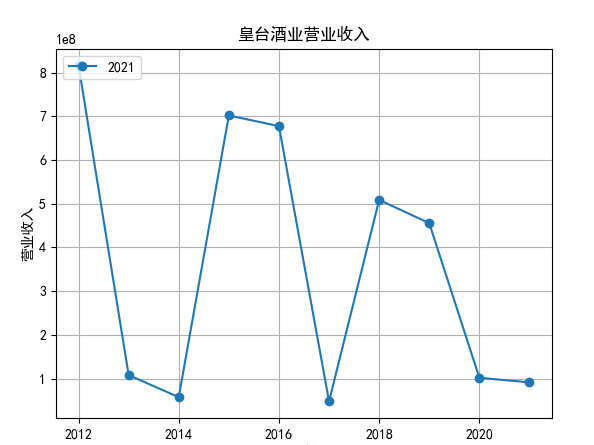
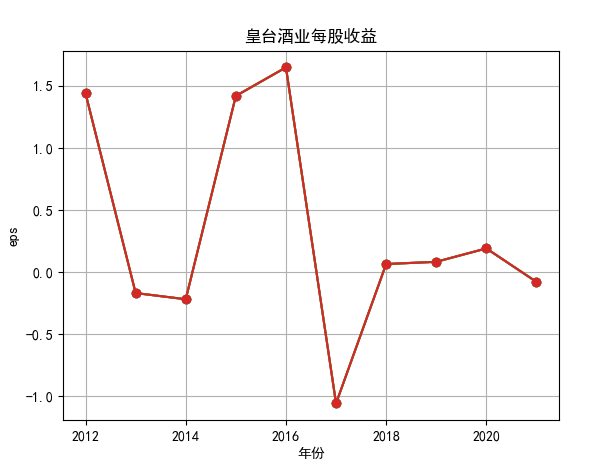
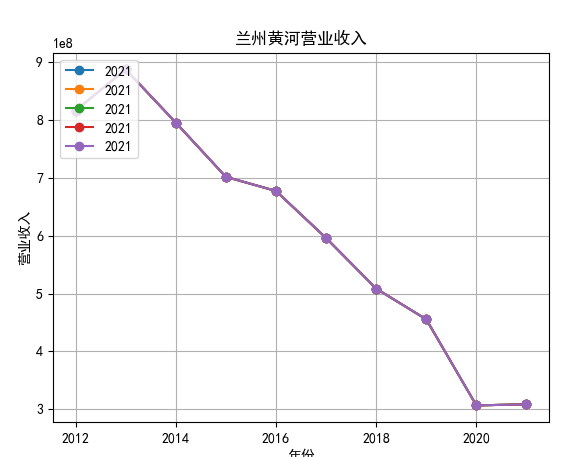
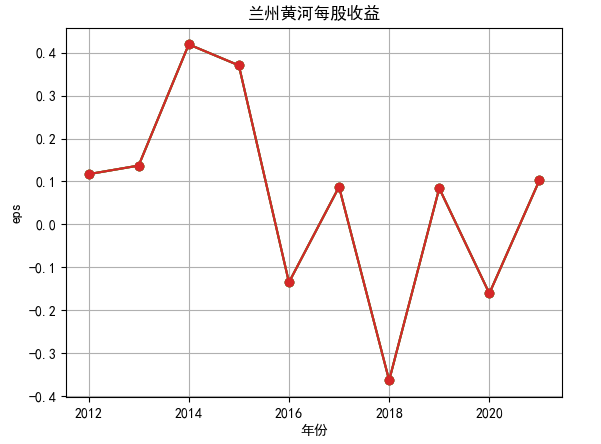
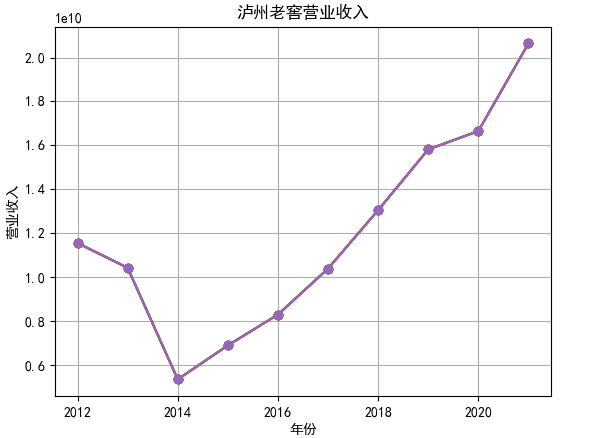
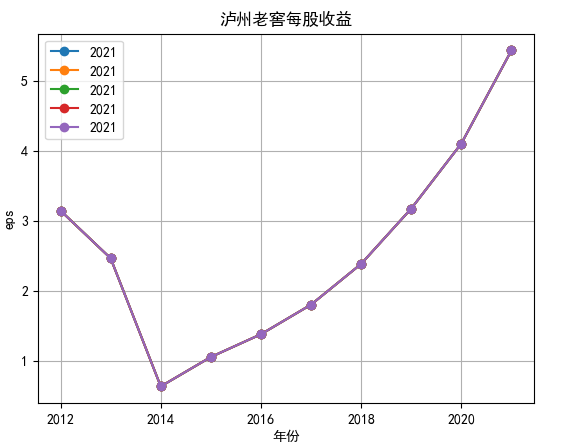
对每个公司的营业收入进行排序,提取排名前十家公司,后导入十家公司的财务数据csv进行折线图分析。
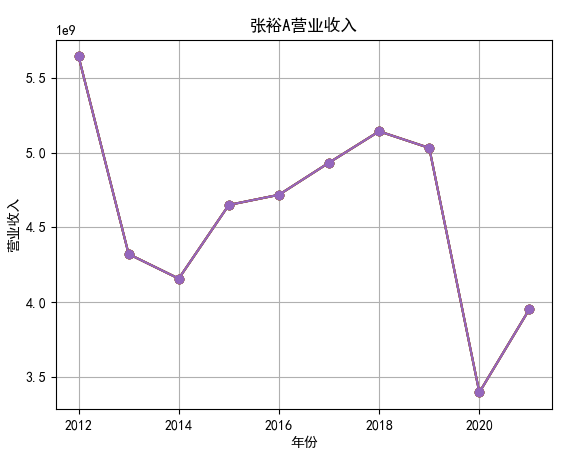
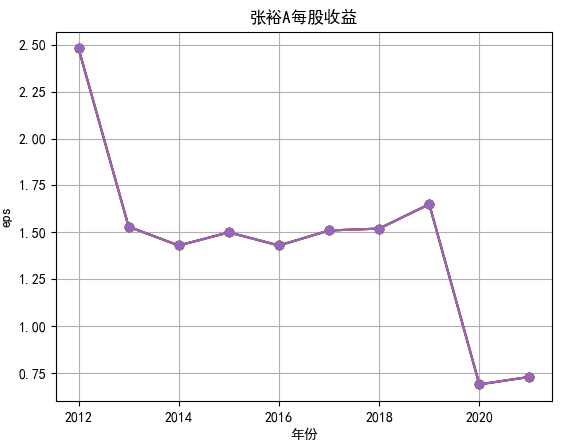
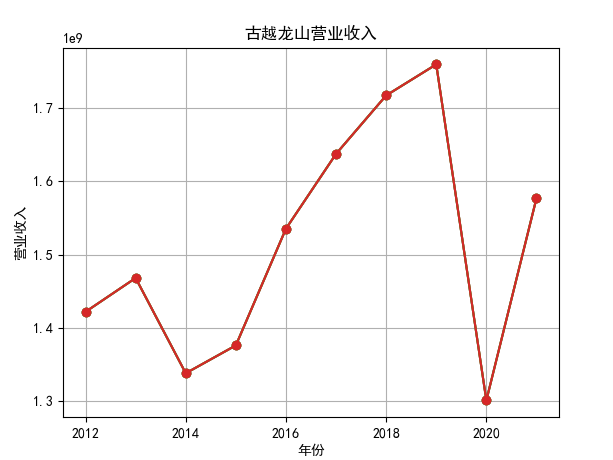
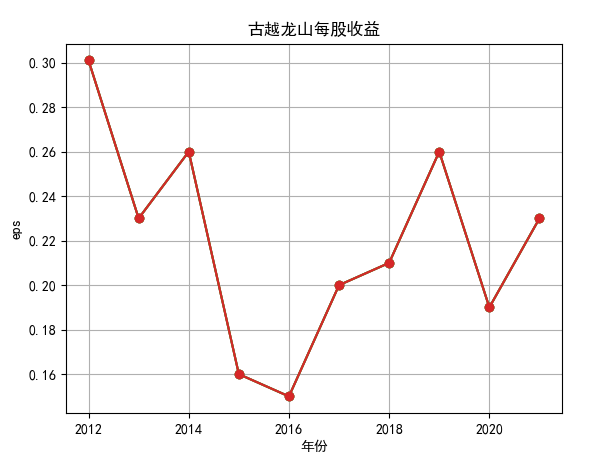
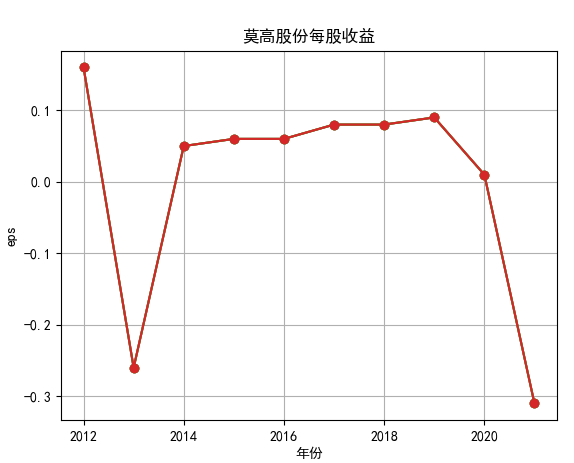
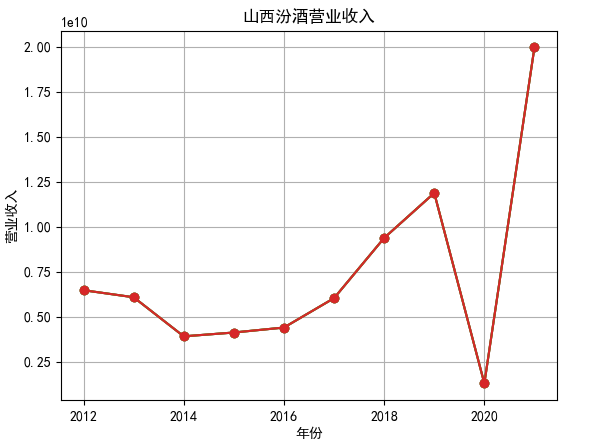
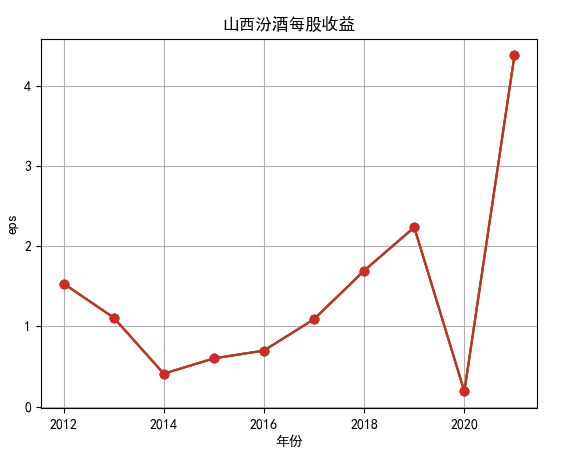
行情解读:根据排名前十各公司营业收入和每股收益来看,在2019年许多酒类公司出现营业亏随,每股收益也称下降趋势,但对于该行业来说,行情一直是良好状态,并且知名酒业一直是在 行业中处于领先地位,在经济低迷期也有小幅度上涨的趋势。从行业对比来看,中国白酒、啤酒行业持续盈利,葡萄酒行业营收惨淡,白酒行业泸州老窖遥遥领先,,提价抢占中高端市场;啤酒行业产量最高、售价较低,市场需求大,燕京啤酒等啤酒企业在今年前三季度都实现了营收和净利润的双上涨;与之相反,葡萄酒行业整体市场营收情况惨淡,过半上市企业出现营收和净利润同时下降,国内葡萄酒龙头企业张裕集团也不能避免。