# -*- coding: utf-8 -*-
"""
Created on Wed May 11 17:33:21 2022
@author: 於心怡、郭嘉懿、傅元娴
"""
import pdfplumber
import pandas as pd
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import time
import os
import requests
from bs4 import BeautifulSoup
#定义所需函数
'''
根据学生姓名匹配被分配到的行业深市上市的公司
'''
def InputStu():
Names = str(input('请输入姓名:'))
Namelist = Names.split()
return Namelist
def Match(Namelist,assignment):
match = pd.DataFrame()
for name in Namelist:
match = pd.concat([match,assignment.loc[assignment['完成人']==name]])
Number = match['行业'].tolist()
return Number
def Get_sz(data):
sz=['200','300','301','00','080'] #深市股票代码A股是以000开头;深市B股代码是以200开头;中小板股票以002开头;
#深市创业板的股票是以300、301开头(比如第一只创业板股票特锐德)。
#另外新股申购代码以00开头、配股代码以080开头。
lst = [ x for x in data for startcode in sz if x[3].startswith(startcode)==True ]
df = pd.DataFrame(lst,columns=data[0]).iloc[:,1:]
return df
def Get_sh(data): #上交所股票代码6开头
lst = [ x for x in data if x[3].startswith('6')==True ]
df = pd.DataFrame(lst,columns=data[0]).iloc[:,1:]
return df
def Getcompany(matched,df):
df_final = pd.DataFrame()
df_final = df.loc[df['行业大类代码']==matched[0]]
return df_final
def Clean(lst): #把*ST前面的"*"去掉,否则文件保存的时候不方便,后面绘图的时候加上即可
for i in range(len(lst)):
lst[i] = lst[i].replace('*','')
return lst
'''
利用selenium爬取所需公司年报
'''
#这里别忘了根据个人浏览器定义函数里的browser
def InputTime(start,end): #找到时间输入窗口并输入时间
START = browser.find_element(By.CLASS_NAME,'input-left')
END = browser.find_element(By.CLASS_NAME,'input-right')
START.send_keys(start)
END.send_keys(end + Keys.RETURN)
def SelectReport(kind): #挑选报告的类别
browser.find_element(By.LINK_TEXT,'请选择公告类别').click()
if kind == 1:
browser.find_element(By.LINK_TEXT,'一季度报告').click()
elif kind == 2:
browser.find_element(By.LINK_TEXT,'半年报告').click()
elif kind == 3:
browser.find_element(By.LINK_TEXT,'三季度报告').click()
elif kind == 4:
browser.find_element(By.LINK_TEXT,'年度报告').click()
def SearchCompany(name): #找到搜索框,通过股票简称查找对应公司的报告
Searchbox = browser.find_element(By.ID, 'input_code') # Find the search box
Searchbox.send_keys(name)
time.sleep(0.2)
Searchbox.send_keys(Keys.RETURN)
def Clearicon(): #清除选中上个股票的历史记录
browser.find_elements(By.CLASS_NAME,'icon-remove')[-1].click()
def Clickonblank(): #点击空白
ActionChains(browser).move_by_offset(200, 100).click().perform()
def Save(filename,content):
with open(filename+'.html','w',encoding='utf-8') as f:
f.write(content)
'''
解析html获取年报表格(代码来源于吴老师上课分享)
'''
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
# 获得证券的代码和公告时间
p_a = re.compile('<a.*?>(.*?)</a>', re.DOTALL)
p_span = re.compile('<span.*?>(.*?)</span>', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
# 将txt_to_df赋给self
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('<tr>(.*?)</tr>', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('<td.*?>(.*?)</td>', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
# 获得下载链接
def get_link(self, txt):
p_txt = '<a.*?attachpath="(.*?)".*?href="(.*?)".*?<span.*?>(.*?)</span>'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix_href
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
#巨潮资讯网获取的html源码解析为dataframe格式
def cninfo_to_dataframe(filename):
f = open(filename+'.html',encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html)
links = soup.find_all('a') #找到所有a标签
Code=[]
Name=[]
Title=[]
href=[]
Href=[]
Text=[]
p=re.compile('.*?&announcementId=(\d+).*?&announcementTime=(\d{4}-\d{2}-\d{2})')
for link in links:
Text.append(link.text) #获取a标签的文字
Href.append(link.get('href')) #获取a标签的链接
for n in range(0,len(Text),3):
Code.append(Text[n]) #每一行第一个a标签的是代码,第二个是简称,第三个是标题
Name.append(Text[n+1])
Title.append(Text[n+2])
num=re.findall(p,Href[n+2]) #在年报href中匹配attachpath需要的字段
href.append('http://www.cninfo.com.cn/new/announcement/download?bulletinId='+str(num[0][0])+'&announceTime='+str(num[0][1]))
df=pd.DataFrame({'代码':Code,
'简称':Name,
'公告标题':Title,
'链接':href,})
return df
#新浪财经获取的html源码解析为dataframe格式
def sina_to_dataframe(name):
f = open(name+'.html',encoding='utf-8')
html = f.read()
f.close()
p_time=re.compile('(\d{4})(-\d{2})(-\d{2})')
times=p_time.findall(html)
y=[int(t[0]) for t in times]
m=[t[0]+t[1].replace('0','') for t in times]
d=[t[0]+t[1]+t[2] for t in times]
soup = BeautifulSoup(html,features="html.parser")
links = soup.find_all('a')
href=[]
Code=[]
Name=[]
Title=[]
Href=[]
Year=[]
p_id=re.compile('&id=(\d+)')
for link in links:
Title.append(link.text.replace('*',''))
href.append(link.get('href'))
for n in range(0,len(Title)):
Code.append(code)
Name.append(name)
matchedID=p_id.search(href[n]).group(1)
Href.append('http://file.finance.sina.com.cn/211.154.219.97:9494/MRGG/CNSESH_STOCK/%s/%s/%s/%s.PDF'
%(str(y[n]),m[n],d[n],matchedID))
Year.append(y[n-1])
df=pd.DataFrame({'代码':Code,
'简称':Name,
'公告标题':Title,
'链接':Href,
'年份':Year})
df=df[df['年份']>=2011]
return df
'''
过滤年报并下载文件
'''
def Readhtml(filename):
with open(filename+'.html', encoding='utf-8') as f:
html = f.read()
return html
def tidy(df): #清除“摘要”型、“(已取消)”型、“英文版”型文件
d = []
for index, row in df.iterrows():
ggbt = row[2]
a = re.search("摘要|取消|英文", ggbt)
if a != None:
d.append(index)
df1 = df.drop(d).reset_index(drop = True)
return df1
def Loadpdf(df):#用于下载文件
d1 = {}
for index, row in df.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
with open (key+".pdf", "wb") as code:
code.write(f.content)
#操作代码
'''
第一步,根据学生姓名自动挑选出所分配行业的上市公司
'''
pdf = pdfplumber.open('industry.pdf') #打开行业分类表
table = pdf.pages[0].extract_table() #这里由于我的公司在第一页,只读了第一页数据
#(全部数据读起来要10+s,如果有其他学生数据提取的需要可以稍作修改变成读取全部)
for i in range(len(table)): #填充每行的行业大类代码
if table[i][1] == None:
table[i][1] = table[i-1][1]
asign = pd.read_csv('001班行业安排表.csv',converters={'行业':str})[['行业','完成人']] #这里要注意把行业代码转为字符串,不然会失去开头的0
Names = InputStu() #输入学生姓名
MatchedI = Match(Names,asign) #匹配学生对应的行业
sz = Get_sz(table)
sh = Get_sh(table)
df_sz = Getcompany(MatchedI,sz) #获取所分配行业在深交所上市公司df
df_sh = Getcompany(MatchedI,sh) #获取所分配行业在上交所上市公司df
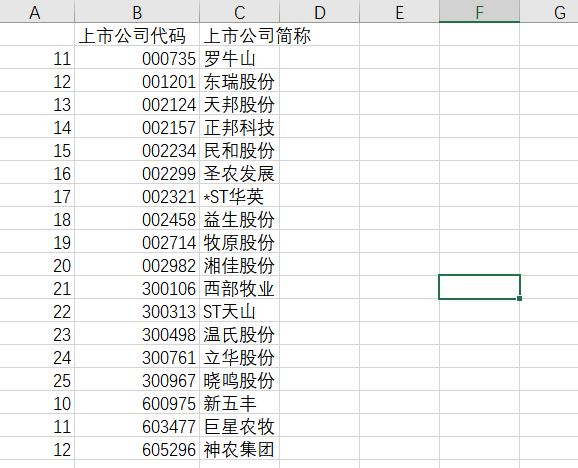
Company = df_sz[['上市公司代码','上市公司简称']]
Company2 = df_sh[['上市公司代码','上市公司简称']]
My_Company=Company.append(Company2)
My_Company.to_csv('company.csv',encoding='utf-8-sig') #将分配到的所有公司保存到本地文件
'''
第二步爬取所需公司年报披露表
'''
print('\n(爬取网页中......)')
browser = webdriver.Chrome()#这里别忘了根据个人浏览器选择
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
End = time.strftime('%Y-%m-%d', time.localtime())
InputTime('2012-01-01',End)
SelectReport(4) # 调用函数,选择“年度报告”
Clickonblank()
#在深交所官网爬取深交所上市公司年报链接
for index,row in Company.iterrows():
code = row[0]
name = row[1].replace('*','')
SearchCompany(code)
time.sleep(0.5) # 延迟执行0.5秒,等待网页加载
html = browser.find_element(By.ID, 'disclosure-table')
innerHTML = html.get_attribute('innerHTML')
Save(name,innerHTML)
Clearicon()
#在新浪财经爬取上交所上市公司年报下载链接(注:更新了上交所官网爬虫和页面解析,可以在下一个代码块中查看)
for index,row in Company2.iterrows():
code = row[0]
name = row[1].reaplce('*','')
browser.get('https://vip.stock.finance.sina.com.cn/corp/go.php/vCB_Bulletin/stockid/%s/page_type/ndbg.phtml'%code)
html = browser.find_element(By.CLASS_NAME, 'datelist')
innerHTML = html.get_attribute('innerHTML')
Save(name,innerHTML)
browser.quit()
'''
第三步,解析html获取年报表格存储到本地并下载年报文件
'''
print('\n【开始保存年报】')
print('正在下载深交所上市公司年报')
i = 0
for index,row in Company.iterrows(): #下载在深交所上市的公司的年报
i+=1
name = row[1].replace('*','')
html = Readhtml(name)
dt = DisclosureTable(html)
df = dt.get_data()
df1 = tidy(df)
df1.to_csv(name+'.csv',encoding='utf-8-sig')
os.makedirs(name,exist_ok=True)#创建用于放置下载文件的子文件夹
os.chdir(name)
Loadpdf(df1)
print(name+'年报已保存完毕。共',len(Company),'所公司,当前第',i,'所。')
os.chdir('../') #将当前工作目录爬到父文件夹,防止下一次循环找不到html文件
print('正在下载上交所上市公司年报')
j=0
for index,row in Company2.iterrows():
j+=1
name= row[1].replace('*','')
html = Readhtml(name)
df = sina_to_dataframe(name) #这里的代码还可以换成cninfo_to_dataframe(name) 或 sse_to_dataframe(name),取决于网页源码的来源网站
df1 = tidy(df)
df1.to_csv(name+'.csv',encoding='utf-8-sig')
os.makedirs(name,exist_ok=True)#创建用于放置下载文件的子文件夹
os.chdir(name)
Loadpdf(df1)
print(name+'年报已保存完毕。共',len(Company2),'所公司,当前第',j,'所。')
os.chdir('../') #将当前工作目录爬到父文件夹,防止下一次循环找不到html文件
注:由于上交所官网单次最高查询跨度为3年,(巨潮资讯网不会爬)故选择爬取新浪财经网。但是本代码对于新浪财经的解析不能准确获取公司
名称的变动,并且极个别年报没有下载链接,当需要获取的公司有多个在上交所上市时适合使用,如果该行业上交所上市公司不多,可以去巨潮资讯网手动copy年报列表链接的html
代码,并将代码中"df = sina_to_dataframe(name)"改为"df = cninfo_to_dataframe(name)"即可更精确地下载年报。
更新:后经过和郭嘉懿讨论发现上交所输入股票代码再点报告类型可以检索出全部报告,就可以不受手动选时间跨度三年的限制。下面附上上交所爬虫代码 以及网页解析代码。
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
def get_sse(code):
browser = webdriver.Chrome()#这里别忘了根据个人浏览器选择
browser.get('http://www.sse.com.cn/disclosure/listedinfo/regular/')
searchbox=browser.find_element(By.ID,'inputCode')
searchbox.send_keys(code)
time.sleep(1)
selectlist = browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner")
selectlist.click()
annual = browser.find_element(By.LINK_TEXT,'年报')
annual.click()
time.sleep(1)
html = browser.find_element(By.CLASS_NAME, 'table-responsive')
innerHTML = html.get_attribute('innerHTML')
searchbox.clear()
return innerHTML
#df为之前存储的上交所公司股票代码和简称的dataframe
for index,row in df.iterrows(): #这里为了代码简便爬虫部分用的自定义函数,但是这样爬起来比较慢(因为每爬一个公司就要开关浏览器)
code=row[0] #如果上交所公司数量大可以适当修改代码把爬虫的内容写到循环里,避免重复开关浏览器。
name=row[1]
filename = name.replace('*','')
html = get_sse(code)
Save(filename,html) #Save()函数在之前已经定义过
import re
import pandas as pd
def sse_to_dataframe(filename):
f = open(filename+'.html',encoding='utf-8')
html = f.read()
f.close()
p_row=re.compile('<tr>(.*?)</tr>',re.DOTALL)
trs=p_row.findall(html)
p_data=re.compile('<td.*?>(.*?)</td>',re.DOTALL)
tds=[p_data.findall(t) for t in trs if p_data.findall(t)!=[]]
p_code=re.compile('<span>(\d{6})</span>')
p_name=re.compile('<span>(\w+|-)</span>')
p_href=re.compile('<a.*?href="(.*?.pdf)".*?>')
p_title=re.compile('<a.*?>(.*?)</a>')
codes=[p_code.search(td[0]).group(1) for td in tds]
names=[p_name.search(td[1]).group(1) for td in tds]
links=[p_href.search(td[2]).group(1) for td in tds]
titles=[td[3][:4]+p_title.search(td[2]).group(1) for td in tds] #早年有的公司年报标题每年都一样,前面加一个发布年份以区分
pubtime=[td[3] for td in tds]
data=pd.DataFrame({'证券代码':codes,
'股票简称':names,
'公告标题':titles,
'公告链接':links,
'发布时间':pubtime})
for index,row in data.iterrows():
title=row[2]
time=row[-1][:4]
if ("年度报告" not in title and "年报" not in title) or (int(time))<2012:
data=data.drop(index=index)
return(data)
class DisclosureTable_sh():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'http://www.sse.com.cn'
p_code=re.compile('<span>(\d{6})</span>')
p_name=re.compile('<span>(\w+|-)</span>')
p_href=re.compile('<a.*?href="(.*?.pdf)".*?>')
p_title=re.compile('<a.*?>(.*?)</a>')
self.get_code = lambda td: p_code.search(td).group(1)
self.get_name = lambda td: p_name.search(td).group(1)
self.get_href = lambda td: p_href.search(td).group(1)
self.get_title = lambda td: p_title.search(td).group(1)
self.txt_to_df() #调用txt_to_df(self),得到初始化dataframe用于后续匹配
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p_tr = re.compile('<tr>(.*?)</tr>', re.DOTALL)
trs = p_tr.findall(html)
p_td = re.compile('<td.*?>(.*?)</td>', re.DOTALL)
tds=[p_td.findall(td) for td in trs if p_td.findall(td)!=[]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'股票简称': [td[1] for td in tds],
'公告标题和链接': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt=df
def get_data(self):
get_code = self.get_code
get_name = self.get_name
get_href = self.get_href
get_title = self.get_title
df = self.df_txt
prefix = self.prefix
codes = [get_code(td) for td in df['证券代码']]
names = [get_name(td) for td in df['股票简称']]
links = [prefix+get_href(td) for td in df['公告标题和链接']]
titles = [td[3][:4]+get_title(td) for td in df['公告标题和链接']]
pubtime = [td for td in df['公告时间']]
data = pd.DataFrame({'证券代码':codes,
'股票简称':names,
'公告标题':titles,
'公告链接':links,
'公告时间':pubtime})
for index,row in data.iterrows():
title = row[2]
time = int(row[-1][:4])
if "年度报告" not in title and "年报" not in title:
data=data.drop(index=index)
if time<2011:
data_latest10=data.drop(index=index)
self.df_alldata = data
self.df_data = data_latest10
return data_latest10
面向对象的编程方式更结构化,可以构建多个关于源文件的可调用数据,有机会要好好学习(又是一个flag)
使用的时候用dt=DisclosureTable_sh(html);
df=dt.get_data()替代sse_to_dataframe/sina_to_dataframe/cninfo_to_dataframe(html)
| 网页🔗 | 页面复杂度 | 数据质量 | 爬取方式 | 评价 |
|---|---|---|---|---|
| 深交所官网 | 中等 | 高 | selenium模仿点击 | 适合学习爬虫初期进行练习,可以通过检查功能找到所有需要点击的目标 |
| 上交所官网 | 中等偏高 | 中等(筛选年报有时也会出现不是年报的文件,早年的数据股票代码和简称缺失,标题严重重复,多个年份报告名仅为“公司简称+年报” 储存文件需要对报告标题进行修改) | selenium模仿点击 | 纯手动检查难以爬取,最好借助一定工具,容易报错 |
| 巨潮资讯网 | 复杂 | 很高(所有上市公司年报都可以搜索到) | 暂时不会,选择年报类型的地方每次刷新id前有一个随机数 | 爬取难度大(我菜),但是数据很全 |
| 新浪财经 | 简单 | 一般(有的公司年份不全、有的年份没有PDF文件,下载链接个别公司年份会变化) | 改变网页链接去到不同公司年报汇总独立页面,观察链接格式编写下载链接 | 最好爬(新浪的传统特点),改变股票代码即可去到不同公司的页面,缺点是数据质量不高 |
各公司查询近十年年报结果源码

解析后得到的表格
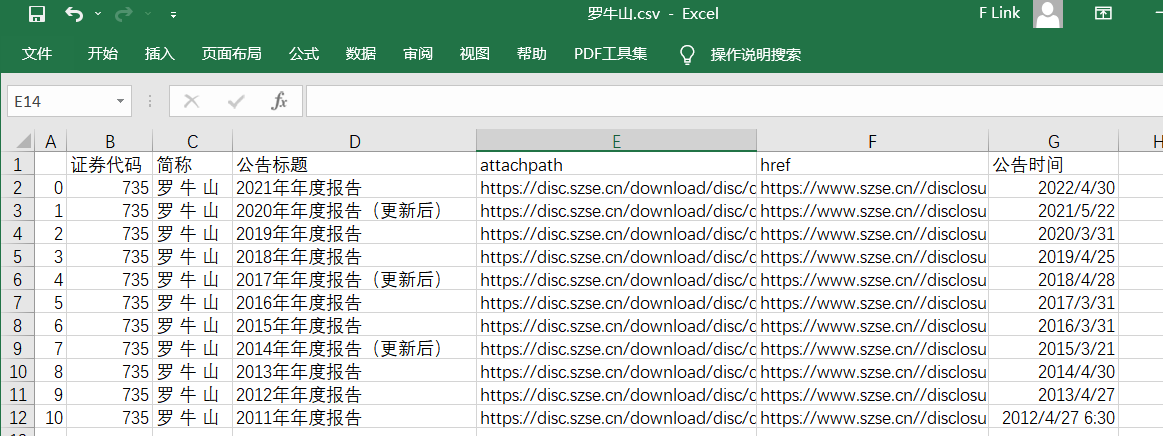
通过访问表格"attachpath"栏自动下载的年报
保存下来的所有公司名文件
Created on Tue May 24 12:24:18 2022
"""
@author: Napstablook
"""
import pandas as pd
import fitz
import re
Company=pd.read_csv('company.csv').iloc[:,1:] #读取上一步保存的公司名文件并转为列表
company=Company.iloc[:,1].tolist()
t=0
for com in company:
t+=1
com = com.replace('*','')
df = pd.read_csv(com+'.csv',converters={'证券代码':str}) #读取存有公告名称的csv文件用来循环访问pdf年报
df = df.sort_index(ascending=False)
final = pd.DataFrame(index=range(2011,2022),columns=['营业收入(元)','基本每股收益(元/股)']) #创建一个空的dataframe用于后面保存数据
final.index.name='年份'
code = str(df.iloc[0,1])
name = df.iloc[-1,2].replace(' ','')
for i in range(len(df)): #循环访问每年的年报
title=df.iloc[i,3]
doc = fitz.open('./%s/%s.pdf'%(com,title))
text=''
for j in range(15): #读取每份年报前15页的数据(一般财务指标读15页就够了,全部读取的话会比较耗时间)
page = doc[j]
text += page.get_text()
p_year=re.compile('.*?(\d{4}) .*?年度报告.*?') #捕获目前在匹配的年报年份
year = int(p_year.findall(text)[0])
#设置需要匹配的四种数据的pattern
p_rev = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
p_eps = re.compile('(?<=\n)基本每股收益(元/?/?\n?股)\s?\n?([-\d+,.]*)\s?\n?')
p_site = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
p_web =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./:]*)\s?(?=\n)',re.DOTALL)
revenue=float(p_rev.search(text).group(1).replace(',','')) #将匹配到的营业收入的千分位去掉并转为浮点数
if year>2011:
pre_rev=final.loc[year-1,'营业收入(元)']
if pre_rev/revenue>2:
print('%s%s营业收入下跌超过百分之50,可能出现问题,请手动查看'%(com,title))
eps=p_eps.search(text).group(1)
final.loc[year,'营业收入(元)']=revenue #把营业收入和每股收益写进最开始创建的dataframe
final.loc[year,'基本每股收益(元/股)']=eps
final.to_csv('【%s】.csv' %com,encoding='utf-8-sig') #将各公司数据存储到本地测csv文件
site=p_site.search(text).group(1) #匹配办公地址和网址(由于取最近一年的,所以只要匹配一次不用循环匹配)
web=p_web.search(text).group(1)
with open('【%s】.csv'%com,'a',encoding='utf-8-sig') as f: #把股票简称,代码,办公地址和网址写入文件末尾
content='股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name,code,site,web)
f.write(content)
print(name+'数据已保存完毕'+'(',t,'/',len(company),')')
所有公司的历年营业收入,每股收益数据和公司简称,股票代码,办公地址以及网址
错误细节
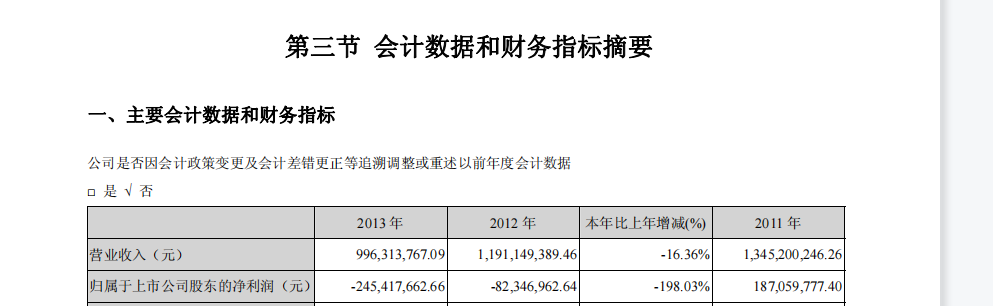

此处仅放上绘图结果
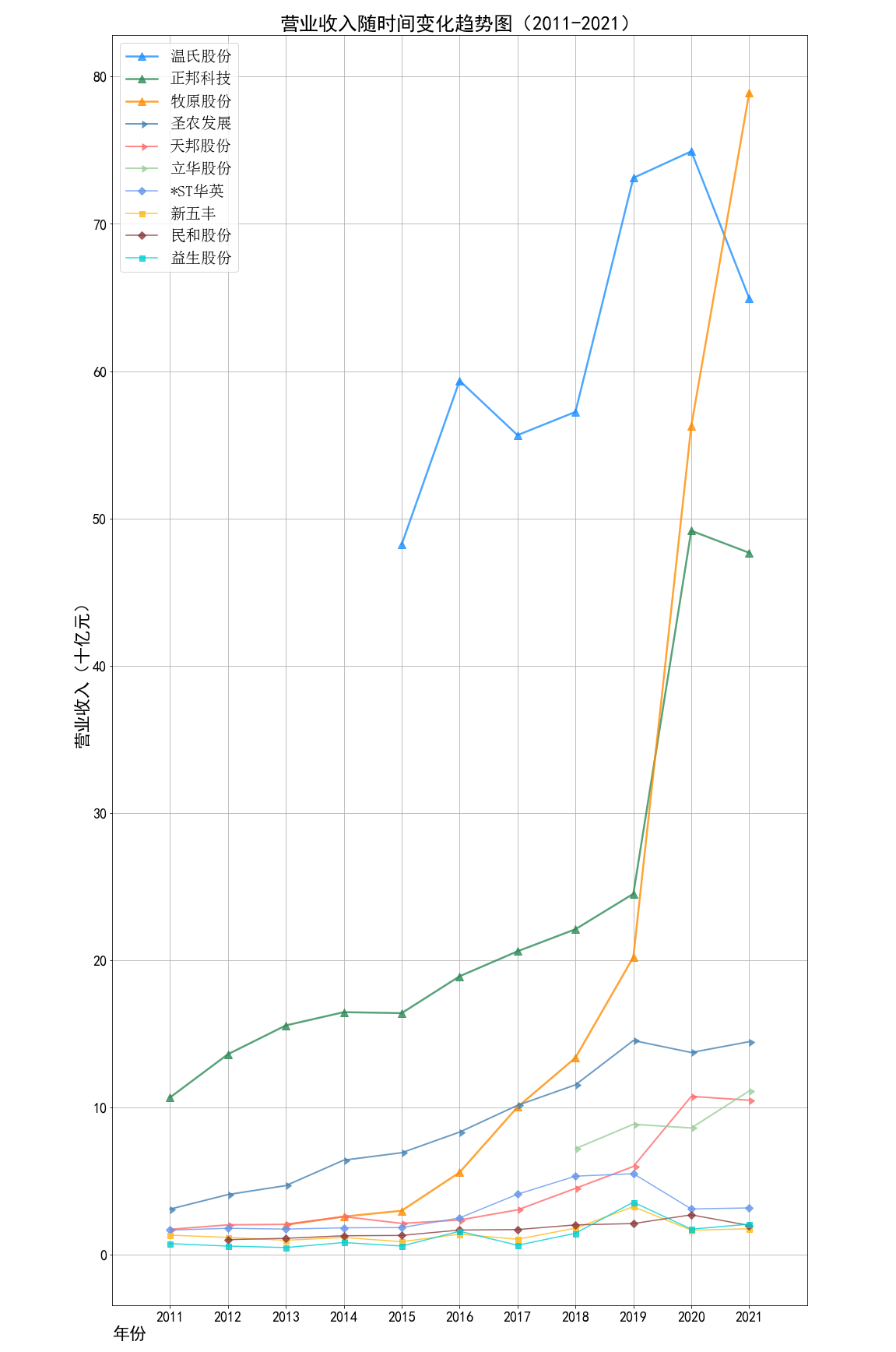

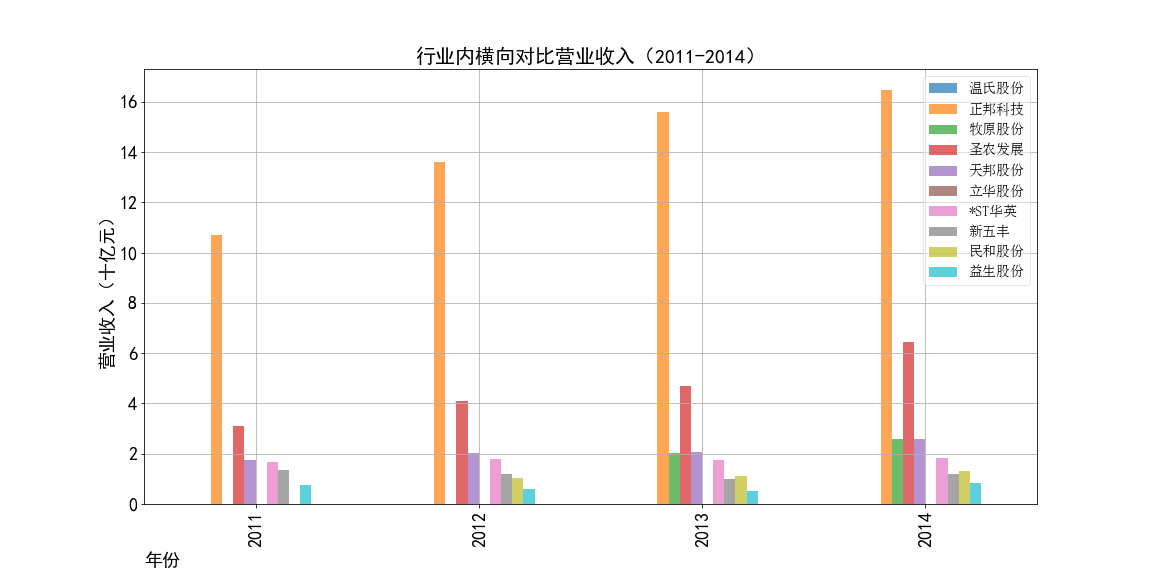
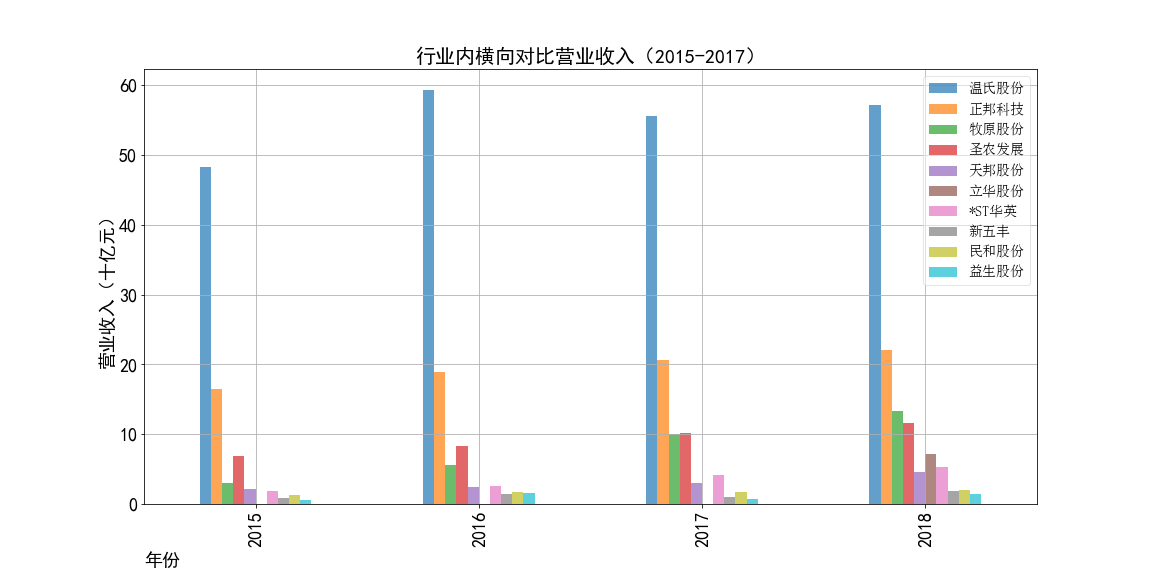
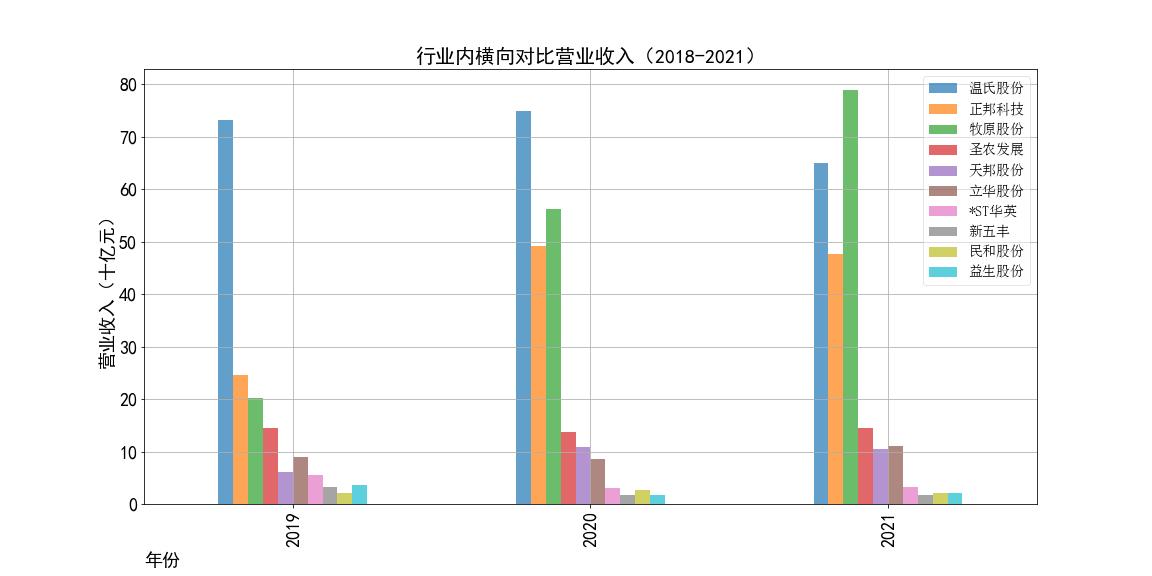
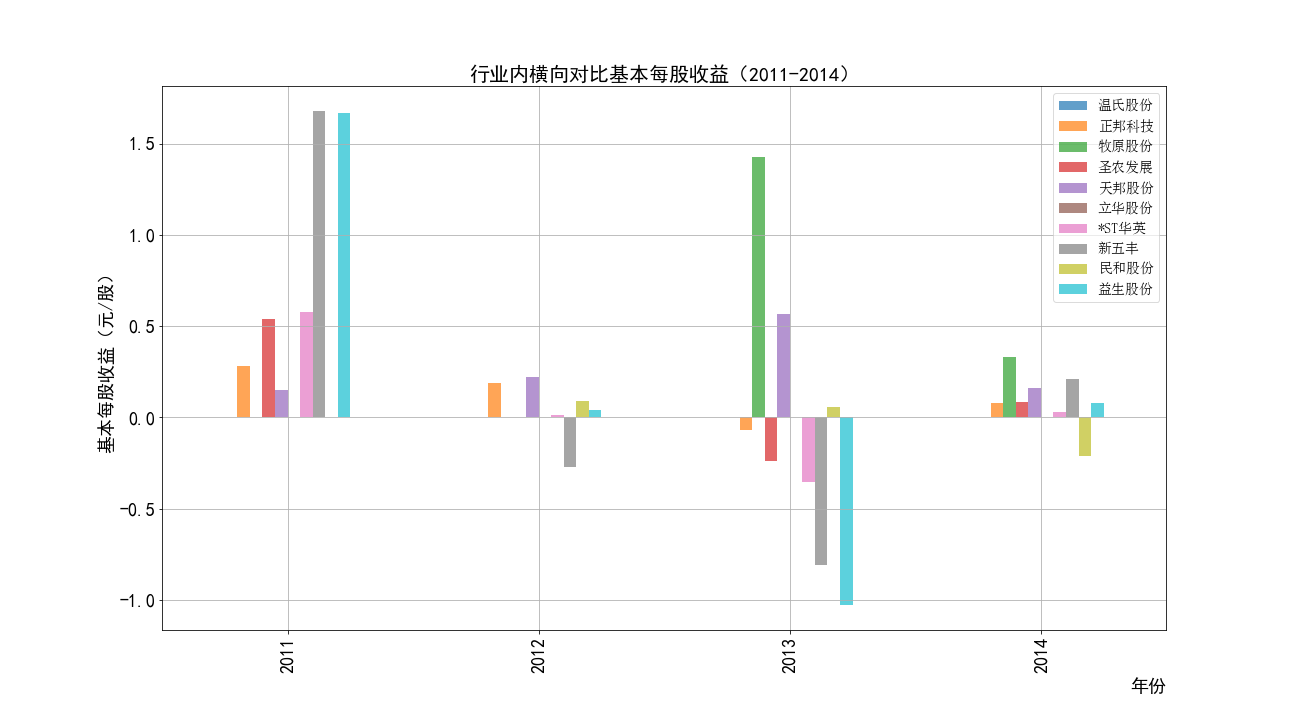
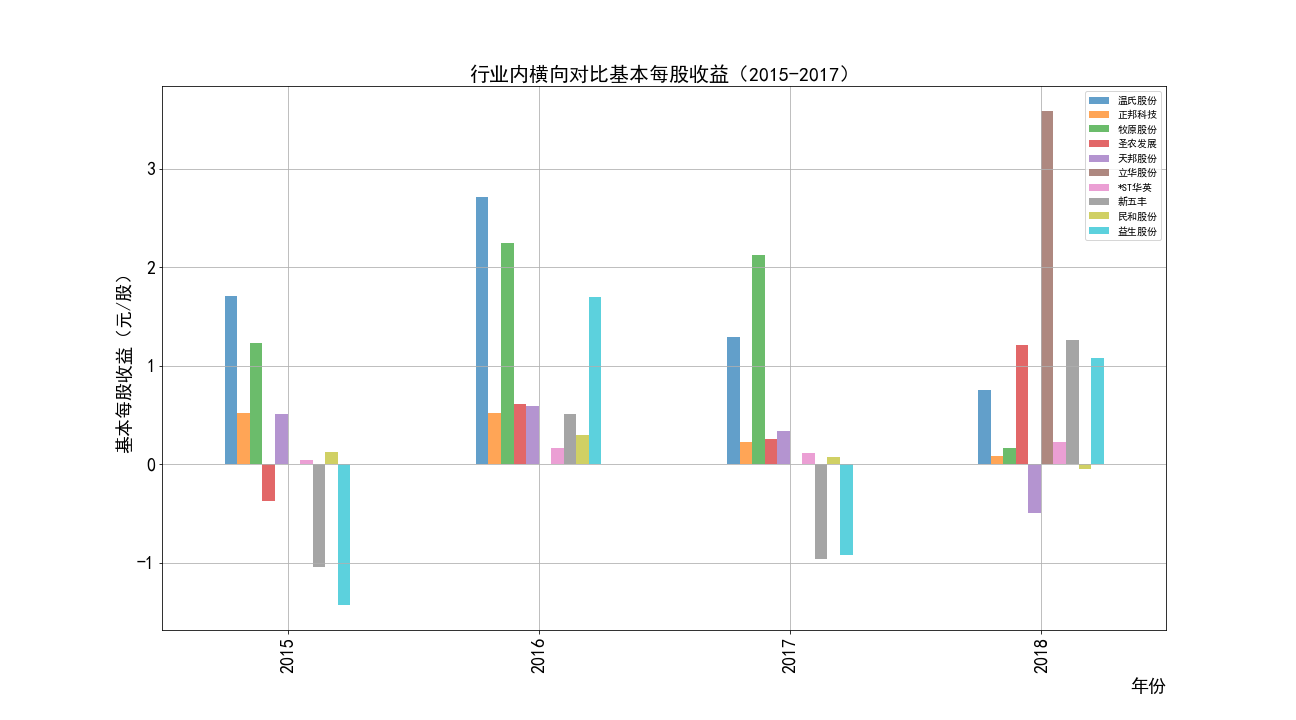
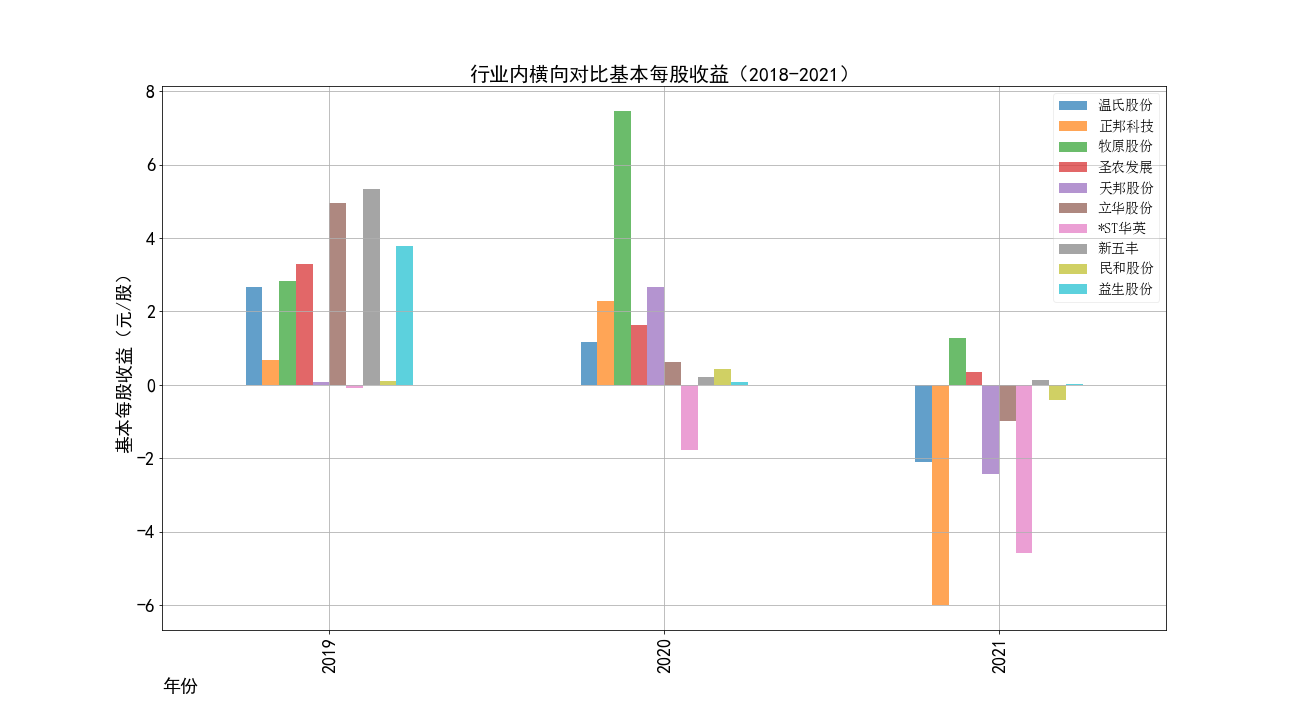
根据营业收入随时间变化的趋势图,目前畜牧业的第一梯队公司当属正邦科技,温氏股份和牧原股份。
在2011-2014年,正邦科技一直处于总营业收入第一的地位,规模最大。正邦集团的主要业务是猪和鸭的饲养、加工和销售,
自身有完整的产业链,同时开展饲料,兽药的制造业务。此外,正邦集团还发展农业种植,生产米面粮油,与自身的畜牧业务良好配合,多途径创造收益。
2015年温氏股份上市,上市第一年就创下了逼近500亿元的总营业收入。刷新了行业记录,
并一直保持畜牧业的总营收第一的位置到2020年。温氏食品集团股份有限公司(简称“温氏股份”),创立于1983年,
现已发展成一家以畜禽养殖为主业、配套相关业务的跨地区现代农牧企业集团。
温氏食品属于温氏股份旗下食品业务的母品牌,其涵盖集团旗下所有食品版块业务,以猪、鸡、鸭、奶、蛋、鸽
等的养殖、加工、销售为业务范畴,是温氏旗下现有和未来食品类子品牌的共有母品牌。作为一家畜牧业公司温氏集团
并不只是养殖各种禽类再卖给下游买家,而是自己研发品牌,加工原料,直接与市场和消费者对接。集团自己拥有
完整的产业链,拥有多个著名子品牌,实力雄厚,发展前景光明。温氏股份现为农业产业化国家重点龙头企业、创新型企业,也是重点科研平台。
2015年以后牧原股份的发展也开始迅猛提速,并在2021年超过温氏股份拿到了行业总营收第一的位置。牧原股份建立了集饲料加工、
生猪育种、种猪扩繁、商品猪饲养、生猪屠宰为一体的完整封闭式生猪产业链。不同于前两所龙头公司,牧原股份专注于生猪的养殖和繁育,不参与下游的加工和
销售部分。从官方网站上我们也可以看到,牧原股份的网站风格简约,内容较少。不像前两所直接面对消费者的公司,会宣传公司的历史、事迹和食品品牌,
牧原股份的官网只罗列了他们的种猪繁育和养殖技术,以及公司的架构和内部待遇。
借助近几年来生猪市场的火爆,猪肉价格高居不下,牧原股份发展迅速。
牧原股份19-20年总营收上涨了约360亿元,同比增长178.31%;20-21年总营收上涨了近226亿元,同比增长40.18%。
牧原股份在其2020年年报中也解释到:受非洲猪瘟的疫情影响,报告期内生猪市场供应偏紧,生猪销售价格维持高位波动,
比上年同期涨幅较大;同时随着公司前期建设的产能逐步释放,出栏量比上年同期显著增长。两点共同影响促进了业绩的变动。
并且牧原股份的智能化、标准化养猪管理进一步控制了成本。2020年实现净利润303.75亿元,同比增长379.37%
畜牧业的第二梯队由圣农发展,立华股份,天邦股份构成。这三家公司都是近年总营收稳定在百亿左右的三家企业。
圣农发展专注鸡的养殖和加工,立华股份则发展各种禽类的养殖和加工。天邦股份专注种猪的繁殖培育,同时经营出售生鲜食品。
前两个梯队的公司大多规模较大,有一定的抗风险能力,发展速度快,营业收入稳定上升,收入一般没有较大降幅。
第三梯队的公司有*ST华英,新五丰、民和股份和益生股份。到了第三梯队,四家公司的总营收基本处于50亿元以下,都是2011年就已经上市的公司
但是近十年发展速度缓慢,抗风险能力较弱,有的年份收入降幅很大。如*ST华英、益生股份,民和股份在2020年的总营收均同比下降了约50%。
根据每年的柱状对比图,我们可以更加直观地看到正邦科技、温氏股份分别统领了两个时期,并且它们在自己的时代都遥遥处于行业领先地位,大体量领先其他的公司。
而后牧原股份奋起直追,直到超越温氏股份成为行业第一,但是二者实力不相上下,未来行业龙头是谁还有待观察。
根据每股收益随时间趋势变化图,可以观察到畜牧业的企业盈利能力很不稳定——大部分公司每股收益随时间变化的图像大致沿x轴对称,
并且随着时间上下波动。经常出现一年盈利一年亏损的状况。各公司的极差都很大。同时有规模越大的公司波动越大的特征。
考虑到畜牧业的发展受多种自然因素影响,如猪瘟,禽流感。肉类价格受多种因素影响,波动大。
同时养殖所耗费的成本大,动物的生长周期长,容易跟不上市场的变化导致产能过剩。行业利润波动剧烈也比较正常。
2021年受新冠疫情冲击以及饲料成本上升等因素影响,畜牧业有大量公司都处于亏损状态。
根据2021年每股收益柱状图,每股收益为负数的公司有5家(在前十家公司中),这是近十年来前十家公司中最多公司亏损的一年。并且除了牧原股份外的其余四家公司的每股收益虽然为正,但也十分微薄。
就连营业收入在2021年位于第三的正邦科技,其2021年每股收益也跌到了-6(元/股)之多。2021年巨额的亏损是预兆。果然,2022年6月8日正邦股份发出一份公告,称
,公司出现部分商票逾期未兑付的情形,合计约5.4亿元,而这可能只是其债务的冰山一角。💸
*ST华英一直都在贴着x轴轻微波动,但在2018年以后,每股收益已经连续下跌三年,其中2018,2019年的每股收益都为负数,故已被归为特殊处理股票,有退市风险。2021年已经跌
跌到-4.58(元/股),位列该年倒数第二。
牧原股份上市以来每股收益都为正数,未曾亏损,2021年也是逆势创造了营业收入的新高,但是其2021年的每股收益由7.46(元/股)暴跌至1.28(元/股),缩水82.8%。这也应证了2021年畜牧业成本上升的情况。
本次实验一开始对于匹配公司历年数据采取的方法是先匹配每份年报的目录,根据目录定位财务指标所在章节,然后用pdfplumber提取对应页面的表格然后根据关键字匹配数据。 但是这种方法在实践中遇到了诸多困难:

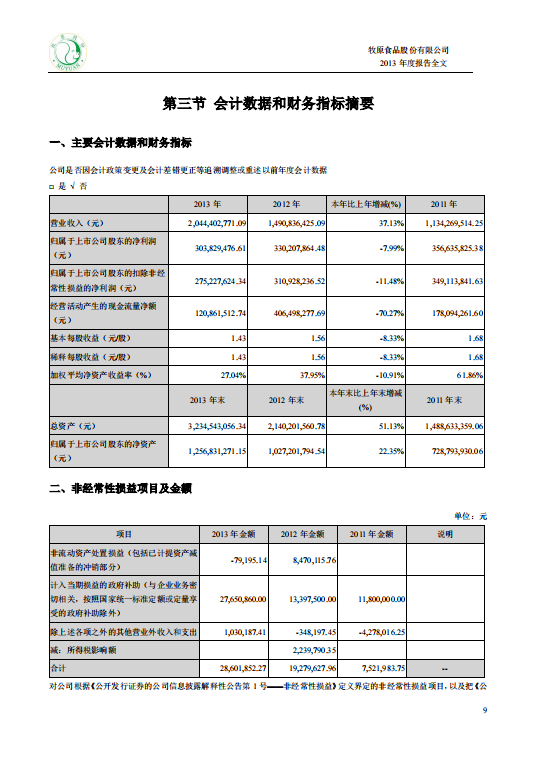 错误示例:页码是下一节的内容。目录写第二节“公司简介和主要财务指标”在第12页,实际上第12页是第三节
错误示例:页码是下一节的内容。目录写第二节“公司简介和主要财务指标”在第12页,实际上第12页是第三节


 虽然这些问题在你有一双勤奋的双手和充足的时间时都不算事儿——遇到个性的标题就取布尔值并集然后用df.loc筛选;目录加粗了我就手动把目录删掉再添一个不加粗的。页码不对我就看运行报错的公司年份
修改页码后再继续运行,到后面我发现报错的频率实在是太高了,然后就每处理一个公司前先打开他所有的年报文件,一年一年改正页码再跑。
对于pdfplumber在表格换行时匹配不到准确的数据,后来我发现这样匹配的都是距上年变动的百分比,于是就用上一年度数据进行计算得到本年数据。
虽然这些问题在你有一双勤奋的双手和充足的时间时都不算事儿——遇到个性的标题就取布尔值并集然后用df.loc筛选;目录加粗了我就手动把目录删掉再添一个不加粗的。页码不对我就看运行报错的公司年份
修改页码后再继续运行,到后面我发现报错的频率实在是太高了,然后就每处理一个公司前先打开他所有的年报文件,一年一年改正页码再跑。
对于pdfplumber在表格换行时匹配不到准确的数据,后来我发现这样匹配的都是距上年变动的百分比,于是就用上一年度数据进行计算得到本年数据。
import pandas as pd
import pdfplumber
import fitz
import re
Company=pd.read_csv('company.csv').iloc[:,1:]
company=Company.iloc[:,0].tolist()
t=0
for com in company:
t+=1
df = pd.read_csv(com+'.csv',converters={'证券代码':str})
df = df.sort_index(ascending=False)
final = pd.DataFrame(index=range(2011,2022),columns=['营业收入(元)','基本每股收益(元/股)'])
final.index.name='年份'
code = str(df.iloc[0,1])
name = df.iloc[-1,2]
name=name.replace('*','').replace(' ','')
for i in range(len(df)):
title=df.iloc[i,3]
doc = fitz.open('./%s/%s.pdf'%(com,title))
text=''
for j in range(8):
page = doc[j]
text += page.get_text()
p_year=re.compile('(\d{4}) .*?年度报告',re.DOTALL)
p=re.compile(r'(?<=\n)(第?\w{1,2}、?节?章?)\s*([\w、]*).*?(\d+).*?(?=\n)'
,re.DOTALL)
result = p.findall(text)
year = int(p_year.findall(text)[0])
catalog = pd.DataFrame({'节数':[t[0] for t in result ],
'标题':[t[1] for t in result],
'页码':[t[2] for t in result]})
pdf =pdfplumber.open('./%s/%s.pdf'%(com,title))
A='公司简介和主要财务指标'
B='会计数据和业务数据摘要'
C='会计数据和财务指标摘要'
a=catalog['标题']==A
b=catalog['标题']==B
c=catalog['标题']==C
page=int(catalog.loc[a|b|c].iloc[0,2])
lst=[]
lst1=[]
data=[]
Data=[]
Search=['营业收入','营业收入(元)','营业总收入','营业总收入(元)'
,'基本每股收益(元/股)','基本每股收益(元/股)','基本每股收益(元/']
Search1=['办公地址','公司办公地址','公司网址','公司国际互联网网址',]
if year==2011 :
data=''
for x in range(page-1,page+2):
data =data+pdf.pages[x].extract_text()
p_rev = re.compile('(?<=\n)(营业)总?收入(?\w?)?\s*([-\d+,.]*).*?')
p_eps = re.compile('(?<=\n)(基本每股收益(元/*/?股))\s*([-\d+,.]*)\s*')
lst = [p_rev.findall(data)[0],p_eps.findall(data)[0]]
elif year>=2015: #2015年及以后,当前节包含公司简介,多获取一页
for z in range(page-1,page+2):
data =data+pdf.pages[z].extract_tables()
else:
for y in range(page-1,page+1):
data =data+pdf.pages[y].extract_tables()
for i in range(len(data)):
Data +=data[i]
for row in Data:
row=[i for i in row if (i!='')&(i!=None)]
row=[i.replace('\n','') for i in row]
if row==[]:
continue
elif row[0] in Search:
lst.append(row)
elif row[0] in Search1:
lst1.append(row)
if len(lst)>4:
del lst[4:]
revenue=lst[0][1]
if len(revenue)<=7:
revenue=(float(revenue.strip('%'))/100+1)*float(final.loc[year-1,'营业收入(元)'])
revenue=str(round(revenue,2))
else:
revenue=float(revenue.replace(',',''))
eps=lst[1][1]
final.loc[year,'营业收入(元)']=revenue
final.loc[year,'基本每股收益(元/股)']=eps
final.to_csv('【%s】.csv' %name,encoding='utf-8-sig')
site=lst1[0][1]
p=re.compile('[a-zA-Z./*]+')
WEB=[ p.findall(item[1]) for item in lst1]
WEB=[ t for t in WEB if t!=[]]
web=re.sub("\[|'|\]",'',str([t for t in WEB if len(str(t))>=10]))
web=web.replace(', ','.')
with open('【%s】.csv'%name,'a',encoding='utf-8-sig') as f:
content='股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name,code,site,web)
f.write(content)
print(name+'数据已保存完毕'+'(',t,'/',len(company),')')
第一次系统地用python完成较为复杂的任务,涉及数据筛选,爬虫,绘图等内容。尤其强化了正则表达式和爬虫的学习,
收获颇丰,也领会了这两个工具的实用性。须知代码还是得常敲常新,遇到困难善用搜索,提高自学能力。编程中遇到问题可以试着
转变思路换方法,不要在一条路上死磕,提高自己的思维能力,不能所有问题都想着手动调整数据解决。
感谢吴老师的悉心教导,本学期的课程内容框架清晰,内容严谨丰富,让我系统地学习了python对于数据处理的知识。特别是扩展的关于工作目录,环境变量的知识,解决了之前学习python
时令人疑惑的问题。
布置的几次作业难度递进,衔接流畅,能很好地锻炼到所学知识。希望未来有更多锻炼代码的机会,不负所学,探索python的更多用法。
代码中年报爬取下载部分为作业三小组共同完成,其他部分代码为独立完成。
报告很长,感谢你看到这!初版代码上传时间较早,目前更新了部分内容,如发现问题/需探讨交流欢迎联系我😼